
【2020年3月9日掲載】KubeCon + CloudNativeCon North America 2019 Report

こんにちは。ブロードバンドタワー開発チームの橋本とCloud&SDN研究所の岩本です。 私たちは、2019年11月18-21日に北アメリカ・サンディエゴで開催された KubeCon + CloudNativeCon North America 2019(kubecon)に参加して来ました。
参加の目的としては、少人数で構成される開発チームの開発サイクルの高速化や運用コストの削減を実現、より良いサービスにつなげるために最新の技術動向を把握するためとなります。
ほとんどのセッションの動画と資料がインターネットに公開されているので、参加できなかった人・興味がある人はぜひ見てください。資料に関してはスケジュールからセッションごとの資料を参照できます。
[動画] [資料]
今回は、参加したセッションのうち以下のテーマについて報告いたします。
マルチクラウド
CI/CD
ベアメタルサーバ管理
Multiple Networks


kubecon + CloudNativeConとは?
Cloud Native Computing Foundation(CNCF)によって開催されるkubernetesを中心にクラウドネイティブな技術をテーマにしたカンファレンスです。年3回、ヨーロッパ・中国・北アメリカで開催されています。
今回の来場者数は12,000人と規模が大きいカンファレンスでした。3つのkubeconの中でも来場者数からもわかるように北アメリカが一番大きいカンファレンスとなっています。kubeconは2015年から始まり、ついに年間で2万を突破しました。
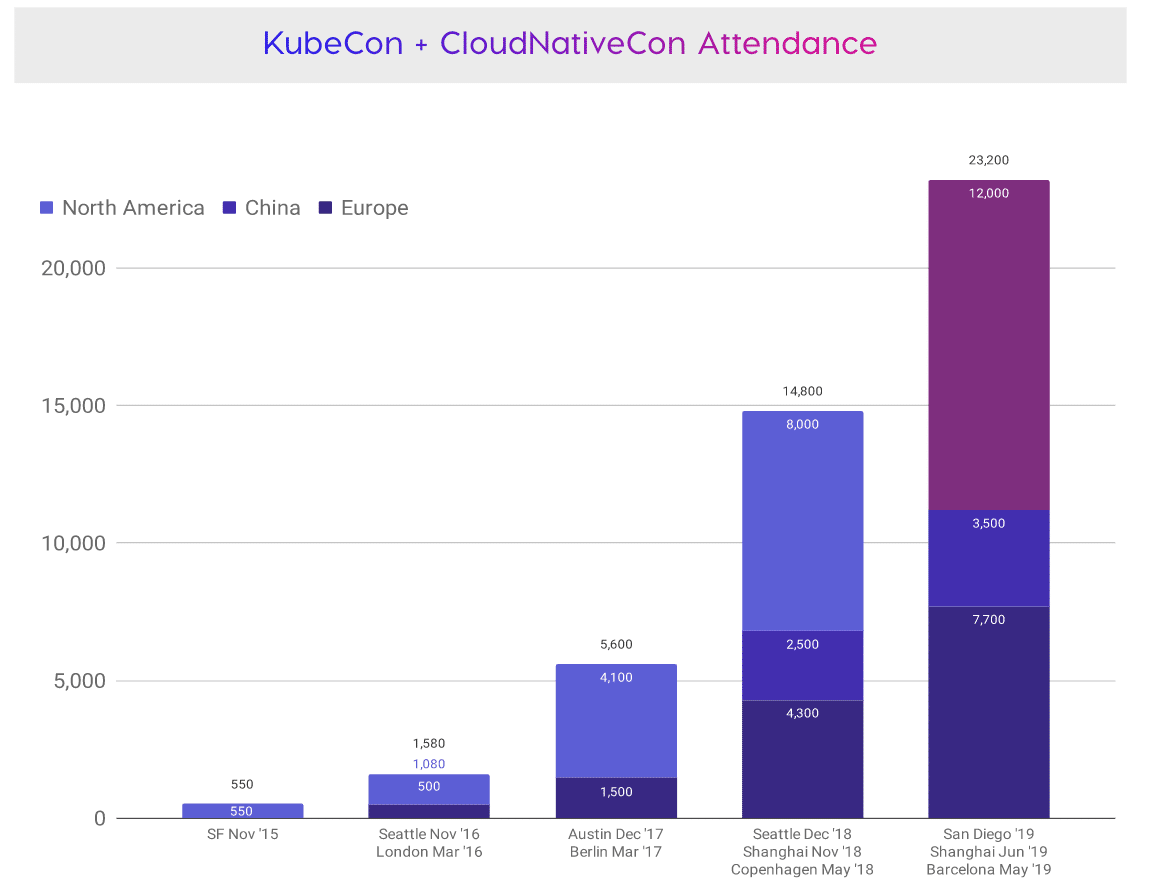
2020年は以下の日程で開催されます。
MultiCloudCon
kubecon自体は19日から開催されますが、18日にCo-Located Eventsが開催されました。この日は、CNCFやAWS、Google Cloudなど様々な企業や団体によって34個のカンファレンスやワークショップが開催されました。
[DAY ZERO CO-LOCATED EVENTS]
[動画]
今回の参加目的とはあまり関係ないところですが、個人的に興味があったためMultiCloudConに参加しました。
MultiCloudConはUpboundとGitLabによって開催され、マルチクラウドの概要や成熟度モデル、アプリケーションのCI/CDのデモ、マルチクラウドコントロールプレーン、分散データベースの紹介がありました。
今回は、マルチクラウドの成熟度モデルの概要とマルチクラウドコントロールプレーン、分散データベースについて紹介します。
マルチクラウドの成熟度モデル
セッション名:Opening Keynote: The Multicloud Maturity Model
[動画]
[資料]
最初にマルチクラウドの成熟度モデルが紹介されました。
その概要を記載します。
初期は、1つのクラウドで完結させる状態から始まり、最終的には複数のクラウドでデータを持ち、どこからでも同じデータにアクセスできる状態になります。
Monocloud
全てのアプリケーションが1つのクラウドで実行されるNo portability
クラウドに依存したDevOpsプロセス
チームがそれぞれ異なるクラウドを利用していることで、チーム間の連携が取りにくいWorkflow portability
クラウドに依存しないDevOpsプロセスApplication portability
クラウド特有のサービスを使わず、どこのクラウドでもアプリケーションを実行できるDisaster recovery (DR) portability
アプリケーションが限られたダウンタイムで別のクラウドにフェイルオーバーできるWorkload portability
アプリケーションは複数のクラウド間でワークロードを動的にシフトできるData portability
複数のクラウドでデータの変更が行われる
マルチクラウドコントロールプレーン
セッション名:Opening Up the Cloud with Crossplane
[資料]
[動画]
セッションの一つに、マルチクラウドコントロールプレーンであるCrossplaneの紹介がありました。
Crossplaneを利用するとkubernetesを通して、マルチクラスター・マルチリージョン・マルチクラウド・各クラウドプロバイダーのマネージドサービス・サードパーティのクラウドサービスが一元管理できるようになります。
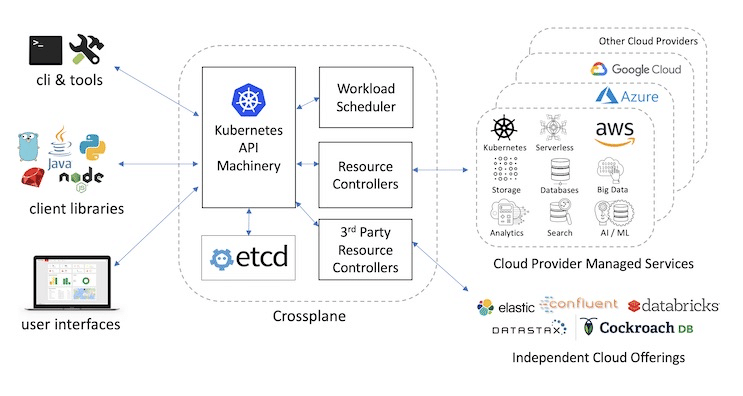
Crossplaneの概要は以下のようになります。
Rookを開発したUpboundがリリース(現version0.7)
kubernetes APIで宣言的に記述できる
関心の分離を意識した設計
運用者はインフラを管理
開発者はアプリケーションを管理
現時点でサポートしているクラウドプロバイダー
GCP
Azure
AWS
GCP・Azure・AWSでサポートしている機能は以下のようです。
マネージドサービス
データベース
キャッシュ
バケット
マネージドクラスタ
GKE / AKS / EKS
ネットワーク周り
サブネット
ネットワーク
ファイアウォール
今後、上記機能について機能を充実させて行くようです。
また、追加実装される機能は以下のようです。
クラウドDNSサービス
ビッグデータサービス
機械学習サービス
ロードバランサーサービス
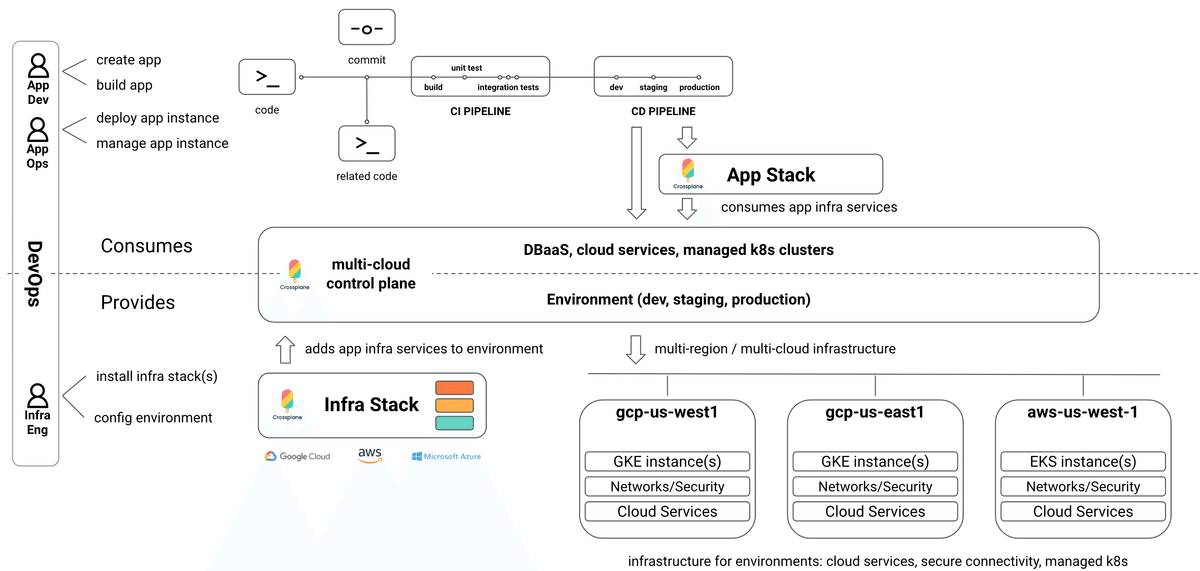
関心の分離を意識した設計となっているためアーキテクチャは下の図になります。
開発者は、デプロイ先のクラウドプロバイダーやリージョン、使いたいリソース(データベースやキャッシュ)を指定してデプロイします。運用者は、ネットワークやファイアウォール等のプロビジョニングを行います。
下のコードは、Google CloudのCloud SQLをプロビジョニングするマニフェストの例です。使用したいサービスとリージョン等を記述するだけでマネージドサービスをプロビジョニングできるようです。
apiVersion: database.gcp.crossplane.io/v1beta1
kind: CloudSQLInstance
metadata:
name: example-cloudsql-instance
spec:
providerRef:
name: example-provider
writeConnectionSecretToRef:
name: example-cloudsql-connection-details
namespace: crossplane-system
forProvider:
databaseVersion: MYSQL_5_6
region: us-west2
settings:
tier: db-n1-standard-1
dataDiskType: PD_SSD
dataDiskSizeGb: 10
ipConfiguration:
ipv4Enabled: true
Crossplaneのようなコントロールプレーンが登場したことで、各クラウドプロバイダーの違いをあまり意識せず使えるようになり、次に紹介するデータベースもマルチクラウドへ対応して来ているので、マルチクラウドへのハードルが1つ下がったのではないでしょうか。
マルチクラウド時代のデータベース
セッション名:Completing the multicloud maturity model with distributed databases
[動画]
[資料]
マルチクラウド時代のデータベースについて紹介します。
アプリケーションをマルチクラウド化するメリットとしては、地理的に離れた拠点にアプリケーションを配置することで、低遅延な通信を実現し、耐障害性の向上があります。しかし、マルチクラウドでアプリケーションのデプロイを考えると真っ先に悩むのがデータベースやストレージだと思います。難しいところとして、複数のクラウドにあるデータベースやストレージの同期やバックアップをどうするか、使い方や仕様が異なるクラウドを複数管理する必要があります。
このような課題を解決するために、CrossplaneのようなコントロールプレーンやRookというクラウドネイティブなストレージのオーケストレータ、分散データベースが開発されています。
マルチクラウド時代のデータベースのアーキテクチャ
マルチクラウド時代のデータベースの要求として、アプリケーションからの要求とクラウドからの要求があります。
アプリケーションからの要求
Relations & Transactions
Massively Scalable。水平方向へのスケーラビリティ
マイクロサービス化により、大規模なスケーラビリティが求められる
マルチクラウドからの要求
耐障害性
地理的な分散配置
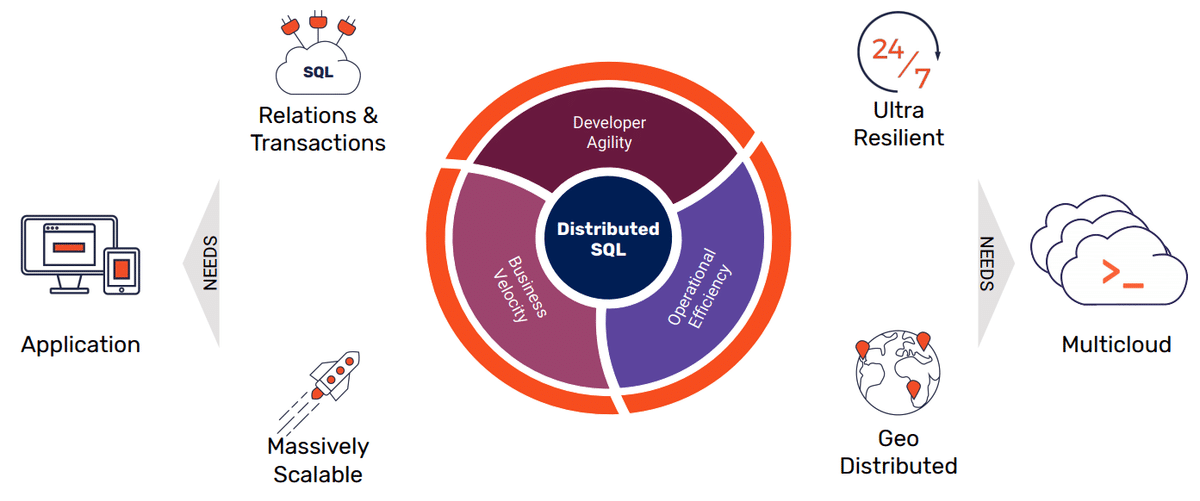
また、マルチクラウドの成熟度モデルは以下の図になります。
レベル1、2は今でもよく見る状態だと思います。レベル3は障害時に別のクラウドにフェイルオーバーできる状態です。レベル4はどのクラウドにアクセスしても同じ結果を得られる状態で、yugabyteDBとCrossplaneを使うことで達成できると説明していました。
分散データベース
マルチクラウド時代のデータベースとして代表的なツールに以下のツールがあります。
全てに共通して言えるのは、NoSQLのようなスケーラビリティとMySQLのようなACID特性の両方の特徴を持っていることです。これまでのデータベースは、CAPの定理により可用性・一貫性・分断耐性のどれか2つを担保しようとすると、残った1つの要素が犠牲になってしまうとされていました。ですが、マルチクラウド時代のデータベースは一貫性とスケーラビリティ・可用性を持ちかつ可用性も担保しています。
Vitess [github.com] (CNCF Project; graduated)
水平スケール可能なMySQLクラスタの管理ツール
コネクションプールの多重化やクエリの重複排除によるパフォーマンスの最適化
クエリのフィルタやユーザ毎のテーブルのアクセス制限
垂直・水平シャーディングのサポートやシームレスな動的再シャーディング
PostgreSQLのAPIと互換性がある
SQL JOINが可能、分散トランザクション
自己修復、一貫性、同期レプリケーション
自動シャーディングと自動リバランス
PostgreSQLのほとんどの機能と互換性がある
クラウド間でのゼロダウンタイムマイグレーション
自動ローリングアップデート
毎日のバックアップと毎時の増分バックアップ、自動データコピー
CI/CD
セッション名:Leveling Up Your CD: Unlocking Progressive Delivery on Kubernetes
開発チームの継続的デリバリ(Continuous Delivery: CD)周りを強化したいと思い、CDのセッションに参加したのでその報告となります。
このセッションでは、機械学習やアルゴリズムによる解析・分析を組み込める高度なCDの手法を紹介していました。
従来のCDでは、開発からデプロイまでの自動化を図ることで高速なデプロイを実現していましたが、アプリの変更後に問題が発生し、常に信頼性があるとは言い切れませんでした。

そのため、アプリケーションのデプロイの速さと信頼性の両方を得るために、Progressive Deliveryという手法をとります。
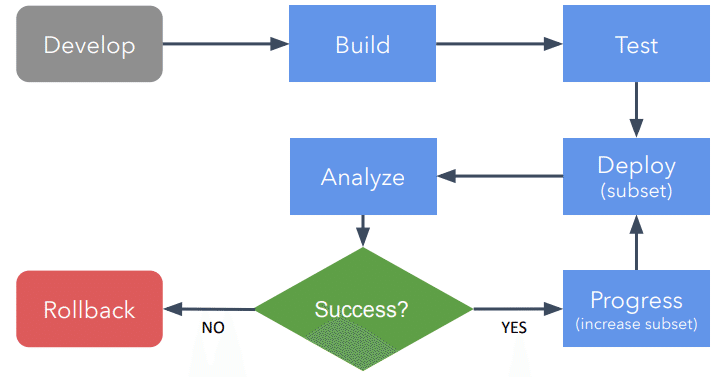
Progressive Deliveryは以下の流れで行われます。テストまでは従来の仕組みと変わらず、テスト後の流れが以下のように変わります。
カナリアリリースのように小さい範囲で新バージョンのアプリケーションをデプロイ
新バーションのアプリのメトリクスを収集
メトリクスを解析し、ロールバックするかを判断
正常動作でないと判断されればロールバック
アプリが正常動作していると判断されれば、新バージョンの範囲を広げる
正常動作しているか判断する時に、機械学習やアルゴリズムによる解析・分析を組み込むことでデプロイの信頼性を担保します。
Argo Rollouts
このProgressive Deliveryを実現する方法の1つとしてArgo Rolloutsを使用したデモがありました。

Argo Rolloutsは、kubernetesにBlue/Greenやカナリアなどのデプロイを提供するツールです。
Argo Rolloutsには分析・解析を可能にするAnalysis CRD、異なる複数バージョンのアプリケーションに対するベンチマークや負荷テストを可能にするExperiment CRDが実装されています。
Analysis CRD
Analysis CRDはデプロイ状況の分析に応じて、デプロイの継続やロールバックを可能にします。
現在、サポートされているメトリクスを測定するためのツールは以下になります。今後は、datadogやNew Relicといったツールへの対応やサービスメッシュやIngress Controllerへの統合を予定しているとのことです。
job
googleとnetflexが共同開発
カナリアリリース分析ツール。OSS
spinnakerに統合されている
スコア計算の基になるメトリクスを設定できる
web (coming)
wavefront (coming)
vmware
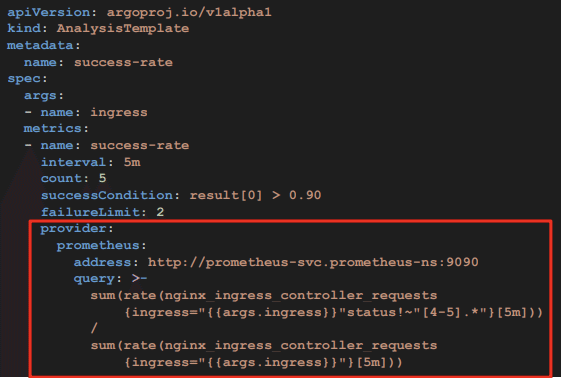
次の図は、デモで使用されたマニフェストファイルです。
prometheusを用いてHTTPリクエストを測定し、成功率を割り出し0.9を閾値としていました。成功率が0.9より大きい場合はデプロイを継続し、0.9以下であればロールバックされます。
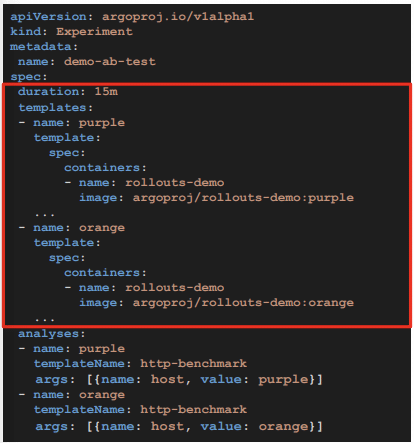
Experiment CRD
Experiment CRDは、指定した時間だけ複数バージョンのアプリケーションをデプロイして、それぞれにベンチマークテストや負荷テストなどを実行でき、A/Bテストやベースラインテストのようなテストが可能になります。
次の図は、デモで使用されたマニフェストファイルです。
デモでは、wrkというhttpベンチマークツールをkubernetesのjobとして実行し、ベンチマークテストを行なっていました。
Multiple Networks
セッション名:Multiple Networks for Kubernetes Workload
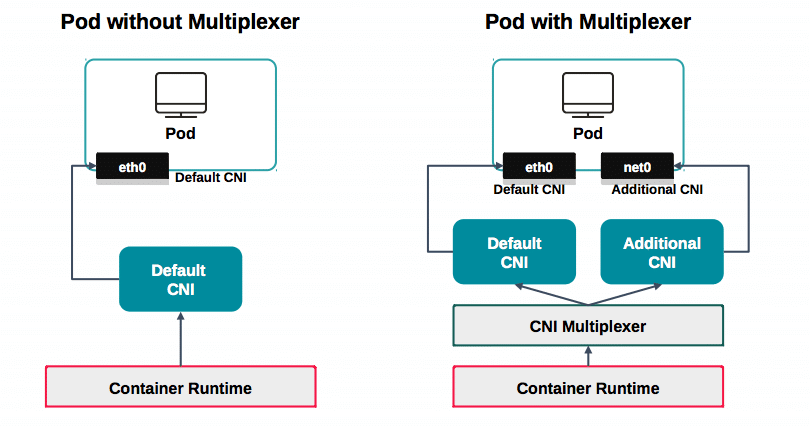
Kubernetesでは1つのNetwork Interface(single IP)しか対応していない事は、使った事がある方はご存知かと思います。
複数のネットワーク・インターフェースを持たせたいといったケースは、パフォーマンスやアプリケーションの要件に応じて多くあると思いますがkubernetes単体では解決できません。
これを解決するために複数のネットワークインターフェースをもたせるプロジェクトが複数のプロジェクトで開発が行われています。
本セッションでは、複数ネットワークを管理できるCNI実装を紹介するセッションでした。
まだ我々内部で検証できていないですが、今後積極的に検証したいと思っております。
方法としては、複数のCNIを多重化するための「CNI Multiplexer」経由しNetwork Interfaceの紐付けを行います。
Multiple Networksは、NetworkPlumbing Working Group(NPWG)にて複数ネットワークをPodに対してどのように、ネットワークを紐付けるかの標準カスタムリソースである「NetworkAttachmentDefinition」を用意しています。
https://github.com/k8snetworkplumbingwg/community
実装には、下記のように複数存在します。
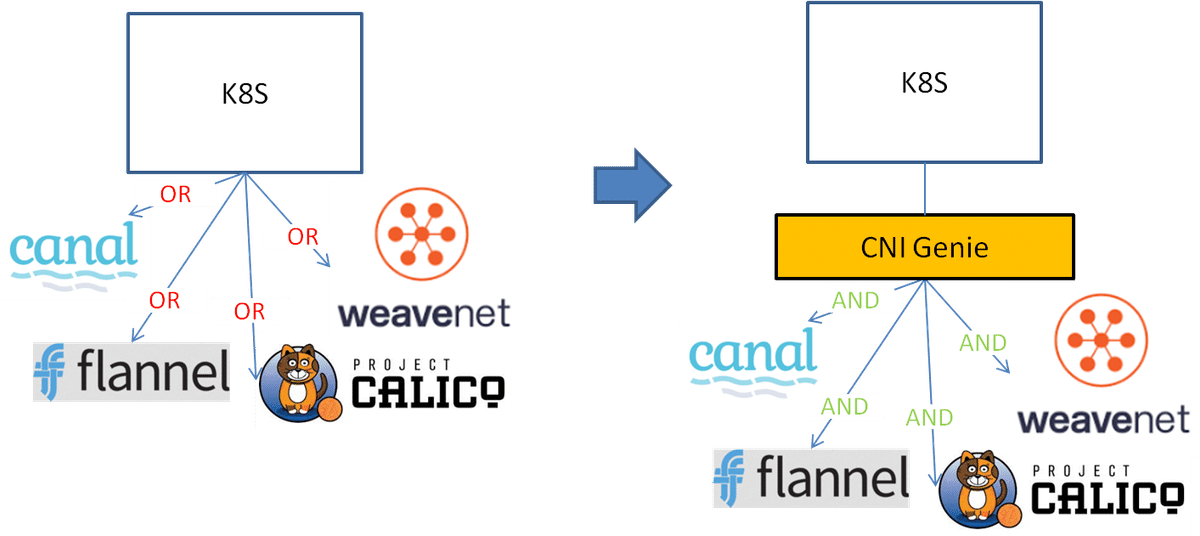
Multus CNI
CNI-Genie
Nokia DANM—yet another approach to multiple networks
Multus CNI
Kubecon2018に参加した際にもセッションがあり、私の中では注目しておりました。
Multusは、Kubernetes Network Plumbing Working Groupが標準化したNetworkAttachmentDefinitionに沿って実装されています。下記は、スライドで示されていた例になります。
apiVersion: "k8s.cni.cncf.io/v1"
kind: NetworkAttachmentDefinition
metadata:
name: macvlan-conf
spec:
config: '{
"cniVersion": "0.3.0",
"type": "macvlan",
"master": "eth0",
"mode": "bridge",
"ipam": {
"type": "host-local",
"subnet": "192.168.1.0/24",
"rangeStart": "192.168.1.200",
"rangeEnd": "192.168.1.216",
"routes": [
{ "dst": "0.0.0.0/0" }
],
"gateway": "192.168.1.1"
}
}'こちらのサンプルのマニフェストでは、カスタムリソースでNetworkAttachmentDefinitionsを指定しspec.configにCNIの設定を記述し、Annotationでnameを参照すれば利用できるそうです。
CNI-GENIE
CNI-GENIEでは、Network Attachment Definistionを使わない方法と使う方法が用意されています。以下は、CNI-GENIEのgithubに上がっている抽象図になります。
CNI-GINIEに関してもサンプルマニフェストがスライドに書かれており、どのように表現するのかを確認する事ができました。
こちらに関しては、annotationで利用するCNIを記述することで指定することができ、CNIの部分が空で定義されている場合にはcAdvisorのデータに応じて適切に選択されます。
apiVersion: v1
kind: Pod
metadata:
name: app-on-multiple-interfaces
annotations:
cni: "flannel,weave"
multi-ip-preferences: |
[
"multi entry": 0,
"ips": {
"": {
"ip": "",
"interface": ""
}
}
]
spec:
...
2つ目の例は、NetworkAttachmentDefinitionを利用する方法で「k8s.v1.cni.cncf.io/networks」から呼び出す事が可能となっています。
apiVersion: v1
kind: Pod
metadata:
name: app-on-multiple-interfaces
annotations:
k8s.v1.cni.cncf.io/networks:
flannel@eth1, customns/weavenet@eth2
k8s.v1.cni.cncf.io/network-status: |-
[
...
]
spec:
...
Nokia DANM
NokiaもMultiple Networkの実装を持っておりDANMという実装があります。「DANM」はどう発音するんだろうと悩む方もいらっしゃるかもしれませんが会場では「DANAM」と発音されていました。
公式のgithubを覗いてみると4年以上の社内実績があるテレコグレードのネットワークマネージャで現在商用で利用されているという記述があり驚きました。また、語源は「Damn, Another Network Manager!」だそうです。
こちらの実装では、NetworkAttachmentDefinitionを用いない実装であり、より抽象的なネットワークの名前として記述することができるようです。https://github.com/nokia/danm
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: test-deployment
namespace: default
spec:
replicas: 1
template:
metadata:
labels: app: test-deployment
annotations:
danm.k8s.io/interfaces: |
[
{"tenantNetwork":"management","ip":"dynamic"},
{"clusterNetwork":"external","ip":"dynamic"},
{"tenantNetwork":"internal", "ip":"dynamic"}
]
spec:
containers:
- name: busybox
image: busybox:latest
args:
- sleep
- "1000"
ベアメタルサーバ管理
セッション名: Introducing Metal^3
kubernetesでは、基本的にコンテナをオーケストレーションすると思われている事が多いですが、kubevirtのようなVMを管理するための機構が追加されそれに加えて、このセッションで紹介されているMetal^3ではベアメタルサーバの管理もkubernetesから管理ができるようになります。これができるとコンテナ,VM,ベアメタルサーバをすべてKubernetesで統合的に管理することができる事になります。
まず、Metal^3の読み方ですが公式文章には「metal cubed」と発音すると書かれています。Metal^3では、OpenStackのIronicが使われておりCRDからIronicを経由して管理ホストを操作することができるとの事です。
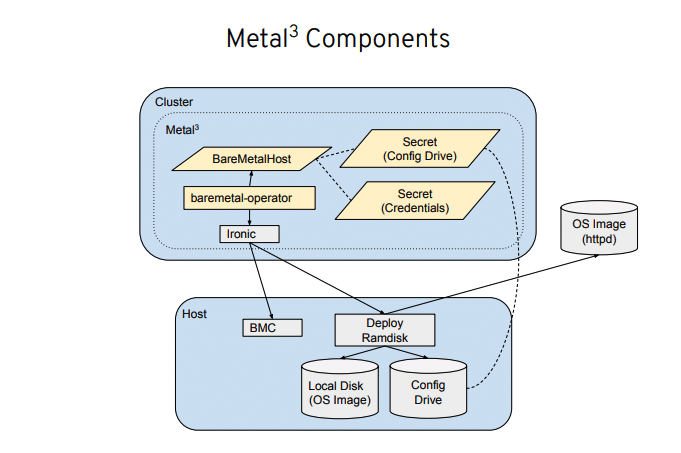
ベアメタルサーバがデプロイされるまでの流れとしては、以下の図のような図の順番で行われます。
Set up Host・・・ホストがコントロールプレーンのネットワークに接続されてネットワーク周りのプロビジョニングが行われる。
Manage Inventory・・・IPMIのクレデンシャル情報とMACアドレス情報を取得する
Create Machines・・・マシン用のCustom Resourceを作成する
Provision・・・Ironicを利用してワーカーホストにOSイメージをインストールしていく。
Operations・・・ノードがクラスタに参加されオペレーション可能になる。

会場では、デモも披露しており実際に動いているところも見ることができました。これができるとCloud Native Conで話されていたような、OpenStackやVMwareといった仮想基盤を管理するためのソフトウェアが必要なくなるようなクラウド基盤が作ることができるのかなと感じることができました。
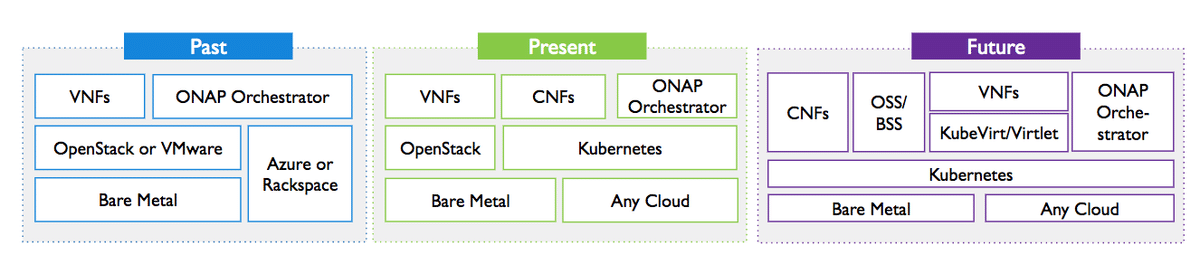
kubeconに参加して
kubernetesを中心にサービスメッシュ、5G、マルチクラウドやハイブリッドクラウドなど多くの分野でものすごい勢いで進化していっていることを実感しました。
ベアメタルサーバや仮想マシンといった部分の管理にも力を入れ始めていることやネットワークに関してもkubernetesに統合され始めていることから、 kubernetesがクラウドのデファクトスタンダードになりつつあるのではと思っています。
これも多くのツールがOSSであることが強みだと思います。
また、MultiCloudConに参加して、マルチクラウドが現実味を帯びてきたように思います。Crossplaneのようなコントロールプレーンが登場し、キャッシュやDB・ストレージといったクラウドサービス、AKS・GKE・EKSのようなマネージドサービスなどあらゆるものが一元管理できるようになっていきます。また、Rookというクラウドネイティブなストレージのオーケストレータやvitessのようなデータベースも開発されています。
CI/CDでは、Progressive Deliveryといった高度なデプロイ手法が登場しました。従来のデプロイ手法に加えて、機械学習やアルゴリズムによる解析・分析をデプロイ時に実行できるようになります。この手法を用いれば、デプロイする前にバグの存在や仕様にある性能を満たしているかなどサービスの品質を容易に検証できるため、ビジネスの価値を落とさずより良いサービスをリリースできるようになります。
またクラウド基盤周りでは、ベアメタルサーバ,VM,コンテナすべてをkubernetes管理できる様になっていくということが見えてきたと思います。これにより、オンプレミス・パブリッククラウドでコンピューティングリソースを分散させても統合管理が容易になり、柔軟なクラウド基盤が作る事ができるのではないかと想像できました。
最後になりますが、kubeconに参加して非常に刺激のあった4日間でした。今回の参加を機に、弊社のサービスがより良い方向へ向かっていけるように引き続き取り組んで行きたいと思います。
ブロードバンドタワーのエンジニアブログ『 Tower of Engineers 』で公開されていた記事をnoteに再投稿させていただきました。
過去(2020年3月9日掲載)のものではありますが、皆様に再び楽しんでいただけると嬉しいです。これからも、価値ある記事や興味深い内容を、noteでシェアさせていただく予定です。どうぞ楽しみにお待ちください。
X(旧Twitter)でも情報を発信しております。ぜひフォローお願いします!
