
盆栽の管理向上をめざして 11:ポスト(旧:ツイート)生け捕り大作戦!

「いらすとや」風の男の子が盆栽とツイッターアイコンを投網で捕まえようとしている様子
画像の評価:
どうも、いらすとやは無視されて、風の男の子になったようだ。ツイッターのアイコンと雲から連想された不思議な鳥が描かれている。
はじめに
前回記事にて、「盆栽管理」データベースに対して、こまごまとした修正を行いました。現時点でやりたいと思っていたことを、とても早く形にすることができました。春の植え替えにも間に合いそうでよかったです。
今回は、予告を行った「ポスト(旧:ツイート)生け捕り大作戦!」を決行致します。巷では「ブルースカイ」の話題をちらほらお聞きします。
私はIT業界の片隅でひっそり暮らしておりますので、この手の情報には晩生で、できることなら皆さんが使い尽くした「枯れた技術」を楽して使っていきたいと思っています。
ただ、今回のテーマはこれからXを卒業し、ブルースカイへ旅立っていく方の引っ越し準備として参考になるのではないでしょうか?
我ながら、タイムリーな話題をご提供できたことをうれしく思います。
思いつく所から始めます
まずは、PCでXのサイトを開き、検索で
from:@P205GTI1904 ←自分のID
と入力します。

さらにクリックすると、そのポストが表示されます。
このときのurlを取得してリスト化できればいいなと思ったのです。

テストしてみました
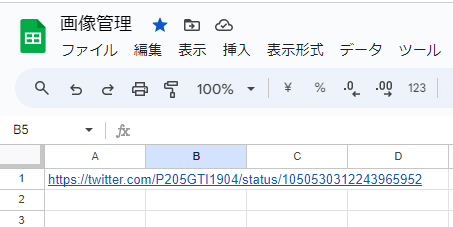
urlをGoogleスプレッドシートに取り込んで、リンクから表示できるか、テストします。

あっさりとできました。使えそうです。
私は2013年にTwitterの登録をしていましたが、本格的に盆栽用アカウントとして使用し始めたのは2018年からです。約5年の間ぽつりぽつりとつぶやき続けていました。
本来であれば、「from:@P205GTI1904」を入力することで、今までのツイートがすべて表示できれば良いのですが、Xの検索機能は制限が掛かっているようです。すべてのツイートが表示されません。
これらのポストの中から有益なものを見つけて登録していくのは、さすがにちょっとしんどいです。
何かよい方法はないものかと考えて試してみたのは、
アーカイブをリクエストすることでした
「設定」の「アカウント」から「データのアーカイブをダウンロード」を選びます。

2段階認証など厳しいチェックの後、ようやく「アーカイブリクエスト」にたどり着けます。
様々な情報から「時間が掛かる」ことを知っていたのですが、数日待っても来ないのでよく見てみると。。。
アーカイブをリクエストしていませんでした!!

「アーカイブをリクエスト」を押し、「アーカイブをリクエスト中」にします。1日半待って、ようやく返事がありました。

「ダウンロード」のページに飛びます。

「アーカイブのダウンロード」が表示されています。

早速ダウンロードします。
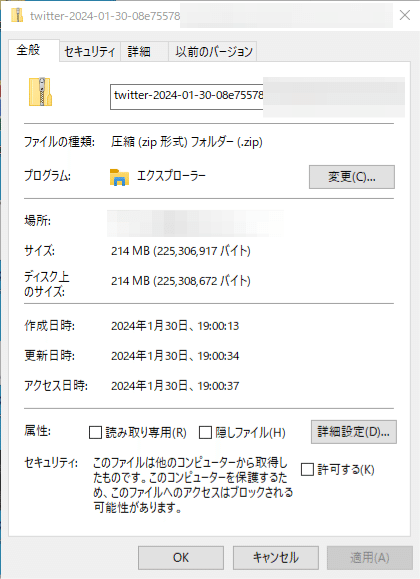
ギガ越えかとも思いましたが、214MB。かわいいものです。
解凍してみました。
「Your archve.html」をダブルクリックします。

「ツイート」をクリックします。

オフラインで今までのツイートを見ることができます。
注目したのは「Twitterで表示」のリンク。
これがあるということは、目的のリンクもそのままアーカイブされているようです。
これはできそう
アーカイブを調べます。
ファイル構造は下記の感じでした。
「data」フォルダを見ています。

「data」フォルダの中に「README.txt」がありました。
ブラウザで開きます。
INTRODUCTION
============
This archive was generated at the request of the following user:
- @username at the time the archive was generated: P205GTI1904
- Account ID: XXXXXXXX
:
右クリックし、「日本語に翻訳」を押します。
最近は、この機能に頼りっぱなしです。まずは機械翻訳の日本語に目を通した後、大意をつかみ、念のため英文にも目を通します。この機能のおかげで、ローカライズされていない情報にもどんどんアプローチしていけるようになりました。
導入
============
このアーカイブは、次のユーザーのリクエストに応じて生成されました。
- アーカイブ生成時の @username: P205GTI1904
- アカウントID: XXXXXXXX
:
内容を読み、今必要と思われる情報を抽出しました。
:
----------------------
tweets.js
This JSON file contains available Tweets which have not been deleted and it includes edited tweets if applicable. Users can edit a tweet up to five times; as such there are up to 5 edited tweets with unique “editTweetIds,” all connected by the “initialTweetID.” The definitions for each of the variables that may be included in any particular Tweet are available in our API documentation: https://developer.twitter.com/en/docs/tweets/post-and-engage/api-reference/post-statuses-update.
----------------------
:
日本語に翻訳します。
:
------------------------
ツイート.js
この JSON ファイルには、削除されていない利用可能なツイートが含まれており、該当する場合は編集されたツイートも含まれます。ユーザーはツイートを最大 5 回まで編集できます。そのため、一意の「editTweetIds」を持つ編集済みツイートが最大 5 つあり、すべて「initialTweetID」で関連付けられています。特定のツイートに含まれる可能性のある各変数の定義は、API ドキュメントで入手できます: https://developer.twitter.com/en/docs/tweets/post-and-engage/api-reference/post-ステータス更新。
------------------------
:
あまり深入りしないことにします。
フォルダの内容をもう少し読みこむと下記のようになりました。
フォルダー パスの一覧: ボリューム XXXXXXXXXXXXX
ボリューム シリアル番号は XXXX-XXXX です
C:.
├─□Your archive.html:HTMLファイル
├─📂assets:HTMLファイル表示用のデータ
│ ├─📁fonts
│ ├─📁images
│ │ └─📁twemoji
│ │ └─📁v
│ │ └─📁latest
│ │ ├─📁72x72
│ │ └─📁svg
│ └─📁js
└─📁data:
├─□README.txt:説明ファイル
├─□tweets.js:ツイートデータ
├─:
├─❑各種jsファイル
├─📁community_tweet_media
├─📁deleted_tweets_media
├─📁direct_messages_group_media
├─📁direct_messages_media
├─📁moments_media
├─📁moments_tweets_media
├─📁profile_media
├─📁tweets_media:ツイートの画像、ビデオ、GIF
├─□aaaa.jpg
├─□bbbb.jpg
:
└─□zzzz.jpg
└─📁twitter_circle_tweet_mediaここまででわかったことは
・アーカイブを手に入れることで、過去の自分のツイートやアップした画像が手に入る。
・現在のurlの情報も手に入る。
ということでした。
ただ、同時にこの内容にはメールアドレスや電話番号などの個人情報も含まれていますので、管理は慎重にする必要があります。
「tweets.js」を見てみました。

今までのツイートの情報が含まれていそうです。
「ボサボサだった」で検索をかけてみると、私の最初のツイートはこんな感じで記録されています。
{
"tweet" : {
"edit_info" : {
"initial" : {
"editTweetIds" : [
"XXXXXXXXXXXXXXXXXX"
],
"editableUntil" : "2018-10-12T00:35:19.005Z",
"editsRemaining" : "5",
"isEditEligible" : true
}
},
"retweeted" : false,
"source" : "<a href=\"http://twitter.com/download/android\" rel=\"nofollow\">Twitter for Android</a>",
"entities" : {
"user_mentions" : [ ],
"urls" : [ ],
"symbols" : [ ],
"media" : [
{
"expanded_url" : "https://twitter.com/P205GTI1904/status/XXXXXXXXXXXXXXXXXX/photo/1",
"indices" : [
"37",
"60"
],
"url" : "https://t.co/BwFLRDQ3Zv",
"media_url" : "http://pbs.twimg.com/media/DpQ7vdGUUAA8gwX.jpg",
"id_str" : "XXXXXXXXXXXXXXXXXX",
"id" : "XXXXXXXXXXXXXXXXXX",
"media_url_https" : "https://pbs.twimg.com/media/DpQ7vdGUUAA8gwX.jpg",
"sizes" : {
"small" : {
"w" : "383",
"h" : "680",
"resize" : "fit"
},
"medium" : {
"w" : "675",
"h" : "1200",
"resize" : "fit"
},
"large" : {
"w" : "1152",
"h" : "2048",
"resize" : "fit"
},
"thumb" : {
"w" : "150",
"h" : "150",
"resize" : "crop"
}
},
"type" : "photo",
"display_url" : "pic.twitter.com/BwFLRDQ3Zv"
}
],
"hashtags" : [ ]
},
"display_text_range" : [
"0",
"60"
],
"favorite_count" : "6",
"id_str" : "XXXXXXXXXXXXXXXXXX",
"truncated" : false,
"retweet_count" : "0",
"id" : "XXXXXXXXXXXXXXXXXX",
"possibly_sensitive" : false,
"created_at" : "Thu Oct 11 23:35:19 +0000 2018",
"favorited" : false,
"full_text" : "ボサボサだったチリメンカズラを剪定しました。もっとかっこよくできるはず。 https://t.co/BwFLRDQ3Zv",
"lang" : "ja",
"extended_entities" : {
"media" : [
{
"expanded_url" : "https://twitter.com/P205GTI1904/status/XXXXXXXXXXXXXXXXXX/photo/1",
"indices" : [
"37",
"60"
],
"url" : "https://t.co/BwFLRDQ3Zv",
"media_url" : "http://pbs.twimg.com/media/DpQ7vdGUUAA8gwX.jpg",
"id_str" : "XXXXXXXXXXXXXXXXXX",
"id" : "XXXXXXXXXXXXXXXXXX",
"media_url_https" : "https://pbs.twimg.com/media/DpQ7vdGUUAA8gwX.jpg",
"sizes" : {
"small" : {
"w" : "383",
"h" : "680",
"resize" : "fit"
},
"medium" : {
"w" : "675",
"h" : "1200",
"resize" : "fit"
},
"large" : {
"w" : "1152",
"h" : "2048",
"resize" : "fit"
},
"thumb" : {
"w" : "150",
"h" : "150",
"resize" : "crop"
}
},
"type" : "photo",
"display_url" : "pic.twitter.com/BwFLRDQ3Zv"
}
]
}
}
},この内容から必要な情報を引き出すことができれば良さそうです。
そろそろ設計に入ります
今回アーカイブファイルを手に入れたことで、今まで投稿した画像の全てをバックアップすることはできています。
なので、今まで手に入れたやり方を使って、画像ファイルをGoogleドライブにアップロードし、ファイルの一覧を取り、keyを割り付けていけば、十分活用できることは見えてきました。
しかし、この方法を取ってしまうと、今後のポストの処理、Googleドライブのサイズ、ポスト後のやり取りなどを見ることはできなくなります。
ここまでくればあともう少し欲張ってみたいと思います。
そこで今回のタイトル
ポスト(旧:ツイート)生け捕り大作戦!
をやってみたいと思いました。
アーカイブファイルから読みだす情報は、ツイートのurlのリストのみにして、リンクをクリックすると、ブラウザでそのツイートが表示されるようにしたい。と考えました。
そうすることで、コメント、いいね、返信など、その他の情報もそのまま「生け捕り」できると考えたのです。
さあどうしましょう?
ぱっと思いつく方法は、JSON型式のデータとしていったん読み込んだのち、画像付きのポストを抽出し、そのurlをGoogleスプレッドシートに列挙する方法です。
TwitterのアーカイブファイルをGASで処理するため、JSON型式で読みこむための関数を書いてください。
Google Apps Script (GAS) を使用して、TwitterのアーカイブファイルをJSON形式で読み込むための関数を以下に示します。
function importTwitterArchive(jsonFile) {
// ファイルからデータを読み込む
var file = DriveApp.getFileById(jsonFile);
var content = file.getBlob().getDataAsString();
// JSONデータをパースする
var jsonData = JSON.parse(content);
// 必要なデータにアクセスする例
var tweets = jsonData.tweets;
// 必要な処理を行う
// 例: ツイートの内容をログに出力する
for (var i = 0; i < tweets.length; i++) {
Logger.log(tweets[i].full_text);
}
}この関数は、TwitterのアーカイブファイルのJSON形式のファイルIDを引数として受け取ります。Google Apps Scriptで実行されるため、Googleドライブのアクセス権限が必要です。また、アーカイブファイル内のデータ構造に合わせてパースする必要があります。上記の例では、ツイートの本文をログに出力するだけの簡単な処理を示していますが、必要に応じてデータを任意の方法で処理できます。
追加で、ファイル名からファイルIDを得る方法も聞きました。
DriveApp を使用する方法:
function getFileIdByName(fileName) {
var files = DriveApp.getFilesByName(fileName);
if (files.hasNext()) {
var file = files.next();
return file.getId();
} else {
return null; // ファイルが見つからない場合はnullを返すか、エラー処理を行う
}
}この関数は、指定されたファイル名に一致するすべてのファイルを取得し、最初のファイルのIDを返します。もし一致するファイルが見つからない場合はnullを返すか、エラー処理を行います。
なるほど、同じファイル名があるかもしれないので、ループを回す必要があるということですね。
確かに、Googleドライブ上でファイルを扱う場合は、ファイルIDでよいような気がしてきました。
とにかく思いつくままテストしました
Googleドライブのフォルダ「盆栽管理」内にフォルダ「Twitterより」を作成しました。その中に「tweets.js」を置き、同じ場所にGoogle Apps Scriptファイル「Tweetの取り込みテスト」を作成しました。
function test() {
var fileName = 'tweets.js';
importTwitterArchive(getFileIdByName(fileName));
}
function getFileIdByName(fileName) {
var files = DriveApp.getFilesByName(fileName);
if (files.hasNext()) {
var file = files.next();
return file.getId();
} else {
return null; // ファイルが見つからない場合はnullを返すか、エラー処理を行う
}
}
function isTargetTweet(tweet) {
//画像があり、返信、リツイートではないものか判定する。
var result = false;
const full_text = tweet.full_text;
if (full_text.substr(0, 2) == "RT") {
result = false;
return result;
}
else if (full_text.substr(0, 1) == "@") {
result = false;
return result;
}
const entities = tweet.entities;
if (typeof entities !== 'undefined') {
if (typeof entities.media !== 'undefined') {
for (let i in entities.media) {
const media = entities.media[i];
if (typeof media.type !== 'undefined') {
if (media.type === 'photo') {
result = true;
return result;
}
}
}
}
}
const extended_entities = tweet.extended_entities;
if (typeof extended_entities !== 'undefined') {
if (typeof extended_entities.media !== 'undefined') {
for (let i in entities.media) {
const media = entities.media[i];
if (typeof media.type !== 'undefined') {
if (media.type === 'photo') {
result = true;
return result;
}
}
}
}
}
return result;
}
function importTwitterArchive(jsonFile) {
// ファイルからデータを読み込む
var file = DriveApp.getFileById(jsonFile);
var content = file.getBlob().getDataAsString();
var content2 = content.replace(/^.*window\.YTD\.tweets\.part0\s*=\s*/, '');
// JSONデータをパースする
var jsonData = JSON.parse(content2);
for (let i in jsonData) {
const tweet = jsonData[i].tweet;
if (isTargetTweet(tweet)) {
Logger.log("[" + i + "]:" + tweet.id);
Logger.log("full_text:" + tweet.full_text);
//twitterのリンクを書き出す。
}
}
}twitterのアーカイブファイルの仕様は時々変わっているようで、ネットで情報を探しても、「tweets.js」に関する情報は出てきません。
JavaScriptの構文を外しました
JSON型式のデータを期待して、読み込ませてみましたが、正しく読めません。よく見ると、
window.YTD.tweets.part0 = [
{
:
}
]となっています。
確かに、ファイルの拡張子が「.js」なので、プログラムファイルになっています。
今欲しいのは、
[
{
:
}
]の形式なので、次のような処理に書き換えました。
// ファイルからデータを読み込む
var file = DriveApp.getFileById(jsonFile);
var content = file.getBlob().getDataAsString();
var content2 = content.replace(/^.*window\.YTD\.tweets\.part0\s*=\s*/, '');
// JSONデータをパースする
var jsonData = JSON.parse(content2);今現在のやり方なのでいつまで使えるかは分かりませんが、ともかくjsonDataを調べればよい状態になりました。
ここから先、日頃JavaScriptを扱っている人にとっては造作ないことだと思いますが、JavaScript、Pythonに慣れていない私は手探りです。
そもそも、変数宣言の自由さがかえって気持ち悪いのです。
といいながらも、何とか手探りで読みだすことができました。
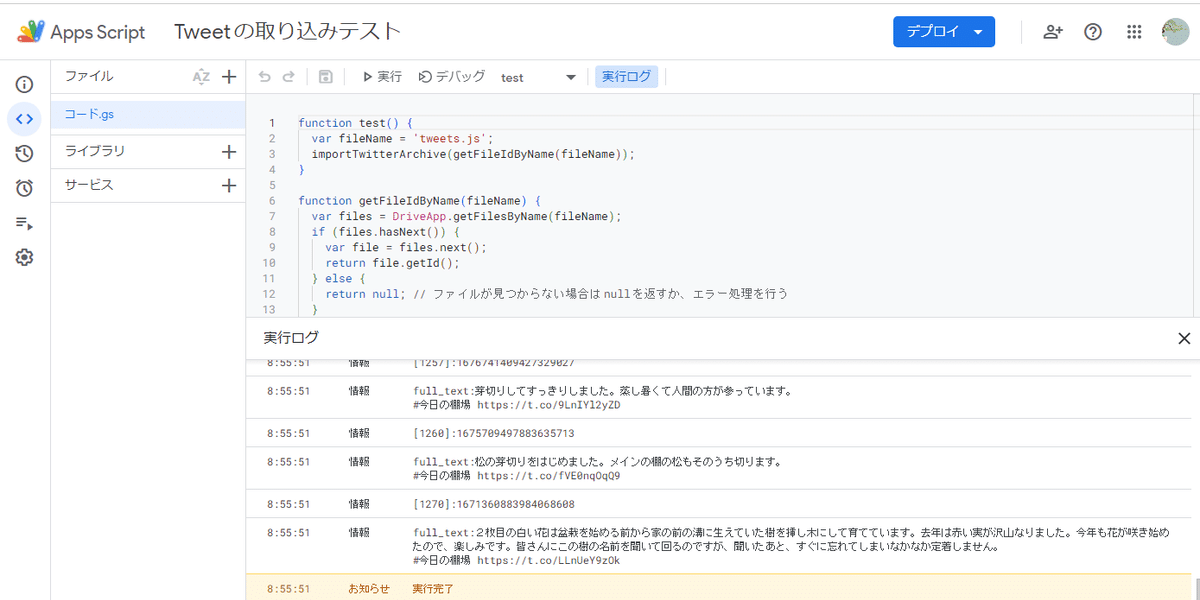
一歩進めます
ファイル「Tweet一覧」を作成しました。
少しずつ、シートを作るのが上手くなってきていると思います。
1列目に「ファイル名」や「Twitter ID(@なし)」などの定数値を書けるようにして、その値を見て処理を行うようにしました。

メニューに「Tweet取り込み」を追加して、サブメニューを追加します。
「Tweet取り込み」を選ぶと、Google Apps Scriptが動作します。
onClickItem1関数が呼ばれ処理が始まります。
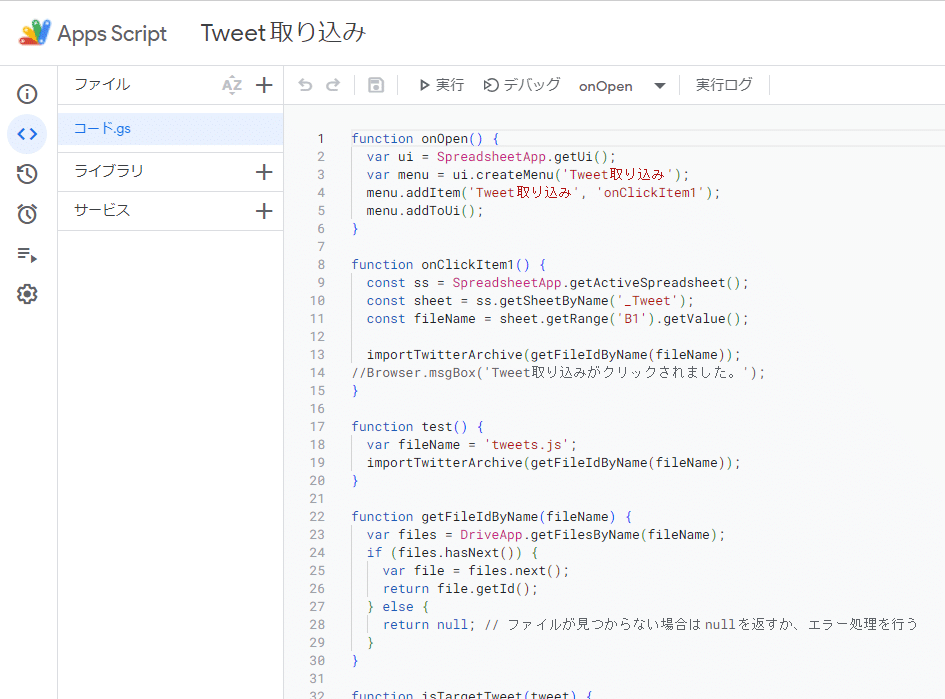
スクリプトの内容です。
function onOpen() {
var ui = SpreadsheetApp.getUi();
var menu = ui.createMenu('Tweet取り込み');
menu.addItem('Tweet取り込み', 'onClickItem1');
menu.addToUi();
}
function onClickItem1() {
const ss = SpreadsheetApp.getActiveSpreadsheet();
const sheet = ss.getSheetByName('_Tweet');
const fileName = sheet.getRange('B1').getValue();
importTwitterArchive(getFileIdByName(fileName));
//Browser.msgBox('Tweet取り込みがクリックされました。');
}
function test() {
var fileName = 'tweets.js';
importTwitterArchive(getFileIdByName(fileName));
}
function getFileIdByName(fileName) {
var files = DriveApp.getFilesByName(fileName);
if (files.hasNext()) {
var file = files.next();
return file.getId();
} else {
return null; // ファイルが見つからない場合はnullを返すか、エラー処理を行う
}
}
function isTargetTweet(tweet) {
//画像があり、返信、リツイートではないものか判定する。
const full_text = tweet.full_text;
if (full_text.substr(0, 2) == "RT") {
return false;
}
else if (full_text.substr(0, 1) == "@") {
return false;
}
const entities = tweet.entities;
if (typeof entities !== 'undefined') {
if (typeof entities.media !== 'undefined') {
for (let i in entities.media) {
const media = entities.media[i];
if (typeof media.type !== 'undefined') {
if (media.type === 'photo') {
return true;
}
}
}
}
}
const extended_entities = tweet.extended_entities;
if (typeof extended_entities !== 'undefined') {
if (typeof extended_entities.media !== 'undefined') {
for (let i in entities.media) {
const media = entities.media[i];
if (typeof media.type !== 'undefined') {
if (media.type === 'photo') {
return true;
}
}
}
}
}
return false;
}
function importTwitterArchive(jsonFile) {
// ファイルからデータを読み込む
var file = DriveApp.getFileById(jsonFile);
var content = file.getBlob().getDataAsString();
var content2 = content.replace(/^.*window\.YTD\.tweets\.part0\s*=\s*/, '');
let tweetInfo = []
// JSONデータをパースする
var jsonData = JSON.parse(content2);
for (let i in jsonData) {
const tweet = jsonData[i].tweet;
if (isTargetTweet(tweet)) {
Logger.log("[" + i + "]:" + tweet.id);
Logger.log("full_text:" + tweet.full_text);
//twitterのリンクを書き出す。
tweetInfo.push([
tweet.created_at,
tweet.id
])
}
}
const ss = SpreadsheetApp.getActiveSheet()
ss.getRange(3,2,tweetInfo.length,tweetInfo[0].length).setValues(tweetInfo)
}
このようになりました。
GASで「日時」、「id」を読みだしています。「url」はセルD3に以下の式を書いて、リンクに仕立てています。
=ARRAYFORMULA(IF(C3:C<>"","https://twitter.com/"&$D$1&"/status/"&C3:C,""))マウスを当てると、リンクが表示されます。ものによってはプレビューが表示されます。

後はこれらの情報を見ながら、以前画像一覧を作ったときのように写真に写っている盆栽のkeyを書き入れます。
複数の鉢が写っているときにどうするかは今後の課題です。
特徴的な鉢については、照合しやすいですが、苗木になると、keyを探すことは結構大変な作業となります。
ただ、これこそが過去の貴重な資料となります。
完走しました
とにかくこれで、画像を含む過去の投稿をリストアップすることができました。ソートしたり、盆栽カルテに組み込んだり、夢は広がりますが、今回はここまでにしておきます。
あとはゆっくり、keyの照合を行っていきます。

さいごに
プロフィール欄を見ると1313件のポストと書いています。
画像付きのポストは1000件ぐらいあるかと思っていましたが、350件ほどでした。確かに毎日つぶやくタイプではないので、非常に少ないですね。
今回、JSON型式のファイルに向き合いました。比較的簡単に欲しいデータを抽出することができましたが、プログラム中でデータ構造を見てやる必要があり、どこまで行ってもきれいな処理にならないなと思いました。
ただ、この方法を身に付けることにより、X(旧Twitter)だけではなく、インスタやほかのSNSのアーカイブファイルも解析できる可能性があります。
最後までお読みいただき誠にありがとうございました。