
報酬予測誤差神経は報酬の効率的符号化を実現する
報酬と、「報酬がどの程度もらえそうか」という価値の判断は、意思決定、計画、学習などの認知過程に重要である。 まだまだ議論があるもの、中脳のドーパミン神経が報酬量が期待と比べて多かったか少なかったかという報酬予測誤差を表象することで、脳は試行錯誤によりそれぞれの状況でどのような判断を下せばよいかという方策を学ぶ強化学習を実装していると考えられている。
感覚情報処理の分野では、神経系が限られた神経・活動電位という資源の下で最大限の情報を伝達しているという効率的符号化の仮説が提唱されている。例えば、脳が視覚刺激を符号化する際、自然界に頻繁にみられるパターンに対して最適化されていると考えられている。
本研究は報酬予測誤差神経が報酬の効率的符号化を神経レベルで実装しているという仮説の検証を行う。まず、報酬の分布をシグモイド関数でチューニングされた神経で表象する際の最適な分布を導出した。次に、この枠組みを固定された報酬分布を与えられた際の報酬予測誤差神経の応答を記録したマウスのデータと、異なる報酬分布が与えられた際のサルのデータへと適用し、効率的符号化の重要な特性がデータに反映されていることを示した。
Schütt, H.H., Kim, D. & Ma, W.J. Reward prediction error neurons implement an efficient code for reward. Nat Neurosci 27, 1333–1339 (2024). https://doi.org/10.1038/s41593-024-01671-x
Methods
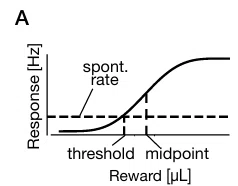
筆者らは、情報論的な意味で報酬をエンコードするのに最適な神経集団を解析的に導出した。報酬予測誤差神経が報酬に対してシグモイド関数で応答すると仮定すると(図1A)、神経の応答は以下の式で記述できる。

ここで、hがシグモイド関数、$${F(R)=\int_{-∞}^{R}f(t)dt}$$が報酬量を発火頻度と結びつける関数で、Rが報酬量、μがシグモイドの応答の中間値を与える入力(図1AのMidpoint, 以下単に神経の中間値と呼ぶ)、gが応答のゲイン(応答の大きさの最大値)である。
報酬の分布を最も効率的に符号化できる(発火率に制約がある条件下での情報量を最大化する)神経集団を次の3つの関数を最適化することで求めた。

ここで、pは報酬の確率密度関数、dは神経の中間値が特定の値になる確率密度関数である。
この効率的符号化から導かれる報酬への応答は、予測される応答が繰り返されると神経の中間値が与えられる報酬の値に収束するので、すべての神経が中間値に対するエラーをエンコードするようになり、報酬予測誤差神経の出現を自然に説明することが出来る。
Results
図1では、様々な報酬を得た際の中脳報酬予測誤差神経の応答と効率的符号化から解析的に算出した応答曲線を提示している。7つの報酬量をマウスに与えた先行研究(図1B)の実験データから、報酬に対する応答の大きさのチューニングカーブを算出した(図1C)。報酬分布の効率的符号化から予測される応答カーブ(図1D)も算出し、効率的符号化から導かれる応答カーブの特性とデータを比較する準備が整った。

図2は、効率符号化から予測される4つの報酬予測誤差神経の特性がデータと合致することを示している。
報酬予測誤差神経の中間値は報酬分布を大雑把に実際の報酬の分布と似た分布でカバーした(図2A)。
報酬への応答閾値が高い神経ほど応答のゲイン(最大値)が大きくなった(図2B)。効率的符号化から導かれる青線とよくフィットしている。
効率的符号化の枠組みからは、低い応答閾値を持つ報酬予測誤差神経は閾値付近が凸カーブになっており、高い応答閾値を持つ神経は閾値付近が凹んだカーブになっていることが予測される(図2C)。この神経応答の非対称性はデータにもみられ(図2D)、以前は分布型強化学習の枠組みで説明されていた(図2E)。
高い報酬応答閾値を持つ報酬予測誤差神経は、シグモイド関数の傾きが緩やかになることが分かった(図2F)。

分布型強化学習の枠組みでは、報酬予測誤差神経の閾値が、報酬と閾値の違いに正と負で異なる比例定数で比例するように更新され、観測された神経の閾値と非対称性を説明することが出来る。効率的符号化は、分布型強化学習のシグモイド関数のゲイン・傾きと神経の閾値との関係を最適化するように拡張したものと捉えることが出来る。
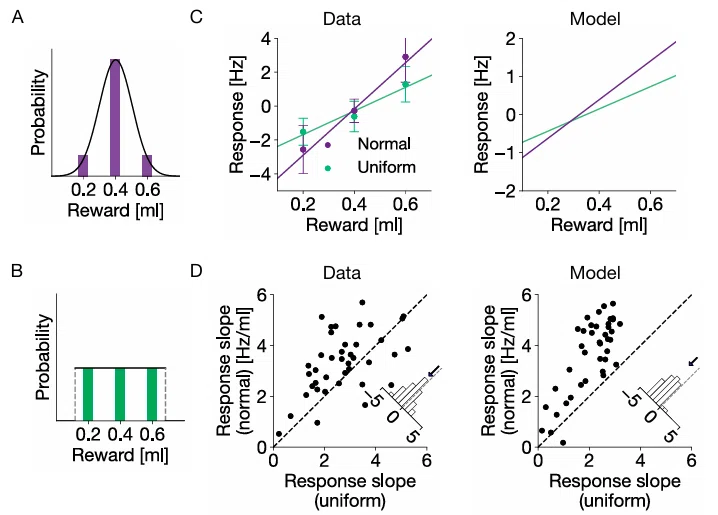
図3では、効率的符号化モデルは報酬の分布形状を変化させた際の報酬予測誤差神経の応答の変化を説明できることを示している。報酬量の分布を正規分布(紫:図3A)、一様分布(緑:図3B)で変化させた際の報酬量と応答の大きさの線形関係、傾きはモデルから予測されるものに類似していた(図3C、D)。
さらに本研究は報酬予測誤差神経の中央値、傾き、ゲインの学習が効率的符号化にどのように寄与するかの比較が行われ、これらの値の学習が分布型強化学習の枠組みを効率的符号化の枠組みに拡張するのに十分であることを示している(図4)。これにより、報酬量に対する応答の傾きやゲインなどを中脳報酬予測誤差神経が学習しているという実験的検証が可能な新たな仮説が提示された。
Discussion
報酬予測誤差神経データの応答特性を説明することで、感覚推論における効率的符号化の枠組みを報酬分布の神経集団による最適なエンコードを導くのに応用した。この結果は情報量の定義の仕方、神経応答の分布、シグモイド関数の形状に対して頑健である。計算論的神経科学で最も成功している感覚情報表象の効率的符号化と意思決定での報酬予測誤差の研究を統一する研究となっている。
今回の研究では報酬分布の表象を効率的符号化で行うことが仮説としてあったが、報酬分布は一次元の情報で、非常に高次元のベクトル空間を構成しうる感覚情報と比べてそもそもの情報が圧倒的に少ないはずである。それに対して報酬予測誤差を表象する中脳ドーパミン神経は多数存在するので、そもそもなぜ少ない神経で情報を表象する必要があるのかは気になった。
本論文でも触れられているように、報酬予測誤差の応答が分布をなすことは以前から知られており、楽観的な報酬予測誤差神経や悲観的な報酬予測誤差神経がいることが知られていた。強化学習の文脈では、オンライン強化学習では楽観的な価値判断をすることで探索を推進し、オフライン強化学習では悲観的な価値判断をすることで正確性をあげることが重要なようだ。今回の研究とは離れるが、実際の報酬予測誤差神経の分布がこのような使われ方をされているのかは興味深い。
参考文献
本研究は、中脳の報酬予測誤差神経が報酬の効率的符号化を行っているかを調べ、最適な神経応答の分布を理論的に導出し、実験データと比較することでその特性を検証した。得られた結果は、報酬予測誤差神経の応答特性が効率的符号化理論と一致することを示している。また、研究は効率的符号化の枠組みが報酬予測に基づく強化学習の理解を深める可能性を提案している。
サムネイル画像の出典:Reward prediction error neurons implement an efficient code for reward | Nature Neuroscience