論文解説 : Diffusion as Shader: 3D-aware Video Diffusion for Versatile VideoGeneration Control

project page : https://igl-hkust.github.io/das/
arxiv : https://arxiv.org/abs/2501.03847
code : https://github.com/IGL-HKUST/DiffusionAsShader

ひとことまとめ
Meshからのレンダリングやカメラの動きを指定した動画を生成できるモデル
概要
拡散モデルはテキストや動画からの生成で高い性能を発揮してきたが、カメラ操作やコンテンツ編集などの動画生成プロセスを正確に制御することは課題であった。
提案手法では、動画が動的な3Dコンテンツを2Dレンダリングしたものであるという特性から、3D制御信号を活用することでこれを実現する。従来の二次元条件付けに限定された手法とは異なり、3Dトラッキング動画を制御入力として利用しており、このトラッキング動画を操作するだけで、多様な動画制御を実現する。
提案手法
提案手法のDiffusion as Shader (DaS)はimage to videoモデルの1つで、画像と3Dトラッキング動画を条件付けとして用いる。

Backend video diffusion model
DaSはCogVideoXのI2Vをファインチューニングしたモデルである。画像入力($${\mathbf{I} \in \mathbb{R}^{H \times W \times 3}}$$)から条件付き動画($${\mathbf{V} \in \mathbb{R}^{T \times H \times W \times 3}}$$)を生成する。生成動画は入力画像と同じ幅($${W}$$)と高さ($${H}$$)のサイズを持つ
($${T}$$)フレームで構成される。入力画像($${I}$$)はゼロでパディングされ、ターゲット動画と同じサイズ($${T \times H \times W \times 3}$$)の条件付き動画に変換される。その後、パディングされた条件付き動画に対してVAEエンコーダを適用し、サイズ($${\frac{T}{4} \times \frac{H}{8} \times \frac{W}{8} \times 16}$$)の潜在ベクトルを生成する。この潜在ベクトルに同じサイズのノイズを結合する。次に、DiffusionTransformerを使用して、事前に定義されたステップ数だけノイズの潜在を反復的にデノイズする。デノイズされた潜在ベクトルはVAEデコーダによって処理され、最終的に動画が生成される。以下では、このベースモデルに3Dトラッキング動画を追加条件として適用する方法について議論する。
Finetuning with 3D tracking videos
動画拡散モデルに3Dトラッキング動画を追加条件として導入する(Fig.2 a,b)。3Dトラッキング動画は移動する3D点の集合$${p_i(t)∈R^3}$$からレンダリングされる。ここで、$${t = 1, ..., T}$$は動画内のフレームインデックスを意味する。これらの点の色は、最初のフレームにおける点の座標によって決定される。座標は$${[0, 1]^3}$$に正規化され、RGB色に変換される。この正規化では、z座標の逆数を採用している。これらの色は異なる時刻においても変化しない。
Injecting 3D tracking control
提案手法において3Dトラッキング動画を追加条件として組み込むために、ControlNetと類似した設計を採用した。まず事前学習済みのVAEエンコーダを使用して3Dトラッキング動画をエンコードし、潜在ベクトルを取得する。その後、事前学習済みのDiTをコピーし、これを「条件付きDiT」とし、3Dトラッキング動画の潜在ベクトルを処理する。このDiTは42ブロックを含んでおり、そのうち最初の18ブロックを条件付きDiTとしてコピーする。
条件付きDiTでは、各DiTブロックの出力特徴を抽出し、ゼロ初期化された線形層で処理した後、その特徴をDiTの対応する特徴マップに加算する。このプロセスにより、3Dトラッキング動画の情報を効果的に統合する。条件付きDiTは損失を通じてファインチューニングされるが、事前学習済みのDiTは固定される。
Finetuning details
DaSモデルのトレーニングには、実世界の動画と合成レンダリング動画の両方を含むトレーニングデータセットを構築する。実世界の動画はMiraData から取得し、合成動画はMixamoのメッシュと動作シーケンスを使用してレンダリングする。すべての動画は中心をクロップし、解像度720 × 480で49フレームにリサイズされる。学習時、コピーされた条件付きDiTのみをファインチューニングし、元のDiTは固定する。
レンダリング動画の3Dトラッキング動画を構築する際、合成動画に対しては、GTの3Dメッシュとカメラのポーズにアクセスできるため、これらの密な3D点を直接使用して密な3Dポイントトラッキングを構築する。一方、実世界の動画については、SpatialTrackerを使用して3D点とその軌跡を3D空間内で検出する。具体的には、実際の動画に対して4,900個の3D点を均等に分布させて検出し、それらの軌跡を追跡する。
学習には、学習率0.0001を使用し、AdamWオプティマイザを採用する。GradientAccumulationを用いてバッチサイズ64で学習し、2,000ステップ(8台のH800 GPUを使用して3日間)学習を行った。
Video generation control
Object manipulation

DaSは特定のオブジェクトを操作する動画を生成できる。図に示すように、与えられた画像から、Depth ProまたはMoGEを使用して深度マップを推定し、SAMを用いて物体をセグメンテーションする。その後、物体の点群を操作して、物体操作動画生成のための3Dトラッキング動画を構築する。
Animating meshes to videos
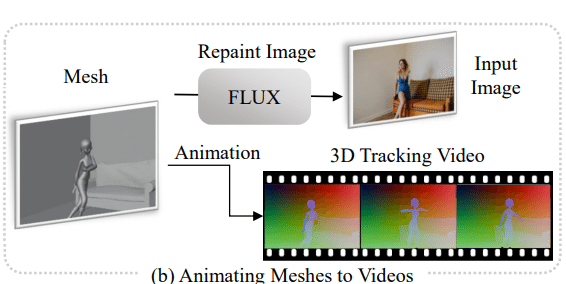
DaSはシンプルなアニメーションメッシュから高品質な動画を作成する。多くのCGソフトウェアツールは、基本的な3Dモデルやモーションテンプレートを提供するが、これらの出力はシンプルで、高品質なアニメーションに必要な詳細な外観やジオメトリを欠いている。これらのシンプルなアニメーションメッシュを出発点として、深度から画像へのFLUXを使用して初期フレームを生成する。その後、アニメーションメッシュから3Dトラッキング動画を作成し、生成された初期フレームと組み合わせることで、DaSはシンプルなメッシュを高品質な動画に変換する。
Camera control
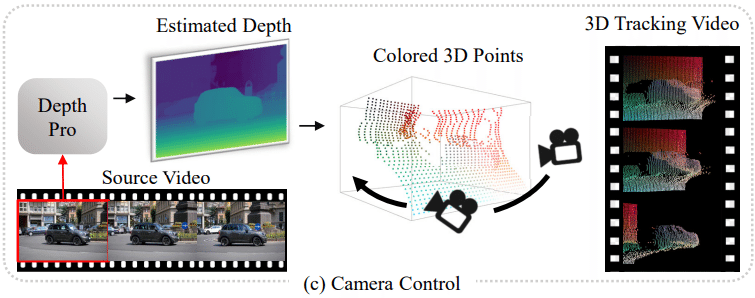
従来の手法は、カメラやレイの埋め込みを条件として動画生成におけるカメラの軌跡を制御するが、これらの埋め込みは真の3D認識を欠いているため、拡散モデルがシーンの3D構造を推測し、カメラの動きをシミュレーションする必要がある。一方で、DaSは3Dトラッキング動画を取り入れることで、3D認識を大幅に向上させ、正確なカメラ制御を可能にする。特定のカメラ軌跡を持つ動画を生成するために、初期フレームの深度マップをDepth Proで推定し、それを色点群に変換する。これらのポイントを指定されたカメラ軌跡に投影し、3Dトラッキング動画を構築することで、DaSは高い3D精度でカメラの動きを制御できる。
Motion transfer
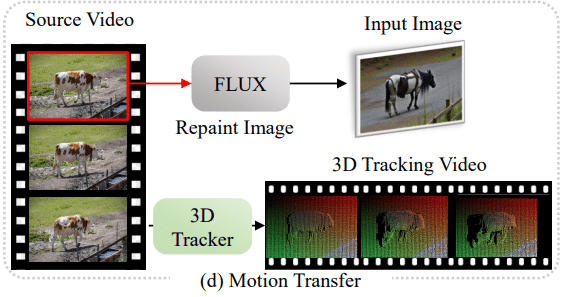
DaSは既存のソース動画からモーションを転送して新しい動画を作成することも可能である。ソース動画の初期フレームの深度マップを推定し、深度から画像へのFLUXモデルを使用して、テキストプロンプトに基づいたターゲット外観にフレームを再描画する。その後、SpatialTrackerを使用して、ソース動画から3Dトラッキング動画を生成し、制御信号として利用する。最後に、編集された初期フレームと3Dトラッキング動画を組み合わせて、DaSモデルがターゲット動画を生成する。
実験
Camera control

RealEstate10Kからランダムに選択した100の軌跡に基づき、ベースライン手法と比較を行った。しかし、ほとんどのランダム軌跡は小さな動きのみを含むため、図に示すように、さらに大きな固定動き(左右、上下、スパイラル)でモデルをテストした。

表に示すように、提案手法はベースライン手法を上回っており、生成された動画のカメラポーズに対する正確な制御を達成することを示している。この理由は、3Dトラッキング動画を活用しているため、モデルが正確に3Dを認識し、動画生成プロセスにおいて正確な空間的推論を可能にしている。
Motion transfer

提案手法はテキスト整合性とフレーム一貫性の両面で優れた性能を示し、2つのベースライン手法を上回っている。

CCEditは低品質なフレームを生成し、一時的な一貫性を維持するのに苦労していることが分かる。一方、TokenFlowは意味的に一貫したフレームを生成するが、一貫した動画を生成するのが困難である。これに対して、提案手法は強い時間的一貫性を保ちながら、動画の動きを正確に転送することが可能である。

Animating meshes to videos

CHAMPと比較し、メッシュから動画へのタスクで評価を行った。CHAMPは人間の画像とモーションシーケンスを入力として受け取り、対応する人物の動画を生成する。モーションシーケンスはアニメーション化されたSMPLメッシュで表現される。CHAMPには同じ入力画像とSMPLメッシュを使用し、対応するアニメーション動画を生成して定性的な比較を行った。また、同じアニメーション化された3Dメッシュから異なるスタイルの動画も生成した。
CHAMPと比較して、我々の手法は、異なるモーションシーケンスおよび異なるスタイル間で、アバターの3D構造とテクスチャのディテールにおいてより高い一貫性を示している。

Object manipulation
物体操作では、SAMと深度推定モデルを採用してオブジェクトのポイントを取得した。その後、平行移動(translation)と回転(rotation)の2種類の操作を評価した。DaSがこれらのオブジェクトに対して、写実的な動画を生成するための正確な物体操作を達成し、強いマルチビュー一貫性を保持していることを示している。

結論
制御可能な動画生成のための手法として、Diffusion as Shader(DaS)を提案
DaSは、カラー付き動的3Dポイントから構築される3Dトラッキングビデオを3D制御信号として活用し、動画生成の過程で拡散モデルを適用してこれらの動きを再現
生成される動画の時間的一貫性が向上し、メッシュからの動画生成、カメラ制御、モーション転送、物体操作など、多様なコンテンツ制御が可能となる