
情報で捉える生物学入門#番外編2 【BEND: DNA言語モデルのベンチマーク】
生命の設計図であるゲノム情報が大量に蓄積されているのに比べ、DNA配列の機能のアノテーションは実験コストと困難さの観点から十分に進んでいない。よって、DNA配列のみから分子表現型を予測するHyenaDNAや機能的なDNA配列を生成することが出来るEvoをはじめとした教師なしDNA言語モデルの重要性が認識され、多くのモデルが提案されている。一方で、その評価はモデルによって個別に行われることが多く、統一できていない現状がある。
本論文では、ヒトゲノムについて、様々な配列解像度でDNA言語モデルの比較を公平に行うためのベンチマークBENDが提案された。
Marin, Frederikke Isa, et al. "Bend: Benchmarking dna language models on biologically meaningful tasks."
[2311.12570] BEND: Benchmarking DNA Language Models on biologically meaningful tasks
コード
https://github.com/frederikkemarin/BEND
Methods
表1は、ベンチマークに含まれる7つのタスクを列挙している。配列が遺伝子の一部かを分類する遺伝子発見タスク、配列から遺伝子の発現を調節するエンハンサー部位を見つけるエンハンサー注釈タスク、配列からクロマチンの構造のゆるさ(転写因子の近づきやすさ)を予測するクロマチンアクセシビリティー予測タスク、DNA配列が構成するヌクレオソームの構造の緩さに影響するヒストンが修飾されているかを予測するヒストン修飾予測タスク、遺伝子発現に影響するCpG配列がメチル化されているか予測するCpG配列メチル化予測タスク、遺伝子をコードしていない配列の1塩基変異が遺伝子の発現や疾患に影響するかを予測するノンコーディング変異効果予測タスクが作成された。タスク単一塩基解像度でマルチクラス分類を行うタスク(遺伝子発見タスクなど)から、シークエンスを入力としてマルチクラス分類を行うタスク(クロマチンアクセシビリティーなど)まで、様々な粒度で複合的な予測の必要なタスクが設計されている点が特徴的である。

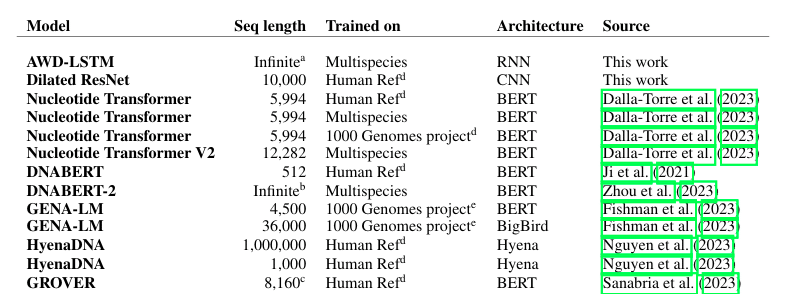
表2は、今回比較したヒトゲノムに適用可能なDNA言語モデルを列挙している。Nucleotide Transformer、DNABERT、HyenaDNAといったトランスフォーマーベースの言語モデルのほか、それと比較するためのRNN、CNNベースの教師あり学習モデルも用いられている。
Results
表3に、すべてのタスクに対する各モデルの性能がまとめられている。太字で示されている部分が、DNA言語モデルの中で各タスクで最高の性能を示したものである。

DNA言語モデルは既存のタスク特異的に教師あり学習されたエキスパートモデルに比べて、常に優れた性能を示すわけではなかった。特にエンハンサーアノテーションなどDNA上の遠い依存関係の把握が必要な課題において性能が劣っていた。遺伝子のアノテーションなど他の多くのタスクでは、事前学習で良い特徴量の埋め込みを獲得したことにより、エキスパートの教師あり学習モデルに匹敵する性能を出すことができた。
DNA言語モデルの全体的な性能としてはNT-MS(Nucleotide Transformer Multi Species)が最も優れていたが、より小規模のDNABERTが優れているタスクもあった。どちらのモデルもマスク言語モデルの一種で同様のトレーニング方法を用いているのにも関わらず、異なるゲノム上の特徴量を学習していることが分かった。異なるトレーニングデータやトークン化手法がこれらの違いの原因となっている可能性がある。
Discussion
LLMは多くのモデルを統一的に比較するベンチマークが開発されたために競争が進み、分野が進展した。一方で、多くのDNA言語モデルは個別のタスクと評価指標を用いており、すべてのモデルを一貫して評価し、比較するのが困難な状況である。本研究BENDでは、7つのタスクとデータセットを整備し、教師ありのベースラインとなる手法と現時点で公開されているヒトゲノム用の6つの自己教師ありDNA言語モデルを公平に比較した点が、この分野の研究を発展させるうえでの貢献である。
既存のDNA言語モデルのベンチマークのための研究としては、Genome Understanding Evaluation(GUE)が挙げられる。GUEはDNABERT、NTなどの主要なDNA言語モデルが比較されている一方で、タスクは70-1000bpを入力長としたプロモーターの判別や転写因子の結合配列のクラス分類など簡易的なものである。遺伝子の発見などに加えて、局所的な配列モチーフでは解けないエンハンサーアノテーションなどの長距離の文脈に依存した複雑で実世界に近い生物学的に有用なタスクを含んでいるという点で、BENDは優れている。
各モデルが事前学習しているスプライシングやイントロン箇所、遺伝子の上流・下流などの特徴量について記述があるが、モデルの性能から推測されているのみで、詳しい検討はなされていない。DNA言語モデルがどのような生物学的現象の表象を学習しているか調べるために、潜在空間や、注意機構がどのように入力・潜在空間の要素間で働いているか可視化される場合が多いが、そのような解析は行われていない。
DNA自体に分類ラベル等の情報は含まれていないため、DNA配列の入力のみに依存したSNP(Single Nucleotide Polymorphism)のZero-Shot機能分類については、変異塩基配列と参照塩基配列の埋め込みのコサイン類似度をもとに分類を行っている。それぞれのモデルのSNPを含む位置での埋め込みを性能評価に用いたと論文に記載されているが、トランスフォーマーベースのモデルと自己回帰モデルでこのような埋め込みの選択をしていることが公平な性能比較につながっているのかが曖昧である。
特に、長距離の依存関係を捉えることが得意なHyenaをもとにしたモデルであるHyenaDNAは、最大100万トークンを1塩基解像度で扱うことが可能とされているが、今回のベンチマークでは性能が他のモデルに比べて劣っている。なぜ既存の長距離の依存関係を扱うモデルがDNAの遺伝子発現制御配列の予測という課題においてうまく機能せず、一般的な言語モデルをどのように手法を改良すればDNA上の長距離で疎な依存関係を限られたデータから学習し、扱うことができるのかは未解決課題である。
SNPの表現型への効果は正にも負にも働き、効果は連続的に変わっていくと考えられる。よって、本研究の2値分類では評価が粗すぎる可能性がある。実際に生物学・臨床への応用を考えた際には、これらの要素を考慮した多クラス分類、または効果量の推定が行われることが望ましい。
本研究では公開されている事前学習モデルの性能比較を行っているが、それらはパラメーター数・トレーニング時間が異なる。大規模言語モデルの性能は大まかにこれらの変数のべき乗に比例することが知られているため、モデル構造の比較という意味ではこれらの変数をそろえた比較が公平であるが、現状それは難しく、性能の違いの原因を正確に特定することが困難である。
参考文献
https://arxiv.org/abs/2311.12570
https://www.nature.com/articles/s41592-024-02523-z.pdf
https://academic.oup.com/bioinformatics/article-pdf/37/15/2112/53921029/btab083.pdf
https://arxiv.org/pdf/2306.15006
https://arxiv.org/pdf/2006.15222
https://proceedings.neurips.cc/paper_files/paper/2023/file/86ab6927ee4ae9bde4247793c46797c7-Paper-Conference.pdf
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3439153/
近年、DNA配列の機能を予測するDNA言語モデルの重要性が増しており、多くのモデルが提案されているが、それらの評価は統一されておらず比較が困難である。本研究では、ヒトゲノムにおけるDNA言語モデルの性能を公平に評価するためのベンチマーク BEND を提案し、7つのタスクを用いて既存のモデルを比較した。結果として、モデルによって得意なタスクが異なり、特に長距離依存関係を扱うべきタスクでは既存モデルの性能が十分でないことが示され、今後の課題としてより適切な表現学習や評価手法の開発が求められる。
サムネイル画像の出典:https://arxiv.org/abs/2311.12570