
マルチモーダルLLMの投影層について

※投稿者はこの分野の専門家ではなく、特別な知識を持っているわけではありません。したがって、理解や内容に誤りがあるかもしれませんが、ご理解いただければ幸いです。
最近流行りのマルチモーダルLLMは、画像を機械学習を介してテキストに変換するのではなく、直接画像を読み込んで理解する能力を持っています。しかし、入出力がテキストであるLLMがどのように画像を理解するのかは疑問であり、この興味を持ってマルチモーダルLLM (特にLLaVA)の投影層について調査しました。
この投影層は、視覚情報を言語モデルが解釈できる形式に変換するキーとなるコンポーネントであり、それによってLLMは画像の内容を理解し、それに基づいて適切なテキスト応答を生成することが可能になります。
LLaVAのリニア結合と訓練方法:

LLaVAは、画像と言語の情報を統合するためのシンプルなリニア結合を採用しています。具体的には、訓練可能な投影行列を使用して視覚特徴を言語埋め込みトークンに変換し、この行列は画像特徴を言語モデルの単語埋め込み空間にマッピングします。このシンプルな投影スキームは軽量でコスト効果的であり、データ中心の実験を迅速に反復することを可能にしています。
LLaVAモデルの訓練は、2段階の指示調整手順を考慮しています。第1段階では、特徴の整列のための事前トレーニングが行われ、CC3Mから595Kの画像テキストペアがフィルタリングされます。これらのペアは、単一ターンの会話として扱われ、訓練中に視覚エンコーダとLLMの重みは凍結され、投影行列のみが訓練可能なパラメータとして最大化されます。これにより、画像特徴は事前トレーニングされたLLMの単語埋め込みと整列することができます。
第2段階では、エンドツーエンドの微調整が行われ、視覚エンコーダの重みのみが凍結され、投影層とLLMの事前トレーニングされた重みの両方が更新されます。この段階では、マルチモーダルチャットボットおよびScience QAの2つの特定の使用事例が考慮され、これによりLLaVAモデルは、多ターンおよび単一ターンの会話を含む158Kのユニークな言語画像指示のフォローイングデータに微調整されます。
Flamingoのクロスアテンション:

Flamingoモデルは、視覚と言語のモダリティの統合を処理するためにクロスアテンションメカニズムを採用しています。この設定では、ビジョンバックボーンと言語モデル(LLM)デコーダは凍結され、オリジナルおよび凍結されたLLMブロック層の間にゲート付きクロスアテンション密なブロックが挿入され、ゼロからトレーニングされます。
具体的には、トレーニングフェーズでは、事前トレーニングされたビジョンエンコーダと言語モデルが凍結され、次に接続されたPerceiverモジュールとクロスアテンション層がトレーニングされます。このトレーニングは、Multimodal C4という名前の画像テキストデータセットを含むデータセットの混合を利用しています。
BLIP-2のQ-former:
https://github.com/salesforce/LAVIS/tree/main/projects/blip2
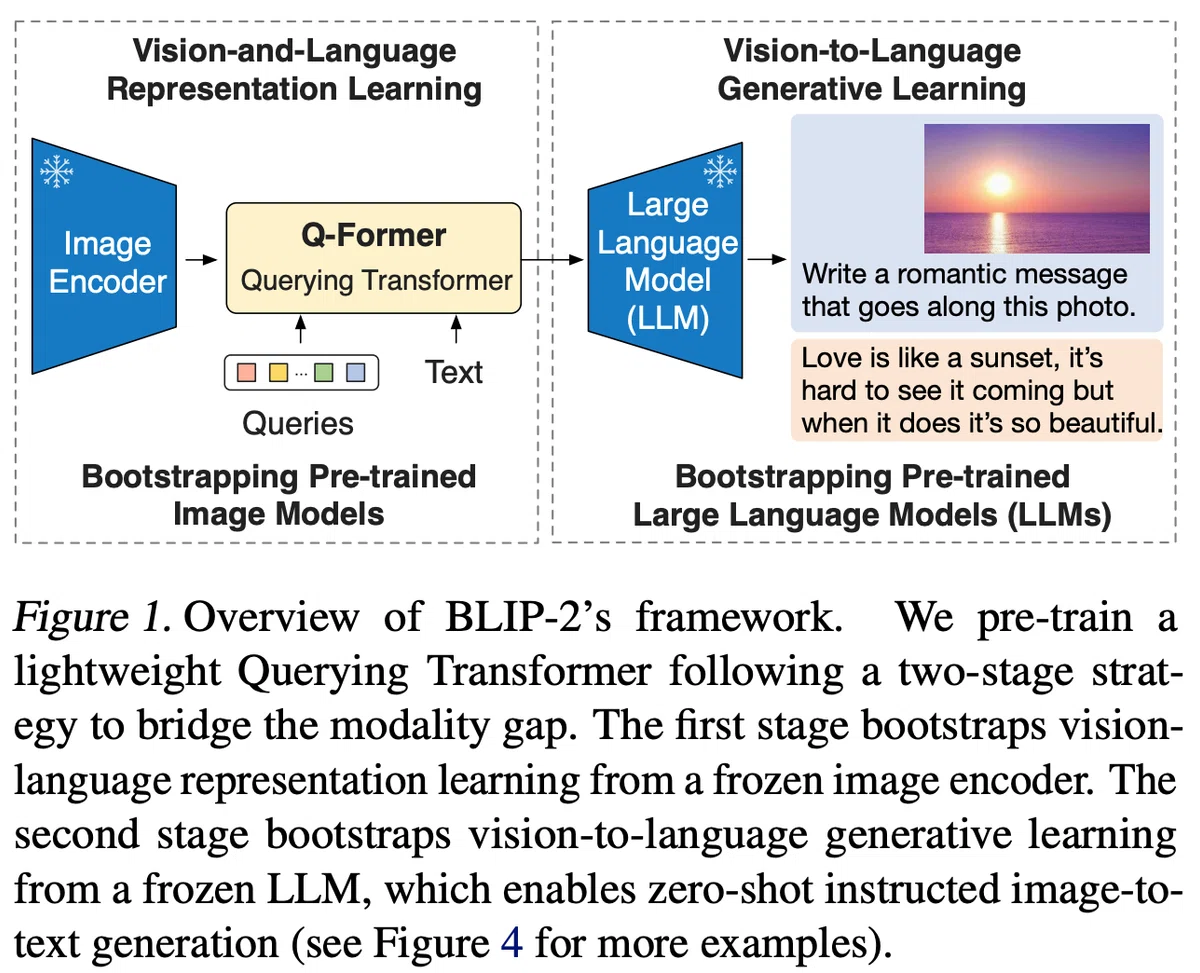
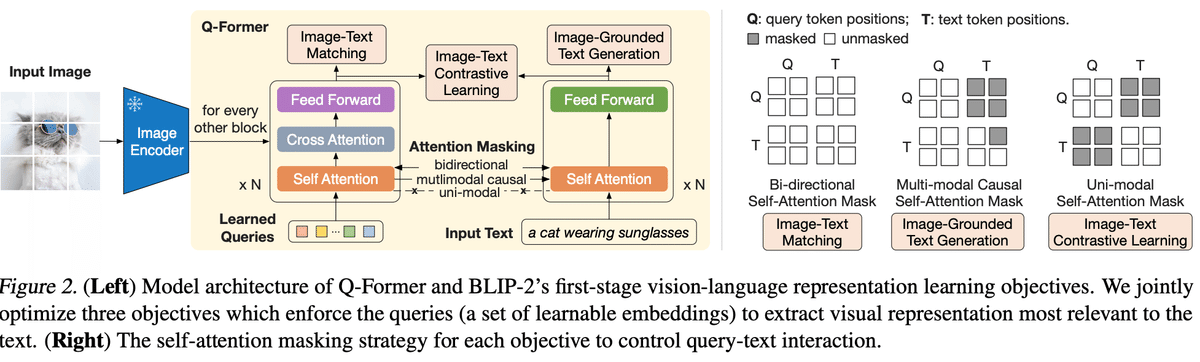
Q-formerはBLIP-2モデルの一部であり、クエリ変換器として機能します。Q-formerは、凍結された画像エンコーダと凍結された大規模言語モデル(LLM)との間にギャップを埋めるために、一連の学習可能なクエリベクトルを採用しています。
Q-formerは、同じセルフアテンション層を共有する2つのサブモジュールで構成されています: 凍結された画像エンコーダと対話し、視覚的特徴抽出のために画像トランスフォーマーを使用し、Q-formerはBLIP-2の唯一の訓練可能な部分であり、画像エンコーダと言語モデルの両方が凍結されたままです。
Q-formerの構成には、他のパラメータの中で、隠れ層の数、アテンションヘッドの数、クロスアテンションの隠れ状態の隠れサイズなどのパラメータが含まれています。
所感
投影層のアーキテクチャ、学習データの生成方法、そして学習の進め方など多くの要因がモデルの精度に影響を与えるでしょう。しかし、私の所感としては、最も重要な要因は投影先のLLMのサイズ(テキストのベクトル空間の大きさ)であるように思われます。ベクトル化された画像等を投影するこのLLMのサイズは、モデルの性能に大きな影響を与える可能性があります。Llama2ベースのモデルでの投影層の精度比較は存在しないか、これに関するさらなる調査を続けることを考えています。