論文解説 IPAdapter-Instruct: Resolving Ambiguity in Image-based Conditioning using Instruct Prompts


arxiv : https://arxiv.org/abs/2408.03209
project page : https://unity-research.github.io/IP-Adapter-Instruct.github.io/
github : https://github.com/unity-research/IP-Adapter-Instruct
ひとことまとめ
画像+指示で参照画像のどこを見てほしいのかをStableDiffusionに教えるモデル
概要
IP-AdapterやControlNetは画像条件を加えることができるが、RGB画像のため意図が不明確である。そこで、この論文では条件画像をどう解釈すべきかという指示ができるIPAdapter-Instructを提案する。
提案手法
まず、通常のIP-Adapterは”画像からすべてを復元する"指示を受けていると考えると、提案手法はこの指示を任意の指示に変更できる拡張と位置づけできる。このとき、以下の5つの生成タスクに分割する。
Replication : 画像のバリエーション (IP-Adapter)
Style : 画像のスタイルを条件とする
Composition : 画像と同じ構造を条件とする
Object : 画像内の物体を条件とする
Face : 画像内の顔を条件とする
適切なデータセットと学習手順があれば、これらのタスクは個々に解決することができる。しかし、これらは学習時間と推論時間が増加する。IPAdapter-Instructはこれらのタスクをすべて同時に学習することで、効率的に学習・推論できる。
モデル構造
提案手法のモデル構造はIPAdapter+のtransformer projection modelをもとにしている。IPAdapter+は図に示すように、それぞれのテキストプロンプトをCross-Attentionでモデル内に取り入れたあとに、IPAdapter専用のCross-Attentionを通じて条件画像の特徴量をモデル内に差し込む。

IPAdapter+はCLIPの情報を線形変換で変換するだけだったが、提案手法は以下のように小さいTransformerモデルを使用する。
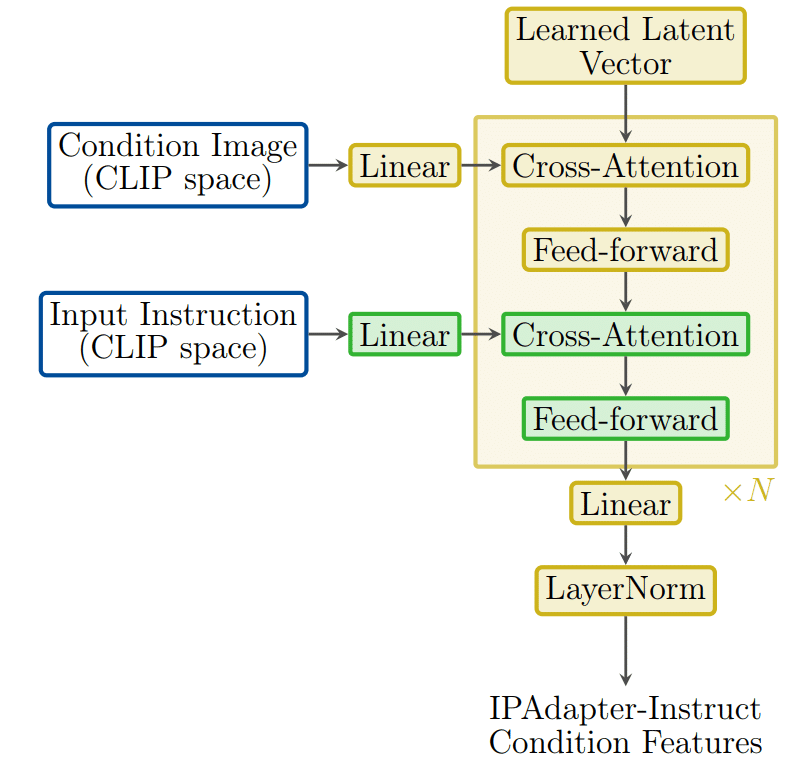
このような構造にすることで、条件画像から指示に従って必要な情報を取得できる。ここで、指示をエンコードするモデルはIPAdapterと同じようにCLIPを用いた。それぞれのタスクが離散的であるため、タスク特化の埋め込みベクトルを利用する。しかし、ViT-H/14という強い事前学習済みモデルを利用することで、CLIP埋め込み空間の意味的な豊かさを利用でき、指示と画像条件の両方の表現を同じ空間で表現できる。これにより、より柔軟でロバストな指示理解ができ、追加のタスクの良い開始点となる。
タスクとデータセット生成
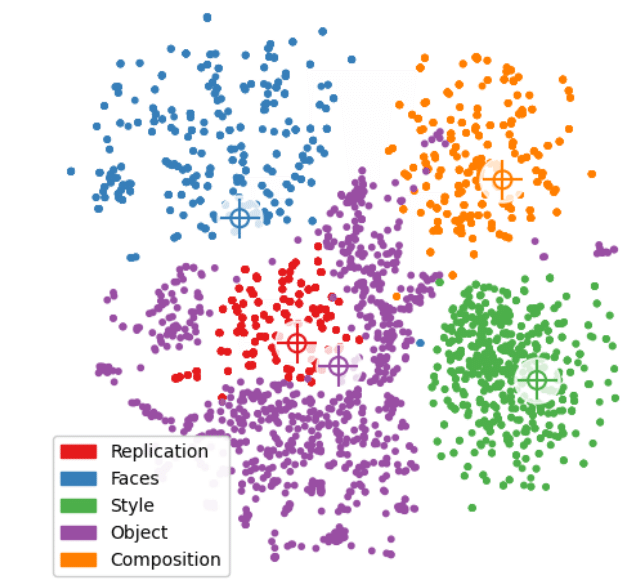
それぞれのタスクに対して、LLMを用いて指示を作成した。これらの指示は学習時にランダムにサンプルされる。それぞれのタスクをCLIP特徴量空間上で識別できるようにするために、タスクごとに特定の単語を入力し、別のタスクでは現れないようにした。t-SNEで可視化した例は以下のようになる。
データ例は以下のようになる

実験
それぞれのタスクを別々に学習した場合との比較

画像から、提案手法は同等か若干よい性能を示していることがわかる。
IPAdapter+との比較


IPAdapter+ではうまく指示通りに画像を生成できないが、提案手法では指示を通じて簡単に操作することができる。しかし、生成結果を見るとcomposition taskが最も苦手であり、生成にスタイルが混じる問題がある。
IPAdapter-Instruct+ControlNet

IPAdapter-InstructはIPAdapterと同様に、ControlNetやLoRAと互換性がある。ControlNetを同時に使用した場合でも、問題なく生成できる。
まとめ
IPAdapterに指示を追加する手法を提案
複数の指示を1つのモデルで学習・推論することができる
IPAdapterと同様にControlNetやLoRAなどの互換性を維持したまま生成ができる