
Macで簡単 AI画像生成 -ControlNetを使う編-(未経験者向け)

まえがき
本記事は"ターミナル"を使ったことのない未経験者の方に向けた記事です。
Moche Diffusion v4.0でControlNetの機能が追加されましたので、Mochi DiffusionでControNetを使う方法を説明します。
2023/06/18追加:Mochi DiffusionはControlNetのプリプロセッサを備えてないので、元画像は別のプログラムなどのプリプロセッサで生成した画像が必要になる場合が多いようです。元画像を単に色調反転(白黒反転、ネガポジ変換)するだけで使えるものもあります。2023/06/17 注意追加!!!:使っていると何か勘違いしているところがありそうですので、この記事は参考にしないようお願いします。もうちょっと調べてみます。
ControlNetについて
Moche Diffusionに追加された、ControlNet 1.1には、今のことろ以下の14の機能があります。(Mochi Diffusionで使うために必要な元画像を付記します。)
control_v11p_sd15_canny(プリプロセッサで処理した元画像が必要)
control_v11p_sd15_mlsd(プリプロセッサで処理した元画像が必要)
control_v11f1p_sd15_depth(プリプロセッサで処理した元画像が必要)
control_v11p_sd15_normalbae(プリプロセッサで処理した元画像が必要)
control_v11p_sd15_seg(プリプロセッサで処理した元画像が必要)
control_v11p_sd15_inpaint(※プリプロセッサで処理した元画像が必要)
control_v11p_sd15_lineart(線画を色調反転すれば使えそう)
control_v11p_sd15s2_lineart_anime(線画を色調反転すれば使えそう)
control_v11p_sd15_openpose(プリプロセッサで処理した元画像が必要)
control_v11p_sd15_scribble(線画を色調反転すれば使える)
control_v11p_sd15_softedge(プリプロセッサで処理した元画像が必要)
control_v11e_sd15_shuffle(使用可能)
control_v11e_sd15_ip2p(使用可能)
control_v11f1e_sd15_tile(使用可能)
※ Mochi Diffusion v4.1よりInPaintに対応しました(2023/07/17)
注意:Mochi Diffusion v4.1.3では、ControlNetの元画像の読み込んで、その後にControlNet機能選択をしないとControlNetが動作しません。(2023/07/23)
それぞれの説明は、以下の公式ベージ(^^;
または、くろくまさんの以下のベージの解説をみましょう!(^^;)
必要なライブラリの保存
・ControlNetモデルの保存
Mochi Diffusion v4.0にはControlNetのモデルを保存する場所を指定するControlNetフォルダの項目が追加されました。

ControlNetフォルダにContronNetのモデルを保存します。変換済みのモデルを
Hugging FaceのCore ML Models Communityで配布しています。
Zipファイルを解凍した.mlmodelcを、Mochi Diffusionのcontrolnetフォルダに保存します。このNE(SE)向けモデルを使った場合のcontrolnetフォルダのファイル配置例は以下のようになります。
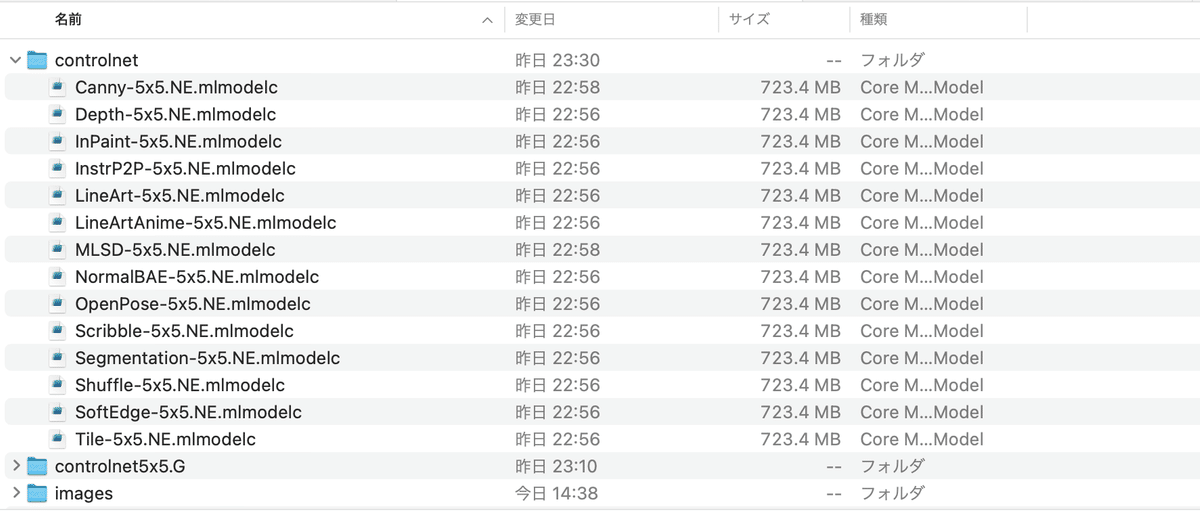
・ControlNet対応CoreMLモデルの保存
ControlNetを使うには、ControlNet対応のCoreMLモデルが必要です。変換済みのモデルをHugging FaceのCore ML Models Communityで配布しています。
以下のControlNetに対応するCoreMLモデルのサンプルも、jrrjrrさんの以下のURLで公開されています。
DreamShaper v5.0, 1.5-type model, "Original"GhostMix v1.1, 1.5-type anime model, "Original"MeinaMix v9.0 1.5-type anime model, "Original"MyMerge v1.0 1.5-type NSFW model, "Original"Realistic Vision v2.0, 1.5-type model, "Original"Stable Diffusion v1.5, "Original"
jrrjrrさんはControlNetをCPU & NEで使うと非常に遅いのでORIGINALモデルのみ公開されているようですが、私が使ってみた感じでは問題なさそうなので、NE向けのControlNetモデルを公開します。(NEなので画像サイズは512x512限定)
・ControlNetへの対応方法
jrrjrrさんのサンプルにないCoreMLモデルが使いたい場合は、コマンドラインを使って変換しましょう。変換ツールの構築は以下の前記事を参照してください。
ターミナルのみを立ち上げます。ターミナルはCore MLモデル変換用のPython環境へ切り替える必要があります。モデル変換を行うPython環境へ切り替えるには前に使った、以下のコマンドを実行してください。(環境名を変更した場合は変更した環境名で置き換えてください。)
conda activate coreml_stable_diffusionそして、テキストエディタから下記のコマンドをコピーして、ターミナルにペーストします。
cd ~/Documents/StableDiffusionORIGINALの場合
python -m python_coreml_stable_diffusion.torch2coreml --convert-unet --unet-support-controlnet --bundle-resources-for-swift-cli --model-version XXXXXXXX -o ./XXXXXXXX --latent-h 64 --latent-w 64 --attention-implementation ORIGINALNEを使う場合(SPLIT_EINSUM)
python -m python_coreml_stable_diffusion.torch2coreml --convert-unet --unet-support-controlnet --bundle-resources-for-swift-cli --model-version XXXXXXXX -o ./XXXXXXXX --latent-h 64 --latent-w 64モデル名XXXXXとCoreMLモデルの保存フォルダ、latent-h, latent-wは適宜変更してください。変換が完了すると"Resource"フォルダに"ControlledUnet.mlmodelc"というモデルができてきるので、このファイルをUnetなどと同じ場所へ移動するか、
ln -s Resources/ControlledUnet.mlmodelc .でシンボリックリンクを張ります。〜control-unet.mlpackageというファイルはゴミ箱にポイして削除しましょう!
個々のモデルについて
個々のControlNetモデルの使用例について説明します。この説明で使用するCoreMLモデルは個人的な趣味で852話さんのSDHK v3.0です(^^;
上記のCivitaiからsdhk_v30.safetensorsをダウンロードして、"--attention-implementation SPLIT_EINSUM"(512x512限定のNE用モデル)に変換したControlNet対応のCoreMLモデルと、NE向けControlNetモデルを組み合わせて使っています。
※SDHK v3.0とSDHK v4.0を変換したモデルをCore ML Models Communityで配布しています。
・control_v11p_sd15_canny
上が変換前の画像で、下が変換後の画像です、変換後は縞模様が入っています。今の所、残念ながら何か問題があるようです??


2023/06/17追加:元画像を色調反転(白黒反転やネガポジ変換)した画像にすると若干良くなるようです。

2023/06/18追加:プリプロセッサで処理した画像であれば問題なく画像生成できます。


・control_v11p_sd15_mlsd
2023/06/18追加:プリプロセッサで処理した元画像が必要ですので、以下の例は失敗例の参考程度に考えてください。
mlsdは入力画像の直線を抽出して画像生成を行うモデルなので、もと画像を直線っぽいロボットくんにしています。


・control_v11f1p_sd15_depth
2023/06/18追加:プリプロセッサで処理した元画像が必要ですので、以下の例は失敗例の参考程度に考えてください。
depthは入力画像の深度情報使うモデルです。すみません🙇使い方が、よくわからないです。

・control_v11p_sd15_normalbae
2023/06/18追加:プリプロセッサで処理した元画像が必要ですので、以下の例は失敗例の参考程度に考えてください。
入力画像の法線情報を使っているそうです(^^;

・control_v11p_sd15_seg
2023/06/18追加:プリプロセッサで処理した元画像が必要ですので、以下の例は失敗例の参考程度に考えてください。
segmentationは元画像の色を分けて、分けた色から再描画してくれます。

・control_v11p_sd15_inpaint
2023/07/17追加:Mochi Diffusion v4.1からInPaintが使えるようになりました。(しかし、v4.1はモデルの切り替えをするとクラッシュしてアプリが落ちますので、しばらく様子見をした方が良いかもしれません。しかし、v4.1.1と v4.1.2はControlNetでうまく画像生成ができないようです。InPaintを行うならv4.1, そうでなければv4.0を使いましょう。v4.1.3で修正されました。)現在、ml-stable-diffusionではinpaint領域の認識ができないようで残念ながら使えません。
使い方ですが、エルフ耳になってしまった画像の耳の部分を修正する場合で説明します。(使用したモデルはcoreml/coreml-8528-diffusionです。)

まず、画像ソフトで修正前の画像にアルフファチャンネルを追加し、修正したい部分(マスクしたい部分)の値を0(透明)にして、アルファチャンネルを保持しつつPNG画像で保存します。
Macのプレビューを使った場合は、「マークアップツールバーを表示」ボタン(丸にペンのアイコン)を押すか、「表示」メニューの「マークアップツールバーを表示」を選んでマークアップツールバーを表示して、「選択ツール」や「インスタントアルファ」で、修正部分を選択してDeleteキーを押して透明にします。修正部分の指定が終わったら「ファイル」メニューの「書き出す…」でフォーマットをPNG、アルファにチェックを入れた状態で保存します。

保存したPNG画像をMochi DiffusionのControlNetの元画像に読み込んで、ContolNetの設定を「なし」→「InPaint〜」に変更して、「画像から除外」(Negative Prompt)に「elf ear」を追加して他は同じ設定で画像生成します。

ControlNetのInPaintはマスク部分を修正しますが、マスク以外の部分も修正されるので、寛容な❤️が必要かもしれません。今回の例では少し色が濃くなってボケてしまってます。
なお、マスクを追加したPNG画像ですが、自作MLアプリで作成できるようにもしています。
今回の例はこちらで、マスクを追加した画像を作っています。
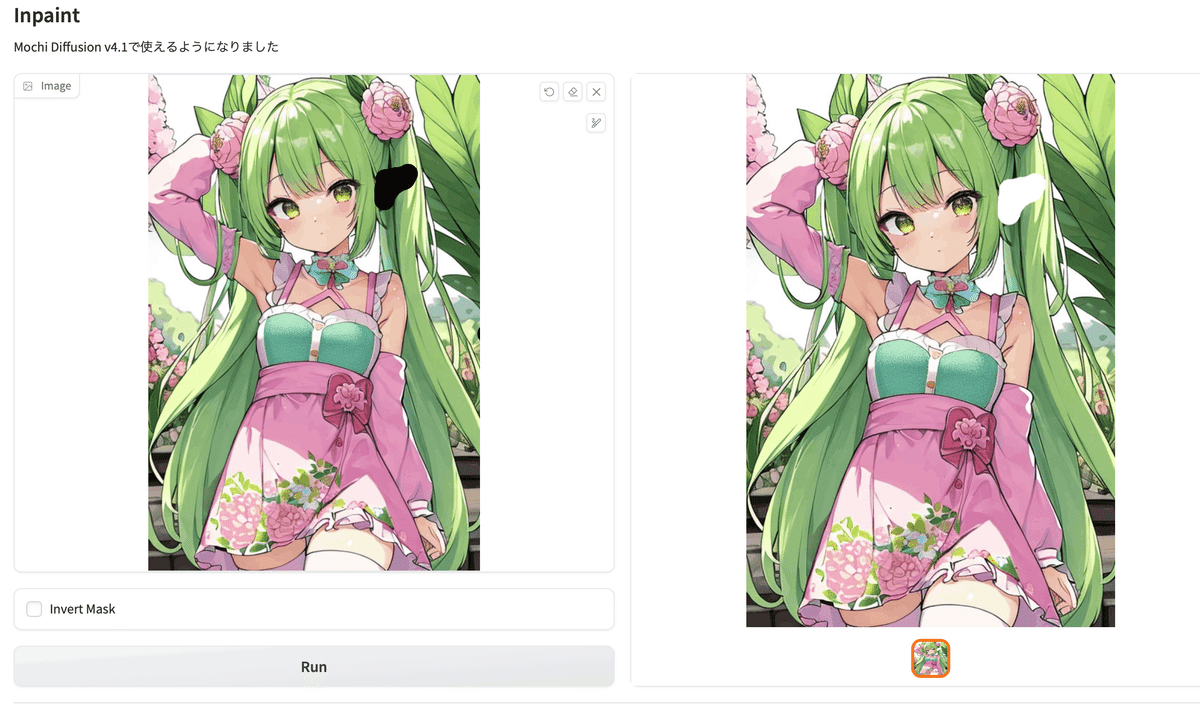
・左の元画像のマスクしたい部分を黒く塗りつぶして「Run」ボタンを押すとマスク部分を透明にしたPNG画像が生成されます。
・右の画像をダウンロードして、ControlNetの元画像に読み込んでください。
・control_v11p_sd15_lineart
元画像を線画にして、その線画を元に再描画してくれます。
2023/06/18追加:プリプロセッサで処理した元画像が必要ですので、以下の例は失敗例の参考程度に考えてください。

2023/06/17追加:元画像を色調反転(白黒反転やネガポジ変換)した画像にすると良くなるようです。

2023/06/18追加:色調反転した線画を元画像にすると、そこそこ良い画像が生成できるようです。


・control_v11p_sd15s2_lineart_anime
元画像をアニメ風線画にして、その線画を元に再描画してくれます。
2023/06/18追加:プリプロセッサで処理した元画像が必要ですので、以下の例は失敗例の参考程度に考えてください。

2023/06/17追加:元画像を色調反転(白黒反転やネガポジ変換)した画像にすると良くなるようです。

2023/06/18追加:色調反転した線画を元画像にすると、そこそこ良い画像が生成できるようです。

・control_v11p_sd15_openpose
ポーズをつけた棒人間の絵から、画像生成してくれます。
棒人間の元絵はMochi Diffusionでは作れないので、他のツールを使うか、ネットでサンプルを探すなどの必要があります。今回は、くろくまさんのサンプルを使わせて頂きました。m(_ _)m


・control_v11p_sd15_scribble
2023/06/18追加:プリプロセッサで処理した元画像が必要ですので、以下の例は失敗例の参考程度に考えてください。
これぞ本命❣️❓落書きから、画像を生成してくれます。


2023/06/18追加:色調反転した線画を元画像にすると、良い画像が生成できるようです。2023/06/17追加:元画像を色調反転(白黒反転やネガポジ変換)した画像にすると若干良く(元画像に近く)なるようです。

・control_v11p_sd15_softedge
2023/06/18追加:プリプロセッサで処理した元画像が必要ですので、以下の例は失敗例の参考程度に考えてください。
やわらかい輪郭線を抽出して、それを元に画像生成してくれます。

2023/06/17追加:元画像を色調反転(白黒反転やネガポジ変換)した画像にすると若干良くなるようです。

・control_v11e_sd15_shuffle
元絵を再構築してくれるそうです。未だ実験的機能とのことです。

・control_v11e_sd15_ip2p
Instruct Pix2Pixは、こういう風に書き換えて!と指示できるそうです。未だ実験的機能とのことです。boyとfire要素を加えてみました。

・control_v11f1e_sd15_tile
高解像にする際に、元画像のぼやけを取り除くようです。未だ実験的機能とのことです。

・Tileを使って今流行りの画風へ?
control_v11f1e_sd15_tileは元画像により書き込みを行う機能のようですので、これを何回も繰り返して今流行りの画風っぽくならないかと思って試してみました。下の10枚の画像は、上段の左端の画像にTile処理を行って上段左から2枚目の画像を生成して、2枚目の画像にTile処理を行ってというように繰り返した例です。モデルはSDHK v4.0を使っています。

Tile処理を繰り返すことで全体的に色が薄くなってくるようです。しかし、色は画像ソフトで修正可能なレベルだと思います。(プロンプトで髪の色を指定してないので、髪の色が変化しています。)モデルの違いや好みにもよると思いますが、私は4回目くらいで、そこそこ満足できる結果が得られたのではないかと思います。(しかし、今流行の画風とまでは言えないようです…)
次に、最初の画像にTile処理とMochi DiffusionのHD生成(RealESRGAN)を行った画像と、8回目の画像に同じ処理を行った場合(Tile処理は9回目)の例を以下に比べてみます。(下の画像は上の画像とシードの値が異なります。)


良し悪しの判断は難しいですが、Tile処理を多く行った画像の方がより細かくなっているような印象です。今流行りの画風にはなりませんでしたが、これでも良い感じです。
プリプロセッサで処理した画像の作り方
Hugging FaceにSpacesというMLアプリ(機械学習のデモwebアプリ)を公開する場があります。(Hugging Faceのアカウントがなくても利用可能です。)
2023/06/22:自作MLアプリについて追加
その1.プリプロセッサ処理された画像のみを生成するMLアプリを作りましたので公開します。(^^; (しかし、normalbaeは対応できていませんm(_ _)m)
GPUを使うMLアプリは実行するとGPUの使用時間に応じて作者に課金されますが、このMLアプリはGPUを使っておらず 私には課金が発生しませんので気軽に使ってください!(従って処理は遅いです…)
Mochi Diffusionなどで生成したHEICの画像はMLアプリで変換できませんので、あらかじめPNGかJPGへ変換した画像を使用してください。Macであれば画像を右クリック(副ボタンクリック)して出るメニューから「クイックアクション」-「イメージを変換」でPNGやJPGへ変換できます。

この画面はCannyの変換を行う部分で、変換元の画像を左の欄にドラック&ドロップして、「Run」ボタンを押して実行した結果です。右の欄に、Cannyのプリプロセッサで処理された線画が生成されます。線画は右クリック(副ボタンのクリック)で出るメニューからダウンロードできますので、この線画をMochi DiffusionのControlNetの元画像(Control画像)にできます。
ControlNet v1.1 Annotatorについては以下のURLに解説があります。
https://github.com/lllyasviel/ControlNet-v1-1-nightly/blob/main/github_docs/annotator.md
その2.Hugging Face SpacesにControlNet v1.1のMLアプリを公開されている方々がいます。これらは以下のURLで見れます。(Hugging Faceのアカウントがなくても利用可能です。)

これらの中で、Running状態になっているMLアプリを選びます。ちゃんと動作しないMLアプリもありますので、動作しない場合は他のMLアプリを試しましょう。
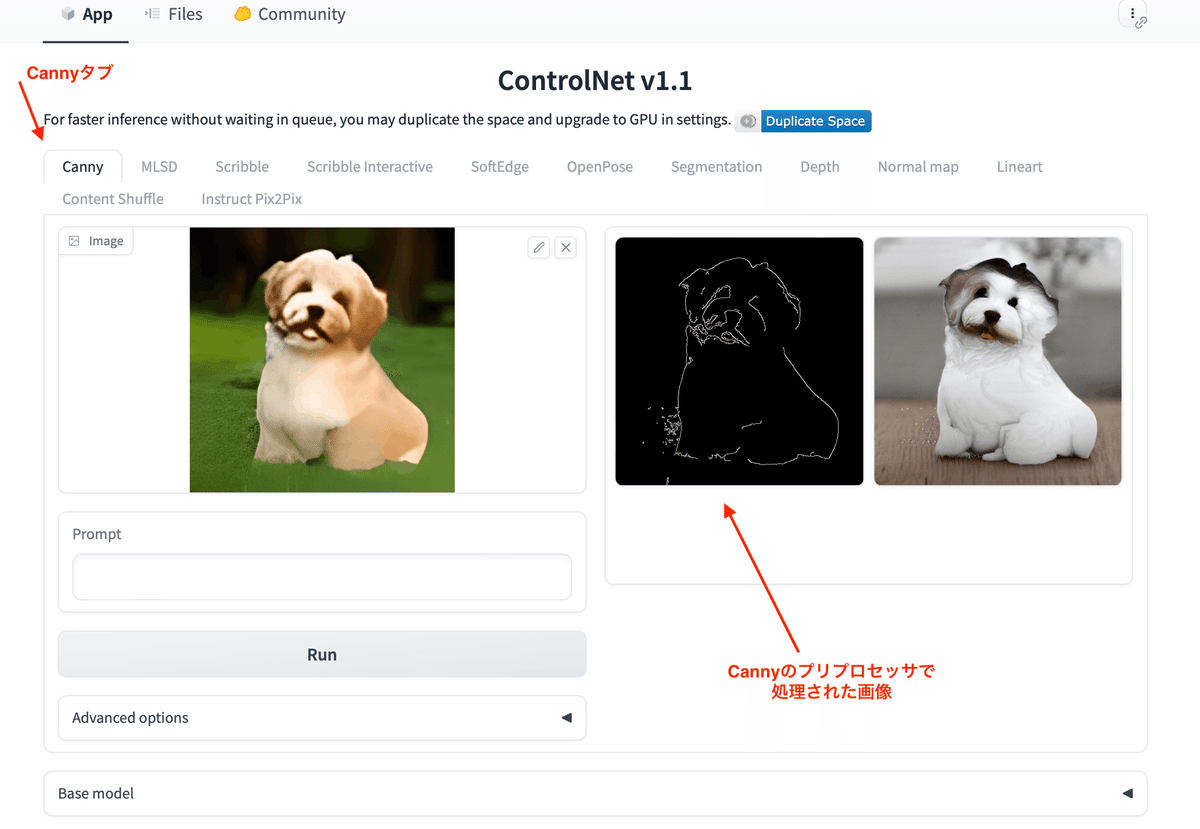
この画面はCannyタブを選んで、犬の画像を左の欄にドラック&ドロップして、「Run」ボタンを押して実行した結果です。右の欄に、Cannyのプリプロセッサで処理された線画と、この線画を元に生成された画像が並びます。線画は右クリック(副ボタンのクリック)で出るメニューからダウンロードできますので、この線画をMochi DiffusionのControlNetの元画像にできます。「Advanced options」ボタンを押すと細かい調整ができるメニューが表示されます。他のタブを選んでDepthなどの元画像(Control画像)を作ることもできます。
以上で、ControlNetの解説はおわりです。
おまけ
・ml-stable-diffusionのベンチマーク
ちょっと古い話ですが、Swift Core ML Diffusersは画像生成時間を計測できるようになっています。
この時間計測を使ったベンチマーク記事の発表や新機種でのベンチマークの募集があっていました。
記事の結果
Model name Benchmark M1 8 GB M1 16 GB M2 24 GB M1 Max 64 GB
Cores (performance/GPU/ANE) 4/8/16 4/8/16 4/8/16 8/32/16
Stable Diffusion 1.5
GPU 32.9 32.8 21.9 9
ANE 18.8 18.7 13.1 20.4
Stable Diffusion 2.1 Base
GPU 29.6 29.4 19.5 8.3
ANE 14.3 14.3 10.5 15.3
https://github.com/huggingface/swift-coreml-diffusers/issues/31
ベンチマークの募集の結果を書き出すと以下のようになっています。
・Macbook Pro 14" M1 Pro GPU 16 Cores - 16GB of ram - 8 perf cores
ANE: 15.4s, 15.2, 15.2
GPU: 13.7s, 13.9s, 13.7s (Using less than 4GB of ram 🤯)
GPU + ANE: 15.4, 15.2, 15.4
・Macbook Pro 14" with M1 Pro GPU 16 Cores - 16GB of ram - 8 perf cores
ANE: 15.2, 15.1, 15.3
GPU: 13.9, 13.7, 13.7
GPU + ANE: 14.2, 14.5, 14.4
・14" MacBook M1 Pro - 14 GPU cores / 6 performance cores - All settings default (SD 2-base)
ANE: 15.2, 15.2, 15.2
GPU: 15.1, 15.1, 15.2
ANE+GPU: 14.4, 14.5, 14.4
・MacBook Pro 16" with M1 Pro | CPU: 10 cores (8 performance and 2 efficiency) | GPU: 16 Cores | Memory: 16 GB
GPU: 14.4 / 13.8 / 13.6
ANE: 15.0 / 15.0 / 15.0
GPU+ANE: 14.3 / 14.2 / 14.3
・MacBook Pro 16" with M1 Max 10-core CPU (8P,2E) 24-core GPU 16-core, 11 Tops Neural Engine 32GB Unified Memory
GPU: 9.9 / 10.0 / 9.7 / 9.7s
GPU Power: ~28W
ANE: 14.1 / 14.3 / 14.4 / 14.4s
ANE Power: ~3.1W
GPU + ANE: 13.5 / 13.6 / 13.5 / 13.5s
GPU + ANE Power 5.3w
・Mac Mini with M2 Pro GPU 16 Cores - 16GB of ram - 6 perf cores
ANE: For some reason, on this machine the ANE was the default: 10.4, 10.3, 10.4 (no ram usage reported?!)
GPU: 12.4s, 12.3s, 12.3s
ANE+GPU: 10.9, 10.8, 10.8・MacBook Pro 14-inch, 2023; Apple M2 Pro, 8-P-Core, 4-E-core, 19-GPU-core; 32GB Memory
Model: stable-diffusion-2-base
Guidance Scale: 7.5
Step count: 25
GPU: 11.0s, 11.1s, 11.0s
ANE: 10.6s, 10.8s, 10.7s,
GPU+ANE: 10.5s, 10.4s, 10.7sLow Power Mode: On
GPU: 12.7s, 12.5s, 12.5s
ANE: 11.3s, 11.2s, 11.1s
GPU+ANE: 10.8s, 11.3s, 11.4s・Macbook Pro 14" with M2 Pro 12-Core CPU, 19-Core GPU, 32GB Unified Memory
GPU: 11.4, 11.2, 11.2
ANE: 10.3, 10.2, 10.3
GPU+ANE: 10.4, 10.3, 10.2
・14" MacBook M2 Max - 64 GB - 30 cores
GPU: 7.7, 7.7, 7.6
ANE: 10.3, 10.3, 10.3
GPU + ANE: 10.6, 10.6, 10.7
・Macbook Pro 14" with M2 Max 12-Core CPU, 38-Core GPU, 16-core Neural Engine, 96GB Unified Memory
GPU: 6.5, 6.4, 6.5, 6.6, 6.5
ANE: 10.2, 10.3, 10.2, 10.3, 10.2
GPU+ANE: 9.9, 9.9, 10.0, 9.8, 10.0
・MacBook Pro 16" with M2 Max 12-Core CPU, 38-Core GPU, 16-core Neural Engine, 64GB Unified Memory
GPU: 6.2 / 6.2 / 6.2 / 6.2
ANE: 10.1 / 10.2 / 10.2 / 10.1
GPU + ANE: 9.8 / 9.7 / 9.7 / 9.8
ざっくりみると、画像サイズ512x512、25Stepで画像生成するのに、
M1ではNEで約15秒、GPU(14Core)で15秒弱、
M2ではNEで約10秒強、GPU(19Core)で11秒位
でしょうか。GPU + NE(全て)だと遅い方に引っ張られてしまうようです。
M3が楽しみですねー(いつ出るのかなー)
更新履歴
2023/06/17:色調反転した画像を元画像にする方が良い場合がある件追加
勘違いがあるようなので注意追加
2023/06/18:プリプロセッサで処理済みの元画像が必要である件追加
2023/06/19:「プリプロセッサで処理した画像の作り方」を追加
2023/06/22:自作MLアプリについて追加
2023/06/25:自作MLアプリでnormalbaeも対応しました。
2023/06/30:ControlNetモデルの配布先を変更しました。
2023/07/03:SDHKの変換済みCoreMLモデルの配布先を追加
2023/07/08:・Tileを使って今流行りの画風へ?を追加
2023/07/17:InPaintの情報更新と使い方を追加
2023/07/21:Mochi Diffusion v4.1.2でモデル切替のクラッシュ修正されました
2023/07/22:Mochi Difusion v4.1.1, v4.1.2でのControlNetの不具合について追加
v4.1.3のControlNetの不具合修正を追加
2023/07/23:v4.1.3のControlNetについて注意を追加