論文解説 : Parallelized Autoregressive Visual Generation


Project Page : https://epiphqny.github.io/PAR-project/
arxiv : https://arxiv.org/abs/2412.15119
code : https://github.com/Epiphqny/PAR
ひとことまとめ
同時に複数トークンを推論することで自己回帰モデルの推論速度を改善
概要
自己回帰モデルは画像生成で強力なアプローチの1つだが、逐次的な生成を行うために推論速度が遅い問題がある。そこで、本研究では一貫性を維持しながら、複数トークンを推論し効率的に画像を生成する手法を提案する。提案手法はVARなどの手法と異なり、既存の自己回帰モデルに構造を変えずに取り入れることができる。

提案手法
Token Dependencies and Parallel Generation
通常の自己回帰モデルは1トークンずつの生成を行うが、生成効率が悪い問題がある。効率を上げるため、複数トークンを同時に推論できる方法を検討した。しかし、どのトークンが品質を落とさず同時に推論できるか、という問題がある。
Pilot Study
言語モデルにおいては、隣接トークンをグループ化し同時に推論する手法を試みてきた。一方画像生成において、隣接トークンを直接予測すると大幅な品質低下が生じることがわかった。

自己回帰生成では、各トークンは多様性を維持しながらサンプリング戦略(top-kなど)を通じて生成される。これらのトークンが同時に推論されるとき、それらのトークンは独立してサンプリングされる。しかし隣接トークンは強い関係があり、同時分布はそれぞれの分布に分解することができない。
Design Principles
Pilot Studyから、並列推論を行うには弱い関連をもつトークンを同時サンプリングしないといけない。画像においては、距離がはなれるほど関係が薄くなる。これは近距離のトークンでの同時サンプリングではなく遠距離の同時サンプリングを行う動機になる。しかし、遠いトークンがすべて同時サンプリングできるはけではなく、初期のトークンは特に画像全体の構造に影響する。初期トークンを同時にサンプリングすると反復パターンや支離滅裂なパッチを生成する。
この洞察に基づき、
1. 初期トークンを順々に生成することで適切な全体構造を構成し
2. 強い依存をもつ局所領域内の生成を行いつつ
3. 弱い依存をもつそれぞれの局所領域のトークンを同時にサンプリングする
Non-Local Parallel Generation
以上の原則をもとに、自己回帰の特性を維持しながらトークンの並列予測を可能にする手法を提案する

Cross-region Token Grouping
全トークン($${H \times W}$$)を$${\cfrac{H}{M} \times \cfrac{W}{M}}$$のグリッド$${M \times M}$$個のグループに分割し、それぞれグリッド内の同じ位置のトークンを同時に推論する。
Stage1 各領域の初期トークンの逐次生成 (Sequential Generation of Initial Tokens of Each Region)

この図のように各領域の初期トークンを順番に生成する。左上の領域から開始し、条件付き確率分布に基づいて各領域の初期トークンを生成する。
この逐次生成はグループ数$${M \times M}$$の個数が少ないため、生成効率に与える影響は小さく、後続の並列生成にとって重要な全体の情報を与える。
Stage 2: クロス領域トークンの並列生成 (Parallel Generation of Cross-region Tokens)

初期トークンの生成後、残りのトークンを並列で予測する。図のように各領域でラスタースキャンの順番で全領域のトークンを同時に推論する。例えば$${M=2}$$の場合、4つの初期トークンを生成した後、$${M^2=4}$$個のトークンを並列に予測することで、生成ステップ数を576から147に削減する。並列予測を可能にする一方、各予測は以前に生成されたすべてのトークンに条件付けられているため、自己回帰の特定は維持される。主な違いは関連性が弱いトークンを同時に生成する点である。
Model Architecture Details

モデルは通常のクラス条件付き自己回帰モデルを使用した。入力はクラストークンから始まり、生成したトークンが続く。並列推論のため、特殊な順序構造を3つの領域に分割して実現した。
1. 初期トークンを逐次生成
2. $${n-1}$$個の学習可能トークン$${[M1,M2,M3]}$$を入力に付け加える
3. 同じ位置のトークンを同時に推論する
それぞれのグループで予測する際、モデルはすべての推論済みトークンを入力として受け取り、$${n}$$個のトークンを同時に推論する。学習可能なトークンは通常のトークンと同じ次元を持つベクトルである。位置情報のエンコードには2D RoPEを用い、シーケンスの位置に関係なく元の空間位置情報を保持する。これによりアーキテクチャを維持しながら並列予測ができる。
Group-wise Bi-directional Attention with Global Autoregression

提案手法は初期トークンの逐次生成と残りのトークンの並列生成を組み合わせている。従来の自己回帰モデルでは以前に生成したトークンを参照でき、例えば6dの生成時は6a-6cのトークンすべてを参照できる。しかし同時推論ではその時点まで生成したトークンしか参照できない。そこで、各予測グループ内での双方向attentionを用いることでこれを解消する。この方法により、自己回帰の特性を維持しながらKVキャッシュなどの互換性を担保する。
Extension to Video Generation
この並列生成手法は動画生成にも拡張できる。ただし、位置埋め込みを3D埋め込みに変更した。時間次元に沿った並列生成も検討したが、空間並列化よりも効果がなかった。これは時間依存性が動画の一貫性にとって強いため、空間的な同時生成と比べて並列予測に適していないためである。
Experiments
Experimental Setup
1つずつ生成する自己回帰モデルとの比較を公平に行うため、ベースライン(LlamaGen)と同じような設定を使用した。モデルの大きさは343Mから3.1Bのパラメータ数を持つモデルを作成した。(LLamaGenと対応)

Image Generation
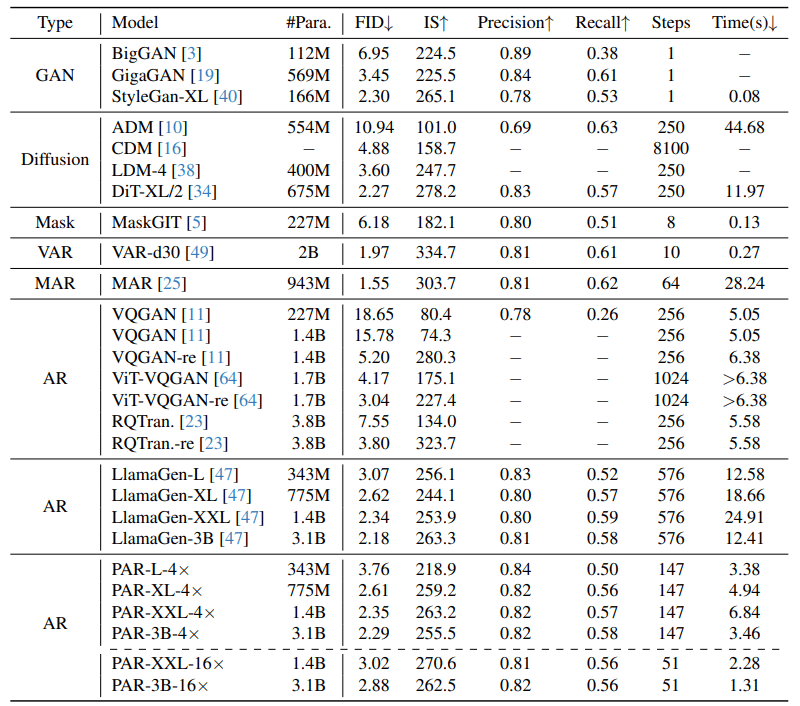
提案手法はLlamaGenの精度を維持しながら、速度を大幅に改善していることがわかる。VARと比較すると少し精度が低いが、提案手法は純粋な自己回帰モデルを維持しており、マルチモーダル生成などにも応用できる。
LLamaGenと比較すると3.9倍生成ステップを高速化し(147 vs 576)、実時間で3.58倍高速化した(3.46s vs 12.41s)が、精度はほぼ変化しない(FID 2.29 vs 2.18)
動画生成においてはMAGVIT-v2がよい性能を示しているがわかる。自己回帰モデルのMAGVIT-v2-ARではFIDが109であるが、提案手法のPAR-1×では若干上回る性能を示した。また、PAR-1×やPAR-16×では、精度をそこまで落とすことなく大幅な高速化を実現した。

まとめ
Parallelized Autoregressive Visual Generation (PAR) を提案し、効率的な並列生成と自己回帰モデルの利点を両立
トークンの依存性に基づく生成を採用し、依存性が弱いトークンを並列生成、依存性が強いトークンでの一貫性の問題を回避
画像・動画の両方で既存の自己回帰画像生成モデルの精度を維持しつつ速度を大幅に改善した