
【ローカルLLM】text-generation-webUIのAPI機能を試す

ローカルLLMをAPI的に使う場合は、llama.cpp(GGUF/GGML)が手軽そう。ただ、大きなモデルではExllama(GPTQ)も使えると便利。
LLM用のウェブUIであるtext-generation-webUIにAPI機能が付属しているので、これを使ってExllama+GPTQのAPIを試してみた。
公式によると、WebUIの起動時に「--api」(公開URLの場合は「--public-api」)のFlagをつければAPIが有効になる。

まずローカル環境で「--api」を試したところ問題なく利用できた。
ローカルで動かせないモデルも扱えるように、クラウド経由でAPIを使えるようにしておきたい。なので次に「--public-api」も試してみる。
「--public-api」の場合、そのままではエラーで起動に失敗。依存関係「flask_cloudflared」を追加でインストールする必要があるらしい。
ということで、Exllama(GPTQ)を「--public-api」で使う場合のサンプルコードはこんな感じ。
# Text Generation WebUIのインストール
!git clone https://github.com/oobabooga/text-generation-webui
%cd text-generation-webui
!pip install -r requirements.txt
# "--public-api"を使う場合の追加インストール
!pip install flask_cloudflared
# モデルのダウンロード
!python3 download-model.py TheBloke/Llama-2-7b-Chat-GPTQ
# APIサーバーの起動
!python3 server.py --public-api --loader exllama --model TheBloke_Llama-2-7b-Chat-GPTQこれでWebUIを起動すると「https://***************.trycloudflare.com/api」という公開URLが発行される。
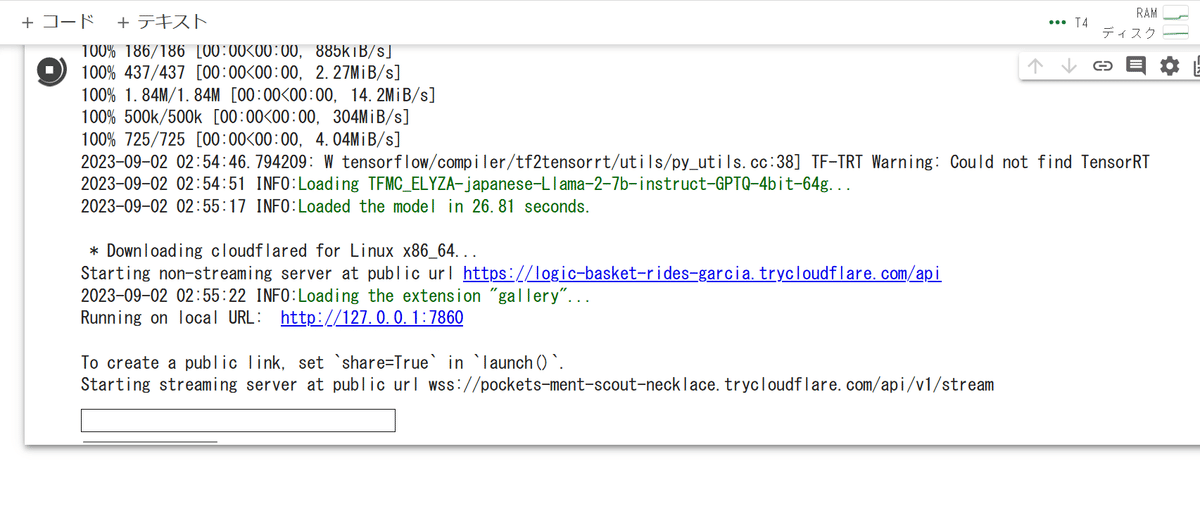
APIのたたき方については、公式のサンプルがいくつか用意されているのでそちらを参考にした。
今回は基本的な「api-example.py」で試す。WebUI本体と同様にパラメータがたくさんあり、サンプリングは細かく調節可能。
import requests
# ローカルのAPIを使用する場合
#HOST = 'localhost:5000'
#URI = f'http://{HOST}/api/v1/generate'
# 公開URLのAPIを使用する場合
URI = 'https://********************.trycloudflare.com/api/v1/generate'
def run(prompt):
request = {
'prompt': prompt,
'max_new_tokens': 250,
'auto_max_new_tokens': False,
'max_tokens_second': 0,
# Generation params. If 'preset' is set to different than 'None', the values
# in presets/preset-name.yaml are used instead of the individual numbers.
'preset': 'None',
'do_sample': True,
'temperature': 0.7,
'top_p': 0.1,
'typical_p': 1,
'epsilon_cutoff': 0, # In units of 1e-4
'eta_cutoff': 0, # In units of 1e-4
'tfs': 1,
'top_a': 0,
'repetition_penalty': 1.18,
'repetition_penalty_range': 0,
'top_k': 40,
'min_length': 0,
'no_repeat_ngram_size': 0,
'num_beams': 1,
'penalty_alpha': 0,
'length_penalty': 1,
'early_stopping': False,
'mirostat_mode': 0,
'mirostat_tau': 5,
'mirostat_eta': 0.1,
'guidance_scale': 1,
'negative_prompt': '',
'seed': -1,
'add_bos_token': True,
'truncation_length': 2048,
'ban_eos_token': False,
'skip_special_tokens': True,
'stopping_strings': []
}
response = requests.post(URI, json=request)
if response.status_code == 200:
result = response.json()['results'][0]['text']
print(prompt + result)
if __name__ == '__main__':
prompt = "自家製パンを作るには、以下の手順に従う。:\n1)"
run(prompt)実行すると、サクッとレスポンスが返ってきた。問題なくAPIとして利用できそう。

もちろんGPTQモデルだけでなく、llama.cppやTransformersのモデルも指定すれば使えるはず。