
ドーパミンは本当に報酬予測誤差を表現するか?
今回紹介する論文は以下。
Kim, HyungGoo R., et al. "A unified framework for dopamine signals across timescales." Cell 183.6 (2020): 1600-1616.
DOI: https://doi.org/10.1016/j.cell.2020.11.013
ドーパミンは意思決定や薬物中毒の病態に関与する神経修飾物質。
機械学習の一領域で、意思決定則を学習する手法である強化学習では、学習シグナルとして報酬予測誤差(RPE)が用いられる。
中脳ドーパミンニューロンが報酬予測誤差をエンコードしており、哺乳類が方策を学習する際に重要な役割を果たしているという報酬予測誤差仮説が長らく提唱されてきた。
一方で、中脳ドーパミンニューロンが(少なくとも部分的に)状態価値(Value)をエンコードしているという価値仮説も近年提唱されている。
そこで、報酬予測誤差仮説と価値仮説どちらが正しいのか(どちらのモデルが中脳のドーパミン神経の活動をより説明できるのか)が、今回の主題である。
本研究では、ドーパミン神経が価値と報酬予測誤差どちらを表現しているのかを区別するために、仮想環境を用いた新たなパブロフ型の実験パラダイムが開発された。
仮想環境を違う場所へと瞬間移動させるテレポート、仮想環境を移動させる速度を変化させる速度操作を実験中に行い、その際に報酬予測誤差仮説と価値仮説から予測されるドーパミン神経活動のどちらと実際の神経活動が近いかを比較するという実験設計になっている。
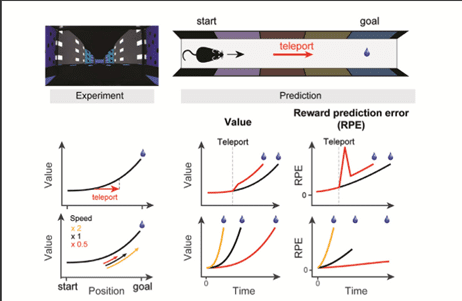
まず、in vivoで特定の神経細胞群の活動を取得できるファイバーフルオロメトリーを用いて、腹側線条体(VS)におけるドーパミン神経軸索の活動が記録された。
テレポートをした際の実験データは報酬予測誤差仮説からの予測に似た、一過性のピーク応答を示した。(図2)

では、(先行研究で価値仮説に合致するとさせていた)ゆっくりと立ち上がるドーパミンシグナルの場合はどうなのか?
これを検証するために速度操作を行った場合も、データは報酬予測誤差からの予測に似た、異なる報酬前のシグナル応答を示した(図2)。

実験データに対して各モデルを用いてフィットし、赤池情報量基準によりモデルの性能を比較した場合も報酬予測誤差モデルは価値モデルよりもデータに合致することが分かった。(図3)

次に、腹側被蓋野(VTA)におけるドーパミン神経スパイク活動を電気生理学的手法を用いて測定すると、個々の神経のスパイク活動も報酬予測誤差を表現していることが分かった。(図5)

他に、腹側被蓋野ドーパミン神経の細胞体のカルシウムシグナル、腹側線条体におけるドーパミン濃度も報酬予測誤差と合致することが示されている。(図6)

結論
ドーパミン神経細胞は、価値に対する微分的な信号を計算することで、報酬予測誤差を表現している。
報酬予測誤差シグナルは、測定場所、測定方法、測定タイムスケールによらず観測され、報酬予測誤差仮説は普遍的なモデルである。
重要性
価値と報酬予測誤差は多くの場合どちらも報酬に向けて上昇するため判別が困難である。
しかし、本研究では、仮想環境を駆使した新たな実験パラダイムとモデルを併用することで、明確にドーパミンが報酬予測誤差をエンコードしていることを導いた。
課題
報酬予測誤差仮説に基づいていて議論しているが、ドーパミンが検証していない他の関数を表現している可能性がある。
仮想環境は本当の環境を再現できていないため、アーチファクトが加わっている可能性がある。
本研究では状態価値が相対的な位置と結びついているが、実際の環境はより複雑であり、状態は不確かである。
線条体のドーパミン神経は多様な応答を示し、報酬予測誤差仮説で一様に説明するのは不適切な部分もある。
課題の最後の点については、分散的強化学習(distributional reinforcement learning)と対比して、ドーパミンシグナルのばらつきの階層性は計算論的に有利であると主張する同じグループからの論文が出版されている。(Dabney et al., 2020)
感想
既に提唱されていることを検証するという点で珍しいタイプの論文だが、脳の情報処理を実験とモデルを組み合わせて論理的に明らかにするという非常に質の高い研究であり、もっとこのような研究が評価されて増えてほしいと感じた。
多くの神経修飾物質は多様な機能を様々な脳部位で担っているイメージがあるが、ドーパミンに関しては(少なくともこの研究で調べられている範囲では)一貫して報酬予測誤差を表現している。
ここから報酬予測誤差の学習シグナルとしての重要性が感じられ、また情報と分子が明確に結びつけられた数少ない例といえるのではないかと思う。
ドーパミン神経が報酬予測誤差をエンコードしていることが判明した。ドーパミン神経細胞は、価値に対する微分的な信号を計算することで報酬予測誤差を表現。ドーパミン神経の細胞体のカルシウムシグナルも報酬予測誤差と合致する。
サムネイル画像の出典:https://doi.org/10.1016/j.cell.2020.11.013