論文解説 : Janus-Pro: Unified Multimodal Understanding andGeneration with Data and Model Scaling


arxiv : https://arxiv.org/abs/2501.17811
code : https://github.com/deepseek-ai/Janus
ひとことまとめ
Janusの学習を最適化・データ増強・モデルのスケールアップを行うことで、マルチモーダルな理解とtext-to-image生成で大きな性能向上を実現した
概要
近年の統合マルチモーダル理解・生成モデルの進展により、顕著な進歩が示されている。これらの手法は、画像生成タスクにおける指示追従能力を向上させる一方で、モデルの冗長性を低減することが証明されている。多くの手法は、マルチモーダル理解と生成タスクの両方に同じ視覚エンコーダを使用するが、これらのタスクに必要な表現は異なるため、しばしばマルチモーダル理解の性能が最適でなくなる。この問題に対処するために、Janusは視覚エンコーディングの分離を提案し、マルチモーダル理解と生成タスク間の競合を解消し、両タスクで優れた性能を達成している。
Janus は1Bパラメータ規模で検証されているが、限られた学習データと小規模なモデル容量のため、短いプロンプトでの画像生成の性能が最適でないことや、テキストから画像生成の品質が不安定であるといった課題がある。本論文では、Janus の強化版である Janus-Pro を提案し、学習戦略、データ、モデルサイズの3つの側面で改良を加えた。Janus-Proシリーズには 1B および 7B の2つのモデルサイズが含まれており、視覚エンコーディング・デコーディング手法のスケーラビリティを示している。
提案手法
アーキテクチャ
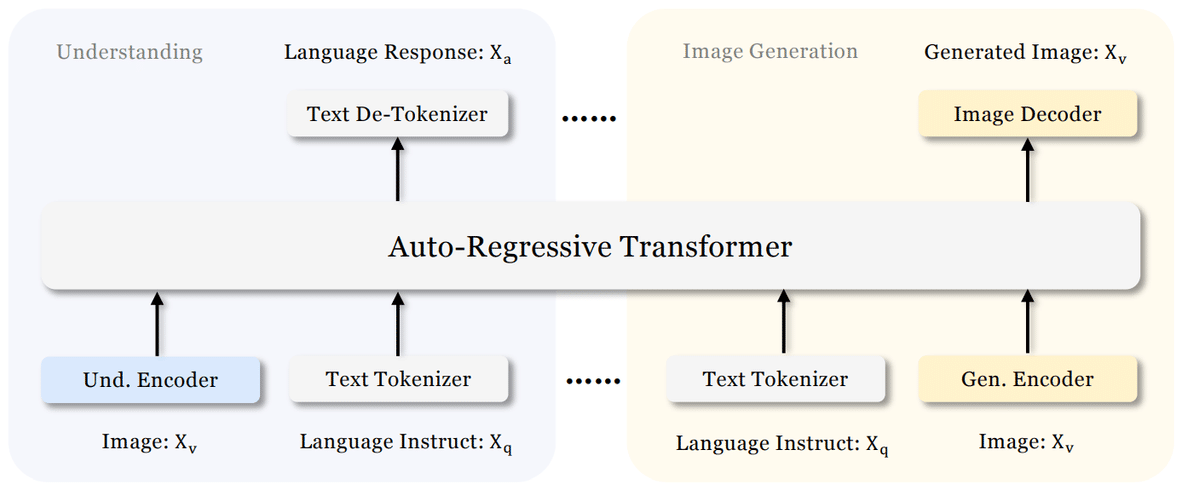
アーキテクチャはJanusと同じ構造を用いた。一方、マルチモーダル理解と生成のための視覚エンコーディングを分離した。マルチモーダル理解のためにはSigLIPエンコードを用い、2次元特徴量を1次元シーケンスに変換しモデルに入力した。画像生成タスクではVQトークナイザ(LlamaGenで採用されているもの)を用いた。
これらの特徴シーケンスを結合してマルチモーダル特徴シーケンスを形成し、LLM に入力する。LLM に組み込まれた予測ヘッドに加えて、画像生成タスクの画像予測用にランダムに初期化された予測ヘッドも使用する。モデル全体は自己回帰型で構成される。
学習戦略の最適化

以前のJanusは3段階の学習プロセスを用いていた
Stage I. アダプタと画像ヘッドの学習
Stage II. 統合事前学習を行い、エンコーダを除くすべてのモデルの学習
Stage III. 教師ありファインチューニングを行い、understanding encoderを含め学習する
しかし、この学習戦略のStage II では、PixArtに倣い、テキストから画像生成の学習を 2 つの部分に分割していた。最初の部分では ImageNetのデータを使用し、カテゴリ名をプロンプトとして画像を生成することでピクセル依存関係のモデリングを行う。次に、通常のテキストから画像データで学習を行う。しかし、実験により、この戦略は最適ではなく、計算効率が大幅に低下することが判明した。
この問題に対処するため、以下の 2 つの修正を加えた。
Stage I の学習時間の延長: Stage I の学習ステップを増やし、ImageNet データセットで十分な学習を行う。実験の結果、LLM のパラメータを固定したままでも、ピクセル依存関係を効果的にモデリングし、カテゴリ名に基づいた適切な画像生成が可能であることが分かった。
Stage II の学習方針の変更: Stage II では ImageNet データを削除し、通常のテキストから画像データのみを使用して、詳細な説明に基づく画像生成を学習する。この改良により、Stage II のデータ活用効率が向上し、学習全体の効率と性能が改善された。
さらに、Stage III の教師ありファインチューニングにおいて、データセットの比率を調整した。具体的には、マルチモーダルデータ、純粋なテキストデータ、テキストから画像データの比率を 7:3:10 から 5:1:4 に変更した。テキストから画像データの割合をやや減らすことで、視覚生成能力を維持しつつ、マルチモーダル理解性能の向上が確認された。
データスケーリング
Janusの学習データを、マルチモーダル理解および画像生成の両面で拡張した
マルチモーダル理解: Stage II の事前学習データとして、DeepSeek-VL2 を参考に約9000万サンプルを追加した。これには、画像キャプションデータセットに加え、表・グラフ・文書理解のためのデータが含まれる。さらに、Stage III の教師ありファインチューニングデータとして、ミーム理解、中国語対話データ、対話体験の向上を目的としたデータセットを追加した。これらの拡張により、モデルの対応範囲が大幅に広がり、多様なタスク処理能力と対話性能の向上が実現された。
画像生成: 以前のJanusで使用された実データは品質が低く、ノイズが多いため、テキストから画像生成の安定性が低く、品質の低い出力が発生する問題があった。Janus-Pro では、約7200万サンプルの合成データを追加し、事前学習段階における実データと合成データの比率を1:1に調整した。これらの合成データのプロンプトはmidjourney-promptsなどの公開データを使用している。実験の結果、合成データを活用することでモデルの収束が速くなり、生成される画像の安定性が向上し、品質も大幅に改善されることが確認された。
モデルスケーリング

以前のJanusでは、1.5BのLLMを用いて視覚エンコーディングの分離が有効であることを検証した。Janus-Proではモデルを 7B にスケールアップした。
大規模な LLM を使用すると、マルチモーダル理解および視覚生成の両方において損失の収束速度が小規模モデルと比較して大幅に向上することが確認された。この結果は、本手法の高いスケーラビリティをさらに裏付けるものである。
実験
定量評価

Janus-Pro は全体的に最も良い性能を達成した。これは、マルチモーダル理解と生成のためのエンコーダを分離し、両タスク間の競合を軽減したことによるものである。
また、大幅にモデルサイズが大きいモデルと比較しても、Janus-Pro は高い競争力を維持している。例えば、Janus-Pro-7B は、GQA を除くすべてのベンチマークにおいて TokenFlow-XL (13B) を上回る性能を示した

Janus Pro 7B は GenEval で 80% の全体的な精度を達成しており、他の統合モデルや生成専用モデルをすべて上回っている。これは、提案手法が優れた指示追従能力を持っていることを示している。

また、Janus Proは DPG-Bench で 84.19 のスコアを達成し、他のすべての手法を上回った。これにより、Janus Pro がテキストから画像生成のための細かい指示の追従に優れていることが確認された。
定性評価

Janus-Pro はさまざまなコンテキストの入力に対して優れた理解能力を発揮し、その強力な性能を示している

Janus-Pro-7B によって生成された画像は非常にリアルであり、解像度は 384×384 に限られるものの、細かいディテールを含んでいる。創造的・想像的なシーンにおいても、Janus-Pro-7B はプロンプトのセマンティック情報を正確に捉え、一貫性のある論理的な画像を生成することができる。
まとめ
Janusの学習戦略、データ、モデルサイズを改善改善により、マルチモーダル理解とテキストから画像生成の能力が大幅に向上した
マルチモーダル理解に関して、入力解像度は384 × 384に制限されており、OCRのような細かいタスクにおいてパフォーマンスに影響がある
画像生成においては、低解像度と再構成誤差が影響し、細部が欠けることがある
画像解像度を上げることで、これらの問題を軽減できる可能性がある