J-Moshi(日本語のフルデュプレックス音声対話システム)

J-Moshiは、Moshiをベースとし、人間のように「話す」と「聞く」を同時に行います。 日本語で利用可能な初めてのモデルです。
ってか、やばいっすね。スペースとかだと人間なのかAIなのかもうわかんない。
日本語リアルタイム音声対話モデルJ-Moshiを公開しました!@kyutai_labs のMoshiをベースとし、人間のように「話す🗣️」と「聞く🎧」を同時に行います。
— Atsumoto Ohashi (@atsumoto_ohashi) January 24, 2025
日本語で利用可能な初めてのモデルです。
モデルサイズは7Bと軽量なのでぜひお試しください‼️#NLP2025 で発表予定です。https://t.co/t2EKifkO46 pic.twitter.com/EOBSqQER4F
J-Moshiの概要:
J-Moshiは、日本語のフルデュプレックス音声対話システムであり、人間同士の会話におけるオーバーラップ(発話の重なり)や相槌などを自然に処理できます。この特徴により、実際の対面に近い形式で音声対話が行えるため、リモート会議や日常会話のシミュレーションなど、多彩なシーンでの活用が期待されています。実際の使用例として、10秒間の人間同士の対話音声を入力とし、J-Moshiが生成する20秒の音声サンプルが公開されています。これにより、J-Moshiのリアルタイム応答性能と実用性が示されています。
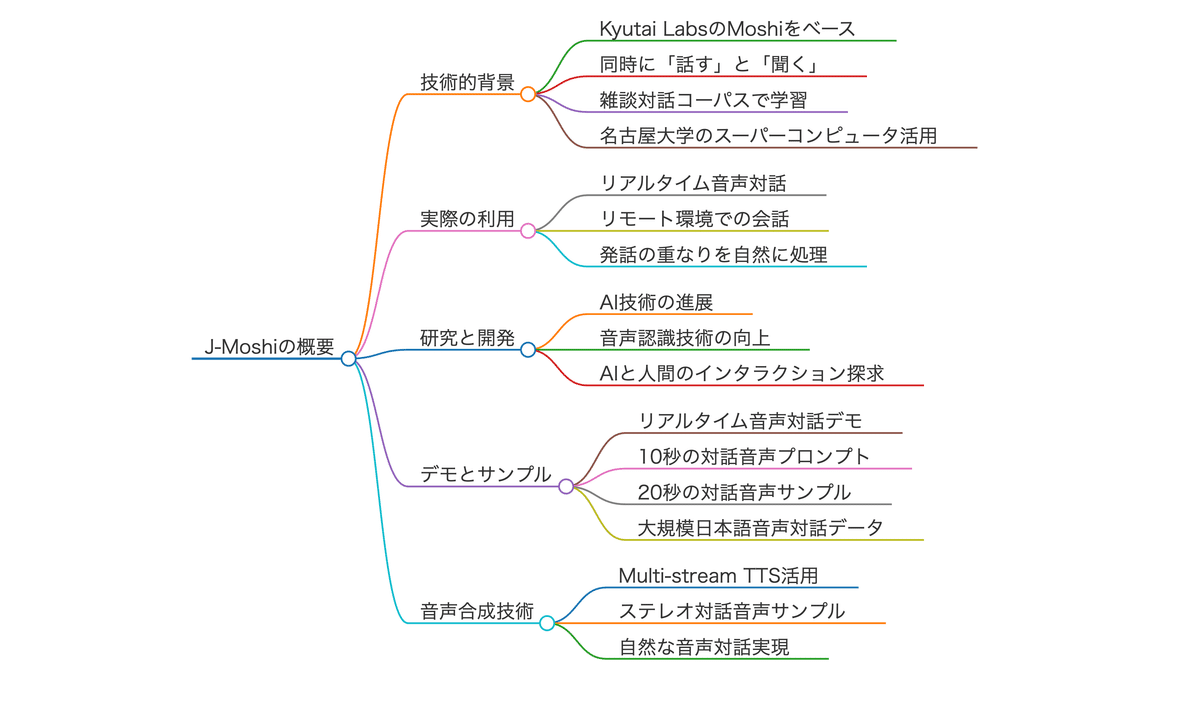
技術的背景:
J-Moshiは、Kyutai Labsが開発するMoshiをベースとしており、話し手と聞き手の処理を同時に進められる点が大きな特徴です。学習のために、雑談から相談まで幅広い日本語対話コーパスを利用し、名古屋大学のスーパーコンピュータを活用して大規模学習が行われています。さらに、Multi-stream TTSという音声合成技術を活用してステレオ音声を生成し、より自然な音声対話を実現しています。
実際の利用:
リアルタイム性が求められる環境での利用が想定され、たとえばオンライン会議やチャットボットなどの場面で有用性が高いとされています。特に、発話の重なりや相槌のタイミングをスムーズに処理できるため、リモートでも対面に近い自然なコミュニケーションが可能になります。オフィス内のやりとりや遠隔医療相談など、人間同士の対話がそのままAIに置き換わるようなケースでも効率的なサポートが期待できます。
研究と開発:
AI技術の進歩に伴い、J-Moshiの機能はさらに拡張される見込みです。音声認識技術や自然言語処理の精度が向上すると、より長い応答や複雑な文脈を扱うことも可能になり、多様な対話シナリオに対応できるようになります。研究者たちは、J-Moshiを通じてAIと人間のインタラクションを深化させ、新たなコミュニケーションのかたちを探求しています。