
Python初心者が"東北電力の需要予測"を時系列解析で予測してみた

はじめに
Aidemy Premiumにて「データ分析コース」を6ヶ月受講いたしました。
現在、東北に住んでおりますが冬になると暖房等の使用が多くなり電気料金が春や秋頃にと比べると個人宅で2倍以上、飲食店の経営をしておりますが店舗の電気の使用料は春や秋と比べて3倍以上です。
今回、時系列解析で寒い日と電気量の関係について影響を与えるのかどうかに興味があり、fbprophetでモデル構築を行い東北電力の需要予測と、併せて休日と冬日の周期性と季節性を設定し、精度がどのくらい上がったのかを確認をしてみました。
※参照のYouTube動画を参考にさせていただきながら、今回のブログを作成しております。
参照 https://www.youtube.com/watch?v=uKq_dgEUVfA
python Prophetを用いて東北電力(電力消費量の需要予測)について需要予測 ・時系列解析してみる
時系列解析ライブラリProphetとは
[Prophetの概要]
Prophetは加法モデルに基づいて時系列データを予測するためのライブラリです。Prophetでは、非線形の傾向を年・週・日単位の周期性や変動点にあてはめます。このライブラリは強い周期性を持つ時系列データや、いくつかの周期性を持つ歴史のデータに対して最もうまく予測できます。さらに、時系列データの傾向の間にあるデータの抜けに対して強く、一般的に外れ値をうまく扱います。
[Prophetの特徴]
正確で高速 ProphetはFacebookだけでなく多くのアプリケーションにおいて、計画立案や目標設定のための信頼性のある予測をするために使われています。 完全に自動 手動の努力なしに、乱雑なデータから合理的な予測を得られます。Prophetは外れ値や抜けのあるデータそして時系列データの変化に対して強いです。 予測モデルをチューニング可能 Prophetのモデル構築プロセスではユーザが予測モデルを調整する多くのチャンスがあります。ユーザは自身のドメイン知識を用いることによって、人間が解釈可能なパラメータを予測モデルを改良するために調整することができます。
参照
では、東北電力需要予測についてはじめていきましょう!!
学習用データ 東北電力 2017年〜2019年
テストデータ 2020年
2つに分けたに分けたデータで検証する
環境:MacBook Pro M1 google Colaboratoryを使用
1.データの準備
2017年から2019年にデータを東北電力ネットワーク・東北6県・新潟エリアから学習データとして読み込み
#fbprophetのインストール
!pip3 install pystan
!pip3 install fbprophet
import pandas as pd
from fbprophet import Prophet
#東北電力からデータの読み込み読み込み
#2017,2018,2019の3年からのデータの作成
years = [2017,2018,2019]
#year = years[1]
df = pd.DataFrame()
for year in years:
_df = pd.read_csv(f'https://setsuden.nw.tohoku-epco.co.jp/common/demand/juyo_{year}_tohoku.csv',encoding='shift-jis',skiprows=1)
df = pd.concat([df,_df],axis=0)
df
2.データの前処理
モデルの構築を行うために実測値のデータの前処理を行う
prophetを用いるためにdatetime オブジェクトdsの作成と実測値をyへカラム変更
#インデックスのリセット(インデックスが3年ごと重なっているからリセット)
df = df.reset_index(drop=True)
#fbprophetは2つのカラムが必要になる
#カラム DATA&TIMEを ds 実績を y とする
#DATAととTIMEをdatetimeオブジェクトに格納
date = df['DATE'][0]
time = df['TIME'][0]
#DATE TIME を結合させて文字列にする 年月日
str_datetime = f'{date} {time}'
str_datetime
#str_datetimeを文字列からdatetime オブジェクトに変更
from datetime import datetime as dt
datetimes = []
for index, datum in df.iterrows():#datum in df.iterrows()で行を全て取ってくる
date = datum['DATE']#行の中のDATAのみをとる
time = datum['TIME']#行の中のTIMEのみをとる
str_datetime = f'{date} {time}'
datetime = dt.strptime(str_datetime, '%Y/%m/%d %H:%M')
datetimes.append(datetime)
#dsの作成
df['ds'] = datetimes
#目標値'実績(万kW)'をyに変更
df = df.rename(columns={'実績(万kW)':'y'}
3.予測モデルの構築
Facebookが開発している時系列解析ライブラリprophetを用いてモデル構築を行う
#モデルの宣言
#y 実績(万kW) ds DATE TIME
model = Prophet()
#学習 時系列解析
#2017年から2019年のdfのデータの読み込みをして時系列解析で学習をする
model.fit(df)
#時間軸のみの未来データの入れ物を作る (2020年分の実績値を予測して格納するため)
#うるう年 24時間366日 1時間単位で行ができているからfreq='H'
#2017年から2021年のds(時間のみ表示の)データ
future = model.make_future_dataframe(24*366,freq='H')
#predictメソッドで、futureに予測を行う(2017年1月1日〜2020年12月31)
forecast = model.predict(future)
#グラフ化
import matplotlib.pyplot as plt
model.plot(forecast)
plt.xlim(dt(2018, 1, 1),dt(2018, 1 ,10))
plt.show()予測値と実測値の可視化
forecast(2017年〜2020年の予測値)が青の実線
df(2017年〜2020年の実測値)が黒い点
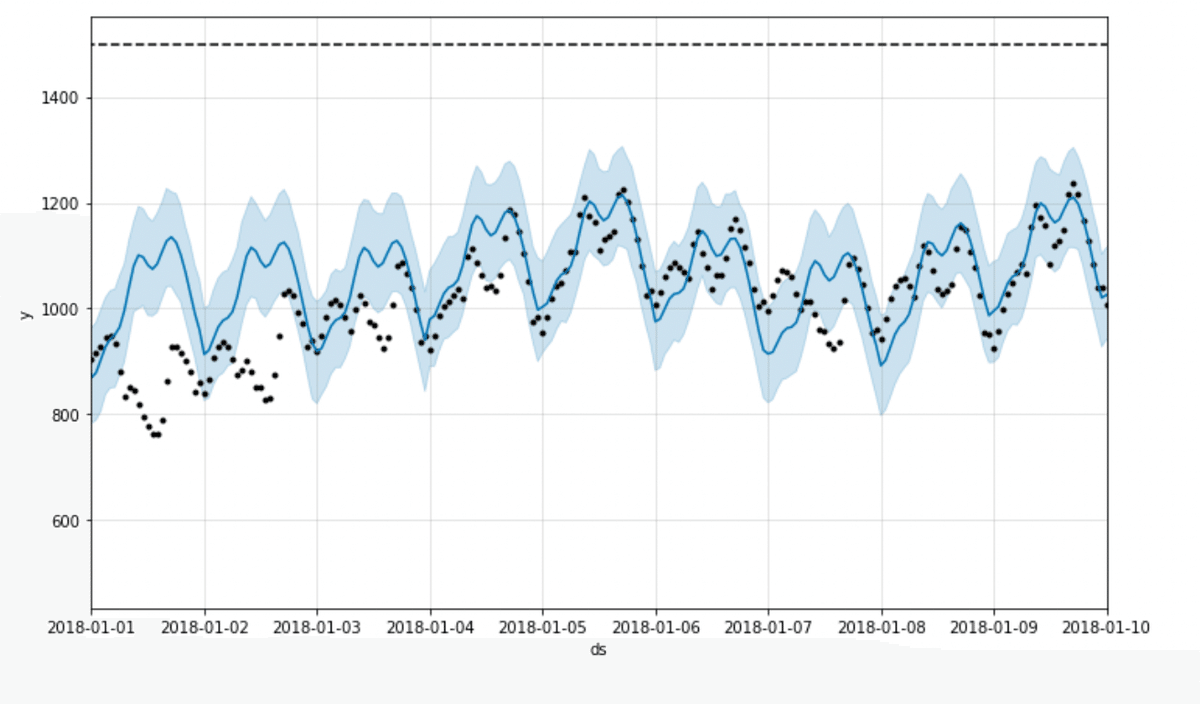
予測値と実測値がずれている箇所があるが、大きくずれている感じはしない。
ただグラフでは分かりづらいため、数値で確認して差分を取る。
4.予測結果の集約
実測値と予測値をまとめる
2020年の予測値と2020年の実測値をどのくらい離れているかを数値で確認する
#2020年csv 実測値 答えのデータ
df_2020 = pd.read_csv('https://setsuden.nw.tohoku-epco.co.jp/common/demand/juyo_2020_tohoku.csv', encoding='shift-jis',skiprows=1)
#2020年csvファイルの実績をyへ変更 (教師データにするため)
df_2020 = df_2020.rename(columns={'実績(万kW)':'y'})
df_2020.head()
#4年間のデータから2020年1月1日から2020年1月31日のデータを取得
#[forecast['ds'] >= dt(2020, 1, 1)]2020年1月1日からのデータのTrueと表記しているデータを取得しインデックスを0から振り直す
forecast_2020 = forecast[forecast['ds'] >= dt(2020, 1, 1)].reset_index(drop=True)
forecast_2020.head()
#空の入れ物を作成
results = pd.DataFrame()
#tのカラムに実測値を入れる
results['t'] = df_2020['y']
#yのカラムに予測値を入れる
results['y'] = forecast_2020['yhat']
#resullts['t'],resullts['y']の差 resullts['diff']
#どのくらい実績値と予測値が離れているかを数値で確認
results['diff'] = results['t'] - results['y']
results.head()
実測値と予測値の差(diff)を数値で出力したが、値が万キロワットと大きい値になっているため、スケール差が大きいのか小さいのが素人では判断できない。
5.評価指数(MAPE)
実測値を予測値をまとめ、今回の評価指数となるMAPEで結果を算出
評価指数(MAPE)
機械学習における平均絶対パーセント誤差(MAPE:Mean Absolute Percentage Error)とは、各データに対して「予測値と正解値との差を、正解値で割った値(=パーセント誤差)」の絶対値を計算し、その総和をデータ数で割った値(=平均値)を出力する関数である。100%の確率値にするため、一般的には最後に100を掛ける(もちろん掛けなくてもよい)。なお誤差は、「予測値-正解値」ではなく「正解値-予測値」でもよい。

今回MAPEを使用する理由としては、予測結果が良かったのかの評価スケールが大きかった時に数値が大きいのか小さいのかが判断がつきにくい。
今回のresulltsの中diffも万キロワットになるため、数値が大きい誤差なのかどうか専門家とかではないと判断がつかないためMAPEを使用。
import numpy as np
#abs 絶対値
#np.mean 平均
np.mean(abs((results['y'] - results['t'])/results['t'])*100)
#約12% 実際の値から離れている %で誤差率を出している
>>>12.375969155618796評価指数(MAPE)予測値と実測値の誤差率(%)
12.38
6.精度向上のための施策
算出後、精度を向上させるために休日や冬日といった情報を追加し、再度モデル構築から評価の流れを実装する
祭日や特別なイベントをモデリングする
参照
休日と冬日フラグを入れたcsvファイルを使用する
(パラメータ設定を行うために、土日祝の休日とcolday 東北7県と新潟の最低気温の平均が0度以下の冬日のデータを作成)
from google.colab import drive
drive.mount('/content/drive')
#holiday_coldday.csvの読み込み
df_holidays = pd.read_csv('/content/drive/MyDrive/holiday_coldday.csv', index_col=0)
df_holidays.head()
#イベント追加 cap カラム 上限 推測値 1500はdf.y.max()の値の暫定の値
df['cap'] = 1500
#イベント制を考慮して、モデルの作成を行う
#パラメータを設定する
model = Prophet(
growth='logistic',
yearly_seasonality=True,#周期性
weekly_seasonality=True,
daily_seasonality=True,
holidays=df_holidays#holidaysに用意したcsvファイルを設定する
)
#モデルの学習
model.fit(df)
#3.予測モデルの構築のデータ
#時間軸のみの未来データの入れ物を作る 2020年分を追加 うるう年 24時間366日 1時間単位で行ができているからfreq='H'
#future = model.make_future_dataframe(24*366,freq='H')
#forecast = model.predict(future)
#イベント追加するために cap (上限 推測値)カラムの作成
future['cap'] = 1500
#予測値を入れる
forecast = model.predict(future)
model.plot(forecast)
plt.xlim(dt(2018, 1 ,1),dt(2018, 1 ,10))
plt.show()
#可視化してもわかりにくい為、MAPEで値が小さくなっているかどうかを確認する
#4年間のデータから2020年1月1日からのデータを取得
#[forecast['ds'] >= dt(2020, 1, 1)]2020年1月1日からのデータのTrueと表記しているデータを取得しインデックスを0から振り直す
forecast_2020 = forecast[forecast['ds'] >= dt(2020, 1, 1)].reset_index(drop=True)
forecast_2020.head()
#tのカラムに実測値を入れる
results['t'] = df_2020['y']
#yのカラムに予測値を入れる
results['y'] = forecast_2020['yhat']
#resullts['t'],resullts['y']の差 resullts['diff']
#どのくらい実績値と予測値が離れているかを数値で確認
results['diff'] = results['t'] - results['y']
results.head()
#abs 絶対値
#np.mean 平均
np.mean(abs((results['y'] - results['t'])/results['t'])*100)
#約12%位から約8% 実際の値から離れている %で誤差率を出している
#休日と冬日をパラメータに設定したことによってよって誤差率が小さくなっている
>>>7.342160112318037評価指数(MAPE)予測値と実測値の誤差率(%)
7.34
(12.38 % → 7.34 %)
休日や冬日といった情報を追加したことで精度が上がったことが確認できた。
7.周期性の確認
[Prophet.plot_componentsメソッド]
予測の構成要素を見たい場合は、Prophet.plot_componentsメソッドが使用できる。デフォルト設定ではトレンドに加え、時系列データの年・週単位の周期性が表示される。
イベント日の効果を考慮したい場合は、holidays=を含める。イベント効果を含めた結果が同様に表示される。
参照
#周期制の確認
model.plot_components(forecast)
plt.show()

グラフ化する事によって、weekly,yearly,dailyに周期性を可視化して確認することができた。yearlyについては、January1とmay1で大きく値が変動しており、冬の時期の電力需要が大きいことが可視化して確認できた。
終わりに
今回、時系列解析ライブラリProphetで精度を向上させるために休日や冬日といった情報を追加し、再度モデル構築からMAPEで評価を行い精度向上したことを確認することができました。
MAPE精度の値について気になりますが、ただ何%の精度が出たらOKというような閾値は存在しないようなので、次回はProphetのパラメーターの設定方法の変更や他の評価方法で精度評価を試してみたり、他の時系列解析のfモデル等との比較等も併せて行ってみたいと思います。
ご観覧ありがとうございました。