
Macで簡単 AI画像生成 -Core MLモデル変換編-(未経験者向け)

まえがき
本記事は"ターミナル"を使ったことのない未経験者の方に向けた記事です。
appleのml-stable-diffusionでは、.ckptや.safetensorsの拡張子を持つファイルで配布されているモデルが直接使用できず変換したモデルを使わなければなりません。代表的なモデルであれば、Core ML Models Communityに変換されたモデルがあるかもしれませんが、変換済みのモデルがない場合には、自分でCore MLモデルへ変換する必要があります。本記事は、自分でCore MLモデルへ変換する方法について解説します。変換するためには"ターミナル"を起動してコマンドを入力する必要がありますが、未経験者向け記事ですので、この辺りも詳しく説明しようと努力してみました。
注意:モデルの変換にはシステムディスクの空き容量が15G位?50GB程必要だと思います。(2023/05/05:現時点でのシステムディスクの空き容量変更)また色々なモデルを変換していると、すぐ「ディスクの空き容量が不足しています!」のエラーが出ますので、ディスクの空き容量は多めに確保をお願いします。(2023/03/22追記)MacBookでTimeMachineを使っている場合は、APFSスナップショットが作成されます。APFSスナップショットはモデル変換の際には自動削除されないようです。ディスクユーティリティで確認して古いAPFSスナップショットが空き容量に影響しているようであれば、TimeMachimeでバックアップした後に、古い方のスナップショットを選択してAPFSスナップショット一覧の左下にある「ー」ボタンを押して削除しましょう。

基本的な変換方法は、以下のml-stable-diffusionに解説があります。
必要な環境(ツールとバージョン)
Pythonは3.8、macOSは13.1以上、Xcodeは14.2以上です。
下準備:必要なツールのインストール
・Xcodeのインストール
Mochi DiffusionのようなMacOSアプリケーション用のモデルを変換するには、Xcodeをインストールしなければなりません。インストールは、App Storeを起動して検索ボックスにxcodeと入力します。検索結果からXcodeを開いて、「入手」ボタンを押します。(App StoreでXcodeのサイズは7.8GBと書いてありますが、私のMacBook AirのXcodeは現在12GBに膨れてます。空き容量はXcodeの分も考慮してください。)

(既にインストール済みなのでボタンが開くに変わっています。)
・コマンドラインツールのインストール
Homebrewという、Macが標準で持っていないUnixコマンドを追加してくれるツールをインストールします。もし、Homebrewを既にインストール済みの方は、ここのインストールの説明部分はスキップしてください。
まず、「アプリケーション」フォルダの「その他」(または、「Dock」の「Launchpad」の「その他」)の中にある"ターミナル"を立ち上げます。そして、ターミナルにHomebrewのページにあるインストールコマンドをコピーボタンでコピーして、ターミナルにペーストしreturnキーを押します。下に同じコマンドを置きますので、ここからコピーしても大丈夫です。
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"Homebrewのインストールが終わったら、必要なツールを以下のコマンドでインストールしていきます。
brew install wgetbrew install python@3.10brew install --cask miniforge(2023/04/29追記:ごめんなさーい。以下のコマンドは間違いでした。上のminiforgeをインストールするコマンドを実行してください。)brew install --cask anaconda
念の為に以下のコマンドも実行してXcode.appに含まれているコマンドが使用されるようにしましょう。(このコマンドを実行すると、管理者パスワードの入力を求められますので、ご自分のログイン パスワードを入力してください。)
sudo xcode-select -switch /Applications/Xcode.app/Contents/Developer以上で、第一の下準備は完了です。
・ml-stable-diffusionのインストール
ここからは、ml-stable-diffusionの解説に習って進めていきますが、解説には抜けている部分がありますので、補足しながら説明します。
以下のコマンドで"coreml_stable_diffusion"というPythonの実行環境を作り、それをアクティブにします。("coreml_stable_diffusion"はお好みの名前に変更可能です。)
conda create -n coreml_stable_diffusion python=3.8 -yconda activate coreml_stable_diffusion 続いて、ml-stable-diffusionをダウンロードします。ml-stable-diffusiomを保存するフォルダを作ってターミナルの実行場所を"cd"コマンドで作成したフォルダに移動します。
例えば、書類(Documents)フォルダに"StableDiffusion"というフォルダを作っておいて、そこに、保存するのであれば、ターミナルで以下のコマンドを実行して移動します。
cd ~/Documents/StableDiffusionそして、ml-stable-diffusionをダウンロードする以下のコマンドを実行します。
git clone https://github.com/apple/ml-stable-diffusionそして、以下のコマンドを実行すると、ml-stable-diffusionと必要なツールがインストールされます。最後のドットを忘れないよう気をつけてください。
cd ml-stable-diffusionpip install -e .注意:ml-stable-diffusionフォルダはインストールが終わっても削除しないようご注意ください。
ml-stable-diffusionのインストールが終わったら、.ckptや.safetensorsファイルからモデル変換するために必要なツールを、以下のコマンドを実行して追加しましょう。
pip install omegaconfpip install safetensors以上で、下準備は全て終了です。
2023/06/12注意追加:diffusersのバージョン0.17.xではCoreMLモデルの変換が上手くできないようです。現在、上記の下準備でツールをインストールした場合は、以下のコマンドを実行してdiffusersのバージョンダウンを行なってください。pip install diffusers==0.16.1昔インストールしてdiffusersバージョンが0.17.xより前の場合はこの対応は不要です。2023/06/15注意削除:本日ml-stable-diffusionがアップデートされて上記対策は必要なくなりました。2023/04/28注意追加:diffusersのバージョン0.16.0, 0.16.1ではCoreMLモデルの変換が上手くできないようです。現在、上記の下準備でツールをインストールした場合は、以下のコマンドを実行してdiffusersのバージョンダウンを行なってください。
pip install diffusers==0.15.1
昔インストールしてdiffusersバージョンが0.16.0より前の場合はこの対応は不要です。
2023/05/14注意追加:Transformers のバージョン4.29.1ではTextEncoderが変換できないようです。最近変換ツールをインストールして問題のある方は、以下のコマンドを実行して、Transformersのバージョンダウンをお願いします。昔インストールしてTransformersバージョンが4.28.1以前の場合はこの対応は不要です。2023/05/16注意削除:本日ml-stable-diffusionがアップデートされてTransformersの対策は必要なくなりました。
pip install transformers==4.28.1
2023/04/30注意削除:本日ml-stable-diffusionがアップデートされてdiffusersの対策は必要なくなりました。しかし、2023/04/30現在のml-stable-diffusionとdiffusers v0.16.1を使ってCoreMLモデルを変換すると、古いSwiftアプリケーションでimage2image(i2i)ができなくなるようです。なお、Mochi Diffusionであればv3.2を使えばi2iできますが、昔変換したCoreMLモデルを使ってi2iをするとMochi Diffusion v3.2がクラッシュしますので、昔のモデルでi2iを行う場合はMochi Diffusion v3.1を使ってください。
補足:ちなみに、diffusersなどインストールされているツールのバージョンを知りたい場合は以下のコマンドで確認できます。
pip list補足:何か失敗した!と思ったらPython実行環境は以下のコマンドで削除できますので、一旦削除してPython実行環境の作成からやり直すことができます。
注意:以下のコマンドはやり直す時だけ実行してください。
conda remove -n ml-stable-diffusion --allモデルについての予備知識
・Stable Diffusionモデルの種類
Stable Diffusionで使われているStable Diffusion(SD) モデルの種類として、主に3つのモデルがあります。それぞれの特徴を以下に示します。
SD1.4, SD1.5 :768次元 , 画像サイズ512x512, epsilon予測
SD2.0base, SD2.1base. :1024次元, 画像サイズ512x512, epsilon予測
SD2.0, SD2.1 :1024次元, 画像サイズ768x768, v予測
(SD1.4とSD1.5、SD2.0baseとSD2.0base、SD2.0とSD2.1は大きな違いはありません。)これらの中で、ml-stable-diffusionが対応しているのは、Mochi DiffusionのようなMacOS用のアプリケーションソフトだと、SD1.4, SD1.5, SD2.0base, SD2.1baseになります(SD2.0, SD2.1は画像生成できません)。ml-stable-diffusionのPythonコマンドを使って画像生成するのであれば、SD2.0, SD2.1も対応しています。現在は未だSD1.xのモデルが多く配布されていると思います。
・モデルの配布形態
モデルは、HagginFaceでdiffusersモデル(unet, vaeなどのフォルダ構成での配布)の形と、学習データのチェックポイント(check point)を1つのファイルに保存した.ckptや.safetensors(.ckptより安全性を増した形式)の形で配布されています。.ckptと.safetensorsファイルは、float32やfloat16のデータ、追加学習用のデータ(ema)を含んだり含まなかったりと利用目的により色々とあります。
Core ML用へ変換するには、float32(一般的に名前にfp32が付加されている、ファイルサイズが大きい方)で、学習用データや画像生成に必要ないデータを含まない(名前に"no_ema", "pruned"など追加されています)ファイルを選びましょう。しかし、そのような情報を含んだ名前を付けてない場合も多いので、その際はファイルサイズが大きい目(約3〜5GB程度)のモデルを選びましょう。
・モデルの探し方
モデルはHugging FaceやCivitaiで配布されていますが、Civitaiのモデルは複数のモデルを結合したマージモデルやFT(ファインチューニング)したモデルが多いのでCore MLモデルへ変換しても画像生成がうまくいかない場合があるかもしれません。なお、LoRAモデルやControlNetモデルはCore MLモデルの変換元には使えません。ご注意ください。
・Hugging Faceでの配布例
モデルがHugging Faceにあって、作者がunetやvaeなどのdiffusersフォルダにデータを保存している(フォルダの横に最新の更新内容が出ますので、それをみて判断できます)diffuserモデルを提供している例です。今回は以下のモデルを使って説明します。(このモデルは、Core ML Models Communityのcoreml/coreml-waifu-diffusion-v1-4で変換済みのモデルを配布しています。)
上のURLを開くと、下のような画面になります。
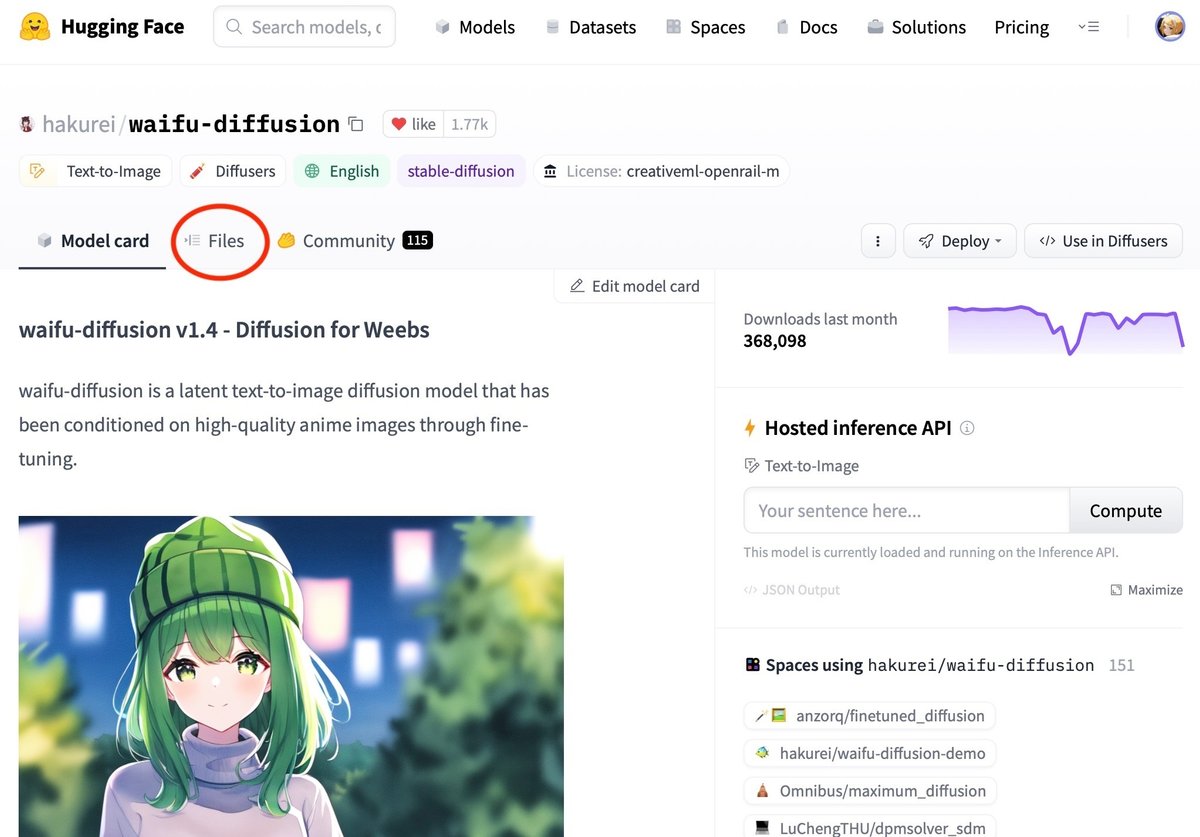
この画面で、赤い丸部分の「Files」タブをクリックすると、下のようになります。

2023年のお正月にwd1.4e1が配付されましたので、diffusersフォルダ(vae, unetなどのフォルダ)の説明は1.4 anime model追加、日付は2ヶ月前になっています。(これは、記事作成中の2023/3/12での表示です。2023/03/13に各フォルダ内に.safetensorsファイルが追加されてますので、若干変わっています。)このページでは.ckptや.safetensorsファイルは配布されていません。これらのファイルは別のページhakurei/waifu-diffusion-v1-4で配布されています。

ここで、注意が必要です。waifu-diffusion-v1-4のモデルの名前に1-4とありますが、これはSD1.4のモデルではありません。waifu-diffusion-v1-4はSD2.1baseなのですが、ページ内を見ても説明がないので判断が難しいと思います。
・SDモデルの見分け方
この画面ではckptと一緒に.yamlというファイルがあります。現在、この.yamlファイルがあるとSD2.xbase、SD2.xである可能性が高いです。
.yamlファイルをクリックして中身を確認して、「context_dim: 1024」という1024次元のパラメータがあればSD2.xbaseかSD2.xで「parameterization: "v"」というv予測のパラメータがあればSD2.xのモデルです。
diffusersフォルダでは、「unet」フォルダの中にある「config.json」ファイルの中に「"cross_attention_dim": 1024」の設定があれば、SD2xbaseかSD2xです。そして「scheduler」フォルダの「scheduler_config.json」ファイルの中に「"prediction_type": "v_prediction"」の設定があればSD2.xです。
これらに当てはまらない場合はSD1.xです。
Core MLモデルの変換例
・Hugging Faceからの変換
変換用のコマンドは、下のサンプルのように長いので、テキストエディタを使って目的のモデルを変換するコマンドを事前に作成することをお勧めします。
python -m python_coreml_stable_diffusion.torch2coreml --convert-unet --convert-text-encoder --convert-vae-decoder --convert-vae-encoder --convert-safety-checker --bundle-resources-for-swift-cli --model-version <pre-trained model checkpoint> -o <output-mlpackages-directory>
ここで、2つの<>の指定は、以下のように変更します。
<pre-trained model checkpoint>:変換するモデルの場所を指定する。
<output-mlpackages-directory>:変換されたモデルの保存場所を指定する。
<pre-trained model checkpoint>は、変換元のモデルデータが含まれているローカルのフォルダを指定しても良いですし、Hugging Faceのページのモデル名(hakurei/waifu-diffusionなど)でも良いです。モデル名はHugging FaceのページにはモデルタイトルとLike数表示の間にコピーボタンがありますので、それからコピーします。

例えば、hakurei/waifu-diffusionからモデルを入手して、書類フォルダに作成したStableDiffusionフォルダに新たにwd1.4e1_coremlというフォルダを作成して変換したモデルを保存する場合のコマンドは、以下のようになります。(コマンドを実行すると「wd1.4e1_coreml」フォルダが自動で作成されます。)
python -m python_coreml_stable_diffusion.torch2coreml --convert-unet --convert-text-encoder --convert-vae-decoder --convert-vae-encoder --convert-safety-checker --bundle-resources-for-swift-cli --latent-w 64 --latent-h 64 --model-version hakurei/waifu-diffusion -o ./wd1.4e1_coreml
"--latent-w 64 --latent-h 64"のオプションですが、これは生成する画像サイズの指定になります。ml-stable-diffusionでは画像生成時に画像サイズを指定できませんが、モデルの変換時に"--latent-w"と"--latent-h"で幅と高さの指定をして、モデル自体の画像サイズを変更することで画像サイズを変更します。これらのオプションで指定した値の8倍の画像が生成されますので、この例では、64×8=512で、幅x高さが512x512の画像を生成する例になります。「--latent-w 64 --latent-h 96」とすれば、幅512、高さ768の画像を生成するモデルが作れます。たまに、変換元のモデルのunetの設定でサイズがが間違っているモデルがあるので、512x512の標準画像サイズのモデルを作成する際も指定しておいた方が安全です。なお、幅と高さが異なる画像を生成する際には、画像生成ソフトの設定をCPU & GPUにする必要があり、且つ変換するコマンドにはGPU専用のモデルを作成するオプション"--attention-implementation ORIGINAL"を追加しなければなりません。
また、今のところ96(768)を超える値での画像生成は難しいそうです。高性能Macでなければ512x512が最適です。私のMacBook Air M2 RAM 8GBでは、512x768, 768x512もなんとか生成できます。
※変換前の準備(儀式?)(2023/05/05:現時点でのPython使用メモリ変更)
Core MLモデル変換時には、Python3.8がピークで約10GB40GB超のメモリ使用に低減されてますので儀式は必要ないかもです。ので、大容量メモリを搭載したMacであれば問題ないかもしれませんが、普通のMacであればかなり苦しい作業になります。テキストエディタで変換コマンドを一旦保存して、TimeMachineを使っているのであれば、バックアップを完了して、全てのアプリケーションを終了した状態で、システムディスクの空き容量が50GB以上あることを確認して(念のため一度Macを再起動しましょう(^^; )。
Macが起動して、他のアプリケーションが立ち上がってないことを確認して、先ほどのコマンドを保存したテキストエディタとターミナルのみを立ち上げます。ターミナルはCore MLモデル変換用のPython環境へ切り替える必要があります。モデル変換を行うPython環境へ切り替えるには前に使った、以下のコマンドを実行してください。(環境名を変更した場合は変更した環境名で置き換えてください。)
conda activate coreml_stable_diffusionml-stable-diffusionの解説では、ここでHugging Faceの「huggingface-cli login」でHugging Faceのアカウントでログインするよう説明されていますが、最近ダウンロードのみであれば不要になったという噂ですので、ここは飛ばします。(間違っていたらごめんなさい。必要であればHugging Faceのアカウントを作成して「huggingface-cli login」でログインしてください。)
そして、テキストエディタから下記のコマンドをコピーして、ターミナルにペーストします。
cd ~/Documents/StableDiffusionpython -m python_coreml_stable_diffusion.torch2coreml --convert-unet --convert-text-encoder --convert-vae-decoder --convert-vae-encoder --convert-safety-checker --bundle-resources-for-swift-cli --latent-w 64 --latent-h 64 --model-version hakurei/waifu-diffusion -o ./wd1.4e1_coremlreturnキーを押して実行すると、Hugging Faceからhakurei/waifu-diffusionのdiffusersのデータが、~/.cache/huggingfaceという不可視フォルダの中にダウンロードされて、Core MLモデルの変換が始まります。Core MLモデルとしてはunet、text-encoder、vae-decoder、vae-encoder、safety-checkerのモデルが変換されます。変換の途中でエラーで止まっても、再度同じコマンドを実行するとエラーで止まった時点から再開されますので安心してください。
変換が終わるとwd1.4e1_coremlフォルダの中にResourcesフォルダと拡張子が.mlpackageのファイルができています。Pythonコマンドで画像生成をしないので、.mlpackageファイルはゴミ箱へ捨てましょう。
Mochi DiffusionなどのアプリケーションはResourcesフォルダの中に入っているファイルを利用します。これらのファイルをアプリケーションが指定しているモデルフォルダに新しいフォルダを作成(新しいフォルダの名称は非アスキー文字を含んではいけません)して、その中に移動すれば変換モデルが使えるようになります。個々のファイル移動が面倒だと思う方は、以下のコマンドを実行してから、wd1.4e1_coremlフォルダをアプリケーション指定のモデルを保存するフォルダへ移動しましょう。
~/Documents/StableDiffusion/wd1.4e1_coremlln -s Resources/* ."ln -s"はシンボリックリンクというファイルへのリンク(エイリアスのような物)を作成するコマンドです。(最後のドットを忘れないようご注意ください。)この"ln -s Resources/* ."コマンドで、Resourcesフォルダ中のファイルのリンクがResourcesと同じ場所に作成されます。(ml-stable-diffusionはモデルフォルダ内の決まった名前のファイルを読み込みますので、他の名前のフォルダやファイルがあっても無視されます。)
.ckptや.safetensorsファイルからの変換
Hugging Faceでもdiffusersフォルダが最新でなく.ckptや.safetensorsだけ最新になっているモデルを変換したい場合を使って方法を解説します。hakurei/waifu-diffusion-v1-4では、wd-1-4-anime_e1より新しいwd-1-4-anime_e2.ckptが配布されていますので、このファイルとwd-1-4-anime_e1.yamlファイルを~/Documents/StableDiffusion/ダウンロードした場合を例に説明します。wd-1-4-anime_e2.ckptはemaなどについては不明ですがファイルサイズが5GB程度あるのでfloat32のモデルだと推測できます。
まず、.ckptや.safetensorsからdiffusersフォルダへ変換するPythonコマンドをダウンロードするため、以下のURLのファイルを~/Documents/StableDiffusion/へ保存します。
保存時の拡張子が.txtになっていれば、拡張子を.txtから.pyへ変更します。
wd-1-4-anime_e2.ckptとwd-1-4-anime_e1.yamlも同じ場所に保存します。
wd-1-4-anime_e2.ckptはCore MLモデルと同じ手順でダウンロードします。wd-1-4-anime_e1.yamlファイルは、リンクをクリックした後に表示されるページの「</>raw」(下図の赤線部分)の「raw」のリンクをクリックしてテキスト表示に切り替えてから、ファイルメニューの「別名で保存」で保存します。これも保存したファイルの拡張子が.txtになっていれば.yamlへ変更します。
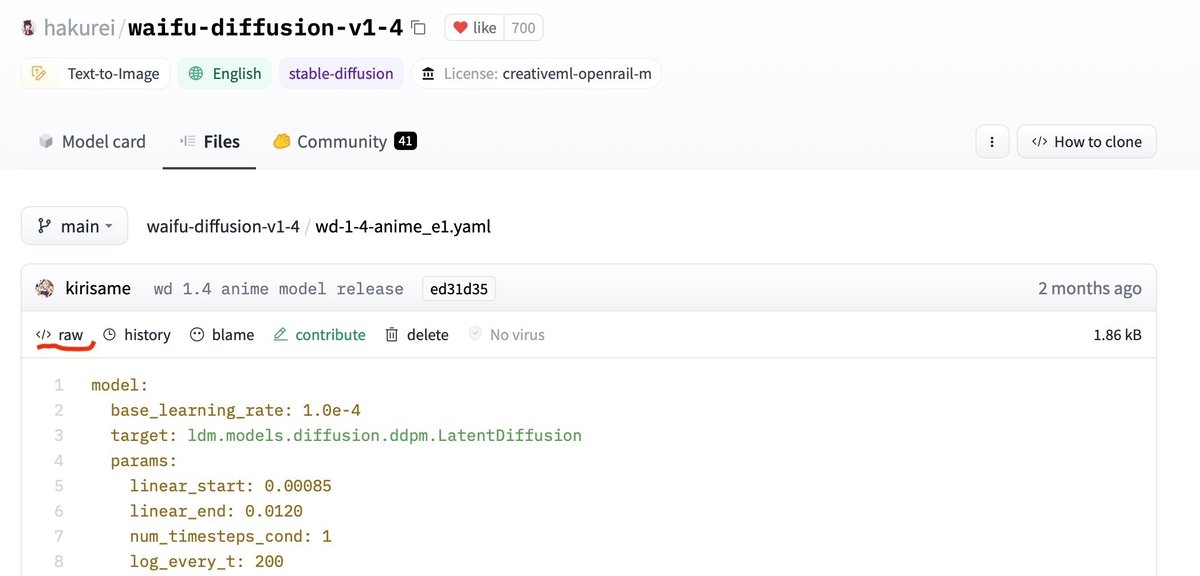
(raw表示切り替えリンク下に赤線)
.ckpt .safetensorsからdiffusersフォルダへの変換はそれほどメモリは消費しないので、アプリをすべて終了する必要はないと思います。
ターミナルを立ち上げて、以下のコマンドを実行します。wd1.4e2_diffusersフォルダは自動で作成されます。
cd ~/Documents/StableDiffusionconda activate coreml_stable_diffusion (Python環境名を変更した場合は変更した環境名で置き換えてください。
※2023/04/18:Python環境への切り替えコマンドを追加)
python ./convert_original_stable_diffusion_to_diffusers.py --checkpoint_path ./wd-1-4-anime_e2.ckpt --original_config_file ./wd-1-4-anime_e1.yaml --device cpu --extract_ema --dump_path ./wd1.4e2_diffusers --upcast_attention 応用として.safetensorsファイルからの変換であれば"--from_safetensors"オプションを追加します。
SD1.xの.ckptや.safetensorsを変換する場合は"--original_config_file wd-1-4-anime_e1.yaml"と"--upcast_attention"は削除しましょう。
変換がうまく行ったら、次はCore MLモデルの変換を行います。この場合のコマンドは以下のようになります("--model-version"の指定がローカルのフォルダ"./wd1.4e2_diffusers"になります)。
python -m python_coreml_stable_diffusion.torch2coreml --convert-unet --convert-text-encoder --convert-vae-decoder --convert-vae-encoder --convert-safety-checker --bundle-resources-for-swift-cli --latent-w 64 --latent-h 64 --model-version ./wd1.4e2_diffusers -o ./wd1.4e2_coreml変換が問題なく終わったら、「・Hugging Faceからの変換」と同様にアプリケーションが使えるように変換済みのモデルフォルダ内のファイルを変更します。
wd-1-4-anime_e2.ckptから変換したモデルを使って画像生成してみると、wd1.4e1とはかなり雰囲気が違う画像が生成されると思います。これは、配布されている.ckpt,.safetensorsファイルの中に含まれていないtext_encoderなどのデータが、Hugging Faceのデフォルトデータで補完されてしまうからです。wd1.4e2はデフォルトのText Encoderとのマッチングが悪いので、生成される画像に「なにか違う感」がでます。
この対策として、前に変換したwd1.4e1のTextEncoder.mlmodelcをコピー&ペーストして(wd1.4e2のTextEncoder.mlmodelcは名前を変えるかゴミ箱へ送って)wd1.4e1のTextEncoder.mlmodelcを使うと、それらしい画像が生成できるようになります。
・メモリ不足の対策
私はMacBook Air M2 RAM 8GBで変換していますが、ディスクの空き容量を十分確保して実行してから実行するので、メモリ不足で変換できなかったことはありせん。しかし、ml-sable-diffusionのFAQでは メモリが足りずに変換が上手くいかない場合の対策が掲載されてます。その方法は、unet, text-encoder, vae-decoder, vae-encoder, safety-checkerの変換を下のコマンドのように個別で実行できるように変更すれば良いようです。FAQには各コマンドを"&& \"でつなぐように記載されていますが、コマンド自体が長いので、個別に実行した方が良さそうです。
python -m python_coreml_stable_diffusion.torch2coreml --convert-vae-encoder 〜
python -m python_coreml_stable_diffusion.torch2coreml --convert-vae-decoder 〜
python -m python_coreml_stable_diffusion.torch2coreml --convert-unet 〜
python -m python_coreml_stable_diffusion.torch2coreml --convert-text-encoder 〜
python -m python_coreml_stable_diffusion.torch2coreml --convert-safety-checker 〜
補足:変換したモデルが増えるとディスクスペースが不足してきますので、~/.cache/huggingfaceという不可視フォルダの中に溜まっているフォルダを削除しましょう。ファインダーの「移動」メニューの「フォルダに移動…」を選んで、~/.cache/huggingfaceを入力すると、ファインダに表示されます。
以上で、Core MLモデルの変換方法についての解説はすべておわりです。
変換したモデルの不具合と対策
・ぼやけた画像が生成される
モデルによってステップ数が低い場合の画像の生成されやすさが変わりますので、ステップ数はそれなりに増やしてください。
・画像に「なにか違う感」を感じる
.ckptや.safetensorsファイルで、変換元のモデルがfloat16であった場合や元のモデルがTextEncoderも学習していた場合に起こります。これはdiffusersフォルダで配布されている場所やfloat32のモデルを探す、モデル向けに学習されたTextEncoderのデータを探して組み合わせる必要があります。
・生成された画像の色が薄くなる

NE(Neural Engine)を使った場合に薄い色の画像が生成されるのであれば、NEを使わずCPU & GPUで画像生成するか、NEを使っても正常な色の画像生成ができる他のモデルのVAEDecoder.mlmodelcを使用すれば直ることがあります。
新しい対処法を見つけたので追加します。(2023/03/18)
ターミナルで問題のあるモデルのフォルダの中へ移動して
以下のコマンドを実行します。
cd VAEDecoder.mlmodelcmv model.mil ../model.mil.vaedecoderln -s ../model.mil.vaedecoder model.mil変更を行なったモデルの名前を対処済みであることを分かるように変更します。例えばモデル名の最後に「.fix」を付けるなどしましょう。
これで、なぜ直るのかは不明です。(^^;
・真っ黒の画像が生成される。
セーフティ チェッカー モジュールを使用している場合は正常な動作かもしれません。NEを使うと問題なく画像生成されるのに、GPUを使うと真っ黒な画像が生成されるのであれば、これは変換されたモデルの精度(precision)不足の可能性が高いです。Core MLモデルはfloat16なので、変換元のfloat32モデルより精度が不足し、GPUで演算エラーが起こって真っ黒な画像が生成されます。これはGPUは諦めてNEを使って画像生成しましょう。(この場合、float32のCore MLモデルを変換して、GPUで正常に画像生成するようにもできますが、float32モデルではNEが使えずモデルのファイルサイズも大きくなるので、NEで画像生成する方が良いと思います。)
・CLIP問題の修復について
最近のマージモデルを色々と試していたところ、昔あった、(といっても2-3ヶ月前位ですが…2023/04/18現在)「何か違う感」を感じるモデルがありません。新しいバージョンのdiffusersでは何か問題が解決されたのかもしれません。しかし、未だCLIP問題を持ってるモデルもあるようですので、CLIP問題の修復方法について説明します。CLIP問題についての詳細は、まゆひらさんのnote記事を参照お願いします(^^;
修復方法ですが、まゆひらさんのnote記事の中にあるbbcmcさんのnote記事#3の中にあるfix_postion_ids.pyをダウンロードします。
ダウンロードした、fix_postion_ids.pyを.ckptや.safetensorsのモデルファイルの保存場所(書類フォルダのStableDiffusionフォルダ)に移動して、ターミナルを起動して、以下のコマンドを実行します。
cd ~/Documents/StableDiffusionconda activate coreml_stable_diffusion (Python環境名を変更した場合は変更した環境名で置き換えてください。)
モデルの破損状況を以下のコマンドを実行して確認します。xxxxx.ckptはチェックしたいモデル名に変更してください。(チェックができるモデルはSD1.xのみのようです。)
python ./fix_position_ids.py --verbose --model xxxxx.ckpt破損している場合は、以下のコマンドで修復します。
python ./fix_position_ids.py --model xxxxx.ckpt --out xxxxx.fix.ckpt修復したxxxxx.fix.ckptを使って、CoreMLモデルへ変換します。以上です。
更新履歴
2023/03/18:「・生成された画像の色が薄くなる」に対処方法を追加
2023/03/22:APFSスナップショットへの対処を追加
2023/04/18:「・CLIP問題の修復について」を追加
2023/04/28:diffusersバージョンの注意追加
2023/04/29:コマンドの間違い修正
2023/04/30:4/28の注意を削除
2023/05/05:現時点のバージョンのdiffusersなどツールを使用した場合の
必要ディスク、メモリなどの修正🎏
2023/05/14:Transformersバージョンの注意追加
2023/05/16:5/14の注意を削除
2023/06/12:diffusersバージョン0.17.xの注意追加
2023/06/15:6/12の注意を削除
この記事が気に入ったらサポートをしてみませんか?