
Geminiで分析業務の効率化~基礎統計整理・可視化・モデリング編~

みなさん、こんにちは!
サービス統括本部データソリューション部でデータサイエンティストをしている奥野です。
先日、「Gemini LT会登壇~分析設計にGeminiを組み込む~」を記事にしましたが、前回に引き続きGemini社内LT会で、Gemini分析活用についてお話してきましたので、今回も記事としてまとめました。
前回は「分析設計」におけるGeminiの活用方法についてご紹介しましたが、今回は「基礎統計整理」「可視化」「モデリング」フェイズでの活用方法がテーマとなります。
導入
今回は分析業務の中心となる統計の可視化とモデリングについてのお話です。生成AI以前はスプレッドシートやPythonとにらめっこしながら、人間が地道に頑張る方法が主流だったと思います。

Geminiとの協業
Geminiの出現でこの状況は大きく変わりました!
Geminiは自然言語で指示するだけで、SQLの作成やデータの可視化、数理モデルの実装まで、様々な作業に協力してくれます。
効率化: 面倒な作業を自動化することで、分析時間を短縮できます。
コードを書かずに分析: 自然言語で指示するだけでPythonによる可視化やモデリングを実行できます。
質の向上: 作業の自動化により、人間はレビューと考察に集中でき、分析の質を高めることができます。
話の流れ
今回は分析テーマとして「商品単価と販売数の関連性のモデル化」というものを設定し、「基礎統計整理」「可視化」「モデリング」の各フェイズで、実際にどのようにGeminiと協業できるか説明していきました。
基礎統計整理
基礎統計整理では、データの抽出や集計、検証など、様々なSQLを記述する必要があります。
Geminiは、これらのSQL作成をサポートしてくれる、頼もしい存在です。
データ抽出・集計用SQLの作成
商品単価と販売数の関連が知りたいので、まずは過去の購買実績から「商品カテゴリ毎に商品単価別販売数」を確認することにします。
以下のように集計対象テーブルの定義を含めてGeminiに指示すると、そのままコピペして使えるSQLを生成してくれます。
# 命令文
購買データから購買商品カテゴリ毎に商品単価別販売個数をBigqueryで集計するためのSQLを作成してください。
# 集計条件
- 商品単価は、100円単位で階級化して集計してください。
- 集計期間は2024年4月の1ヶ月間としてください
# 購買データの概要
## テーブル名
- acl-dmp.marketing.purchase_log
## カラムの説明
- purchase_date: 購買日
- purchase_detail_id: オーダー明細ID
- purchase_unit_price: 商品単価
- purchase_item_num: オーダー明細単位の販売個数
- purchase_detail_sales: オーダー明細単位の流通額
- item_categ_name_1: 購買商品カテゴリ
# 出力できますが・・・これで得られた結果は正しいのでしょうか。
それを確認するため、SQLについても通常はテスト(数値検証)を行う必要があります。
そもそも実装に不慣れな場合、ここが課題になると考えていますが、この障壁もGeminiと一緒に解決していく方法があるかと思っています。
Geminiと一緒にSQLを学ぶ
検証もGeminiと協業する
Geminiと一緒にSQLを学ぶ
BigQueryの関数の使い方を学習したい場合は、GeminiにSQLサンプルを作成してもらうことができます。
ここでオススメしたいのが、Googleドキュメントのサイドパネルを活用する方法です。

具体的な関数の使い方を聞いてもいいですし、もう少し基本的なところから学びたい場合は、以下のようなプロンプトでパブリックデータを使ったSQLの演習問題と解答、解説を生成してくれます。
BigQueryでよく使うSQLの関数で問題・回答・解説セットを作成してください
データセットは bigquery-public-data.samples.shakespeare を使ってください必要な分だけ自分のペースで知識獲得できますし、記録はドキュメントに残していけて便利ですね。
検証もGeminiと協業する
集計結果の検証作業は正直面倒ですが、正確な分析を行う上で非常に重要です。
Geminiに検証用のSQLを生成させれば客観的な視点が入りますし、なにより対話しながらであれば、気が滅入りがち(?)な検証作業を飽きずに進められるという心理的な効果もあるように思っています。
検証対象になる価格帯別販売数を集計するSQLは自分で作って、それの検証のための特定カテゴリの特定価格帯の販売数を抽出するSQLをGeminiに作ってもらうなど、分担するのがよさそうだと思っています。
# 命令文
購買データをつかって販売個数を集計するためのSQLを作成してください。
# 集計条件
- 集計する購買商品カテゴリは「XXXX」としてください
- 商品単価が2200円以上2300円未満のものを集計してください。
- 集計期間は2024年4月の1ヶ月間としてください
# 購買データの概要
## テーブル名
- acl-dmp.marketing.purchase_log
## カラムの説明
- purchase_date: 購買日
- purchase_detail_id: オーダー明細ID
- purchase_unit_price: 商品単価
- purchase_item_num: オーダー明細単位の販売個数
- purchase_detail_sales: オーダー明細単位の流通額
- item_categ_name_1: 購買商品カテゴリ
# 出力可視化
データ分析における可視化の大きな役割は、データを俯瞰し、傾向や特徴をおおまかに把握することだと思います。
そのためには多くの情報を多様な切り口で可視化する必要がありますが、これはなかなか手間とコストがかかります。スプレッドシートで1つ1つグラフを作って途方に暮れた経験がある方も多いのではないでしょうか?
ここでGeminiを使うと、自然言語で指示するだけで、様々なグラフを作成することができます。
例えば、商品カテゴリ別に価格帯と販売個数の関連を可視化したい場合は、以下のように指示します。
# 命令
- 添付したファイルの「データ_価格帯売上点数」シートのデータを使って散布図を作成してください
# 条件
- 横軸:purchase_unit_price_class
- 縦軸:sum_purchase_item_num
- 散布図はitem_categ_name_1別に作成
では、始めてくださいすると、Geminiは添付されたファイルを読み込んで、各カテゴリの散布図を自動で作成してくれます。(裏側でPythonの可視化用コードを自動実装し、実行までしてくれます。)

au PAY マーケットは総合ショッピングサイトで、一番大きな区分の商品カテゴリでも「グルメ・食品」「レディースファッション」など30くらいあります。これをプロンプトでの指示だけで全カテゴリ可視化できるというのは・・・本当に便利になったなと感動しました。
データ分析の仕事をしていると、多くの情報を可視化して比較するという場面は多いですが、Geminiで可視化が一瞬で終わると、分析者は考察工程に集中力を残しておくことができますね。
おや、早速なにやら怪しげなカテゴリが見つかりました。
全体的な傾向は商品単価の上昇に対して販売数は指数関数的な減衰の関係にあるようでしたが、関係性の当てはめが困難そうなカテゴリも存在するということですね。

この後は、この結果を踏まえて分析モデルの構築へ進みます。
補足:Geminiの成功率を上げるための工夫
体感の話で恐縮ですが、Geminiはデータの読み込みでうまく行かない場合が多いように感じます。これは読み込ませるデータを工夫してやると成功率が上がるので、ぜひ参考にしてみてください。
シートに利用したいデータ以外の情報(テーブルの説明とか引用元とか)は記載しない
スプレッドシートのファイルサイズが大きい場合、必要データだけ切り出して利用する(Geminiに入力可能なコンテキストウインドウのサイズを超えるのだと思います)
数字に書式設定しない(大きい数字は3桁カンマ区切りにしたくなりますが、これをすると文字列として扱われたりします)
モデリング
Geminiはモデリングにも活用できます。
今回は価格帯と販売個数の関係をモデル化するので、可視化の結果を踏まえて以下のような手順でGeminiに指示しながらモデリングを進めていきます。
モデルの当てはめ: 価格帯と販売個数の関係に指数モデルを当てはめ
モデルの評価: 決定係数などの指標を用いてモデルの精度を評価
結果の掘り下げ: モデルの精度が低い場合はその原因を分析
モデルの当てはめ
特定のカテゴリを例に、価格帯と販売個数の関連性について指数モデル仮説を検証しましょう。
まずは分布を改めて確認して・・・
# 命令
- 添付したファイルの「データ_価格帯売上点数」シートのデータを使って散布図を作成してください
# 条件
- 横軸:purchase_unit_price_class
- 縦軸:sum_purchase_item_num
- 散布図はitem_categ_name_1が「カテゴリA」のものを作成
- purchase_unit_price_classは数値データとして扱う
では、始めてくださいその流れで指数モデルを当てはめてみます。
ではこの分布に指数モデルを当てはめてください
なんと!これで指数モデルの当てはめが完了しました。
やはり裏側ではPythonのコードが自動生成され、実行されます。モデル当てはめの結果はそのままスプレッドシートにエクスポートもでき、考察もついてきます。いやいやホントにすごいなこれ。。
モデルの評価
いくつかのカテゴリに指数モデルを当てはめて、結果を評価してみます。
実はこれも対話の流れでできます。先程のモデル当てはめについて、別の商品カテゴリに対しても実施した後に、Geminiに以下のように依頼してみます。
ここまでの2つのモデルの精度指標を整理して、表でまとめてください結果はこちら。ちゃんと整理してくれましたね。
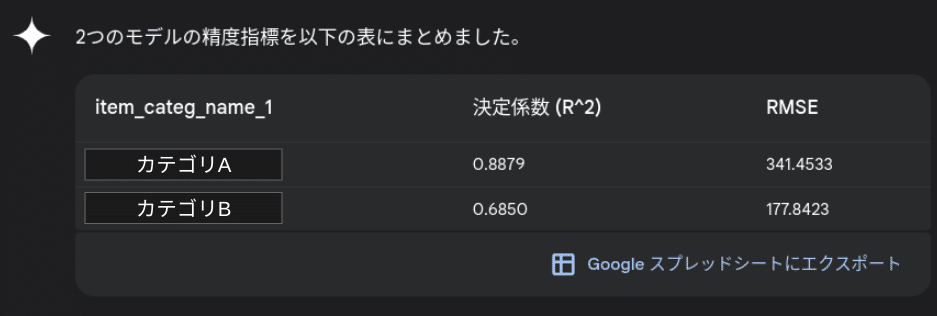
今まではPythonの実行環境を用意して、モデリング用ソースコードを実装し、実行して結果を得ていた作業が、Geminiとの対話だけでできるようになりました。
ソースコードや実行結果も確認できるので、レビューもできてブラックボックス化を防げますし、データとソースコードを保存しておけば(生成AIの回答に再現性はないですが)分析結果は再現できますね。
素晴らしい!
結果の掘り下げ
先程精度指標を比較しましたが、カテゴリ間で精度に差があることがわかりました。モデルの精度が低かったものの分布を再度確認してみます。

改めて分布を確認すると、この商品カテゴリについては、低価格帯区間が指数減衰とはなっていないみたいですね。
この場合どうするか・・・皆さんもGeminiに聞いてみてください!
基礎統計整理、可視化、モデリングでのGeminiの活用
ということで、基礎統計整理、可視化、モデリングの各フェイズでGeminiを活用してみました。Geminiの出現以前と比べると、明らかに一つ一つの作業効率が上がり、同じ時間でより広い・深い観点での分析ができるようになったと感じています。
前回発表の分析設計フェイズも含めて、Geminiは分析プロセス全体でパートナーとして非常に良い働きをしてくれますので、プロセス全体の効率化・品質向上が期待できますね!
まとめ
Geminiを活用することで、分析業務を大幅に効率化できることを追体験いただけたでしょうか?
Geminiを活用することで、より重要な「結果の評価・考察」に集中できるようになりました。冗談ではなく分析業という仕事の内容が変わってきているのだと思います。
Geminiは、まだまだ進化を続けています。
今後の発展に期待しつつ、楽しく活用していきましょう!