論文解説:One Diffusion to Generate Them All

arxiv : https://arxiv.org/abs/2411.16318
github : https://github.com/lehduong/OneDiffusion
ひとことまとめ
画像生成や画像理解などの多様なタスクを1つのモデルで実現

概要
DALL-EやImagen,StableDiffusionなどのテキストから画像を生成する手法は多く開発されているが、画像条件などを追加する際に特定のタスクごとにモデルをファインチューニングする。
一方、GPT4などのLLMでは汎用モデルとしての能力を有している。これらはタスク固有のモジュールを必要とせず、異なるドメインの多様なタスクを実行でき、訓練されていないタスクであってもゼロショットで推論できる。
そこで、本研究では画像生成と画像理解の両方向を実現する統一された拡散モデルOneDiffusionを提案する。外部の損失や追加モジュールを必要とせず、単一のモデルで複数のタスクを実行可能である。時系列データに対する拡散モデルの手法をもとに、すべての条件とターゲット画像を、訓練時にノイズレベルが変化するviewのシーケンスとして定義する。推論時には、任意のviewを条件付き入力として使用するか、ノイズに設定して出力画像を生成する。また、条件付きテキストを変更してタスクを定義したり、追加の条件を指定できる。
また、学習のためにOne-Genデータセットを作成した。標準的なT2I データに加え、深度推定、セグメンテーション、ポーズ推定などの生成画像を含む。また、ID カスタマイズや複数視点生成用のデータも含まれている。
提案手法
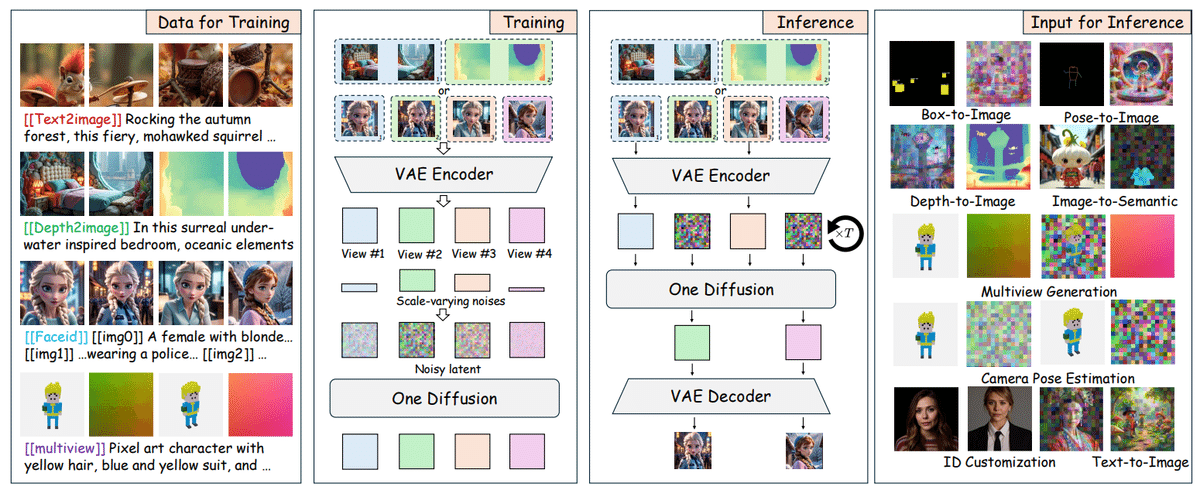
提案手法では マルチモーダルな条件付け生成を、条件画像とターゲット画像のviewシーケンスの生成として定義する。このviewの個数はタスクによって異なり、1つの場合はtext-to-imageタスク、2つの時はdepthやposeなどのimage-to-imageタスク、それ以上の時は複数視点生成もしくはIDカスタマイズである。
学習時、それぞれのviewに対し、タイムステップ$${t_i}$$を$${LogNorm(0,1)}$$からサンプリングし、ノイズを加える。モデルはrectified flowを損失として学習する。
推論時、提案手法は同時サンプリングと条件付きサンプリング両方に対応している。条件付け学習として推論するには、ノイズを生成ターゲット画像として入力し、条件画像はノイズを加えずに推論する。
Implementation Detail

モデル構造はNext-DiTを採用した。full transformerのアーキテクチャを使用することで、異なるview数に対しても適応することができる。また、3D RoPEを採用することで、異なる解像度やアスペクト比に対応できる。
(論文にはタイムステップの扱いに対して説明がないが、おそらくviewごとにscaleを調整している)
タスクごとの詳細設定
Text-to-Image (1 view) 学習時・推論時ともに1つのviewで、通常のtext-to-imageと同じように推論する。タスクラベルは [[text2image]] として設定。
Image-to-Image (2 views)
1枚目のviewをターゲット画像とし、2枚目を条件画像にせていした。推論時は1枚か両方で生成できる。バウンディングボックス検出やセマンティックマップ生成において、16進数の色コードとそのクラスをプロンプトに入力した。 例えば、マウスを黄色に設定した場合、[[semantic2image]] <#FFFF00 yellow mask: mouse> photo of a ...のようになる。
ID Customization (2~4 views)
同じ個人が複数のviewをまたいでいる画像であり、キャプションは[[imgX]]をそれぞれの画像の先頭につけることで表現する。タスクラベルは[[faceid]]で、任意の枚数を条件付けに生成でき、より一貫性のある出力を得ることができる。
Multiview Generation (4-12 views)
Plückerレイ埋め込みをカメラポーズの表現として使用。各画像パッチに対して、光線の原点$${o}$$ と方向$${d}$$を用いてPlücker座標$${r=(o×d,d)}$$ を計算。生成される埋め込みの次元は$${H/8×W/8×6}$$で、潜在空間の空間サイズと一致し、16チャンネルの埋め込みとして複製する。光線埋め込みを画像潜在変数と同様に統一されたシーケンスとして扱い、チャンネル単位で連結するのではなく独立した「view」として処理。この設計により柔軟なノイズ除去が可能となり、カメラポーズに基づくマルチビュー画像生成や、画像条件からのポーズ予測のためにレイ埋め込みをサンプリングすることが可能。光線埋め込みは分散を1にスケーリング。
他のタスクと同様に、タスクラベル [[multiview]] をキャプションに追加。推論時には、画像やPlückerレイ埋め込みを多視点生成やカメラポーズ推定のために、それぞれガウスノイズで置換可能。
One-Gen Datasets
Text-to-Image
公開データセット (PixelProse, Unsplash, Coyo, JourneyDB) と、内部で作成した1000万件の合成データセットを活用。内部データはLLaVA-NeXTやMolmo [11]を使用して再キャプションされた画像を含む。画像のテキスト記述は100~150語で構成される。元のプロンプトがある場合、LLMで生成されたキャプションと元のキャプションの両方を使用。
Image-to-Image
シンプルなタスク(ぼけ除去、inpainting、Canny Edgeからの生成、超解像)には、100万件のサンプルを含む合成データセットを使用し、それぞれの入力条件を作成。複雑なタスクには、MidjourneyやStable Diffusion、Flux-devによる生成物を基にした合成データセットを作成。
Semantic Map and Detection
LLaVA-NeXTで最大10個のエンティティもしくはクラス(人物・シャツ・犬・建物など)を特定し、SAMを用いてセマンティックセグメンテーションを実行、バウンディングボックスを抽出。各クラスにランダムな色を割り当てる。このデータセットは、セマンティックマップ、バウンディングボックス、元画像の350Kトリプレットを含む。Depth Map
DepthAnything-v2を500K画像に適用し、深度データセットを生成。Hypersimデータセットから40K画像をキャプション付けし、トレーニングセットに追加。Human Poses
主に人間のポーズ条件を含む50K画像を収集。YOLOv5で領域を検出し、ViTPoseでポーズ推定を実行。
ID Customization
有名人や映画・ゲームキャラクターの公開画像を収集。4枚以上の画像がある対象のみを残し、NSFWコンテンツを除去。60Kの対象、合計1.3M画像を含むデータセットを構築。画像にはLLaVA-NeXTを用いてキャプションを付与。
Multiview Generation
DL3DV-10K、Objaverse、CO3Dデータセットを使用。ObjaverseではLGMのフィルタリングされた80Kスプリットを利用し、Cap3Dによるキャプションを使用。DL3DVでは各シーンから1枚をサンプルし、LLaVA-Nextでキャプションを作成。CO3Dではキャプションを除外し、テキスト入力にタスクトークンのみを含める。
実験
Text-to-Image


多様なOne-Genデータセットにより、アートおよび写実的なデザインを含むさまざまなスタイルを処理可能。OneDiffusionは小規模データセットでの訓練にもかかわらず、マルチタスク性能で他のベースラインを上回る性能を発揮。この成果はデータセットの多様性と包括的なキャプションに起因。
Controllable Image Generation

HED、Depth、ポーズ、セマンティックマップ、バウンディングボックスなど、さまざまなソースドメインで実験した。OneDiffusionは生成中に条件付き画像に一致し、注意機構とキャプションの補足情報を用いて優れた結果を達成。
Multiview Generation


OneDiffusionは可変入力条件をサポートし、カメラポーズが不明な場合でも適応的な性能を発揮。
ID Customization


OneDiffusionは従来の顔埋め込みに依存する手法と異なり、画像とテキスト条件間の注意機構を活用して表現力豊かな出力を生成可能。この適応性はマルチビュー生成でも有効であり、関連アプリケーションにも対応可能。
Depth Estimation


Marigoldのような事前学習済みモデルに匹敵する性能を達成。絵画や霧の中など多様な条件下での堅牢性が示され、オープンワールドの画像に対しても優れた結果を示す。
Camera Pose Estimation


RayDiffusionはCO3Dのように上半球のビューが多いバイアスのあるデータで訓練されているため、カメラポーズを一貫して上半球に予測する。一方、OneDiffusionは多様な大規模データセットにより、精度が高く、この制限を回避できることを示した。
Conclusion
OneDiffusionはT2I生成、深度推定、セマンティックセグメンテーション、ポーズ推定、マルチビュー生成、IDカスタマイズ、カメラポーズ推定で優れた結果を達成。
拡張性と柔軟性を備え、大規模言語モデルに匹敵する汎用的な拡張性を提供。
幅広いアプリケーションの基盤となる一般目的視覚モデルへの重要な一歩を示した。