論文解説 AnyControl: Create Your Artwork with VersatileControl on Text-to-Image Generation

project page : https://any-control.github.io/
arxiv : https://arxiv.org/abs/2406.18958
ひとことまとめ
複数の画像条件を1つのControlNetで対応可能にした
概要

ControlNetなどはStableDiffusionに追加で画像条件を加えることができる手法である。これにより、テキストで指示できない細かい調整を行うことができる。これを拡張し、複数の画像で条件付けする手法がいくつか提案された。しかし複数の画像条件付けには以下の問題がある。
1. 入力の組み合わせによらない
2. 複雑な複数の空間条件の組み合わせでも生成できる
3. テキストプロンプトと両立していなければならない
これらの問題を解決する手法として、本研究ではAnyControlを提案する。AnyControlの核となるのはMulti-Control Encoderとよばれるもので、整合性があり、空間的・意味的に整合したマルチモーダルな埋め込みを作成する。これにより、複数の条件を統合することができ、多用途に適用できる高性能な画像条件付生成フレームワークを構築できる。
提案手法
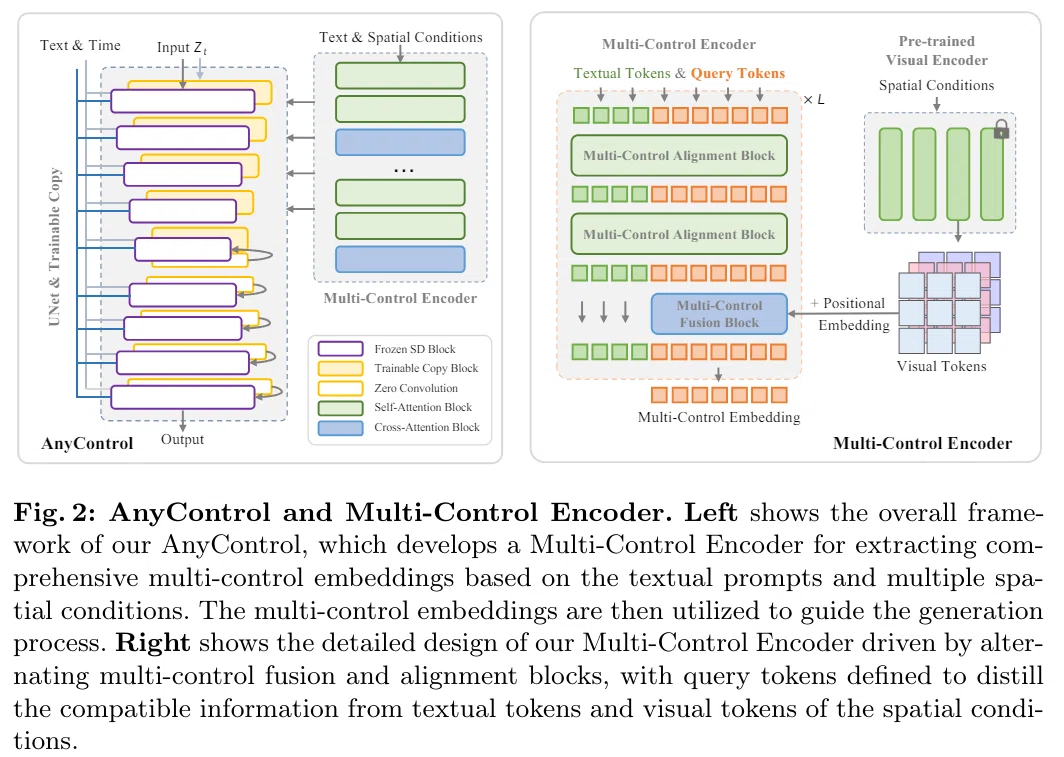
Multi-Control Encoder
ControlNetと同様に、AnyControlは事前学習済みStableDiffusionの重みを固定し、Multi-Control Encoderで複雑な条件を理解する。Text tokenはCLIPのテキストエンコードされた特徴量を使用し、Visual tokenは画像条件すべてをCLIPの画像エンコーダで特徴量に変換したものを使用する。Query tokenは学習可能パラメータとして定義しておく。これにより、入力の柔軟性が高く、テキスト・画像両方の条件を考慮した条件付けを可能にする。
Multi-Control Fusion
MotionControl内で画像情報を埋め込むモジュールで、CrossAttentionを利用し、query tokenに全画像条件のvisual tokenに埋め込む。画像条件はvisual tokenに変換されたあと、学習可能な位置エンコーディングを加算し、query tokenをクエリ、visual tokenをキー、バリューとしてCrossAttentionを計算する。
Multi-Control Alignment
Multi-Control Fusionで制御情報をすべてquery tokenに埋め込むことができたが、重複した画像条件のどちらを優先するか推論するのは大局的情報がないため難しい。しかし生成画像を大局的に操作するためにテキストプロンプトが入力される。そこで、query tokenとtext tokenをself attentionで相互作用させることで大局的情報を埋め込む。このとき、通常のテキストプロンプトに加え、textural task promptを結合することで、どういった操作をすべきなのかをモデルに伝える。
Alternating Fusion and Alignment
情報の統合を確実にするために、multi-control fusion と multi-control alignmentを交互に繰り返す。ここで、visual tokenはさまざまな解像度
ものを利用する。特に、セグメンテーションなどのレイアウト制御やエッジなどの構造制御のように、さまざまな制御レベルがあるため、様々な解像度でこれらを行う必要がある。
以上の要素を取り入れることで、AnyControlは画像情報を統一したマルチモーダル表現として利用できる。また、transformerを利用することで、ユーザの様々な入力の組み合わせを自然に扱うことができる。
実験

提案手法は他の手法と比べ、画像条件に沿った物体が正確に描かれており、かつテキストにそった画像生成を行えていることがわかる。特にオクルージョンに強く、2段目のライオンの画像などではそれが顕著である。

また、提案手法はstyleのコントロールや色情報などを条件として採用することができ、画像条件とそれらの条件を混在させることができる。
まとめ
多様な入力や画像条件の関係をうまく処理することができる、マルチコントロール画像生成フレームワーク「AnyControl」を提案
multi-control fusion とmulti-control alignmentを交互に繰り返し、query tokenに統合することで、これらの複雑な関係を処理できるようにした
AnyControlは様々な画像条件の組み合わせで、高品質な画像を生成可能にした
この記事が気に入ったらサポートをしてみませんか?