
日本地図で地名の分布を見てみた

メディア研究開発センターの新妻です。
※本記事はQiitaの朝日新聞社アドベントカレンダー(6日目)にも参加しています。
字名(あざな)はその土地の地形や地質を表している?
地名はその土地の特徴が由来している、なんて話を聞いたことがないでしょうか。例えば、台地に位置しているような場所には、東京都文京区の「目白台」や奈良県生駒市の「白庭台」といった◯◯台といった地名がついていたりします。そんな話を聞くと、なんとなーく日本地図で地名の分布を見たくなりませんか?自分は見たくなってしまったんで、サクッと作ってあれこれ見てみました。
その結果、こんな感じのマップができました。
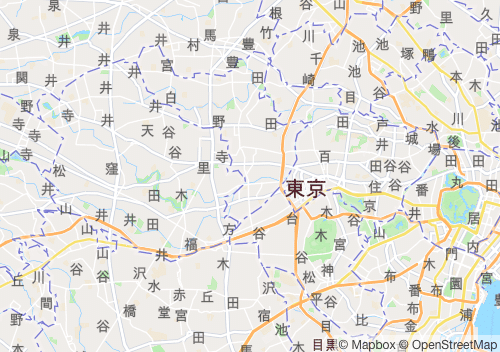
マップ作成に利用したデータは、Geolonia 住所データです。
本データは、Geoloniaによって国土交通省位置参照情報サービスをベースに作成されたCC BY 4.0で提供されている住所データセットです。
今回は、地名のうち「字名」を使っています。
(上記のデータでいう「大字町丁名」カラムです。)
字名を使ったのは、冒頭に挙げた「目白台」「白庭台」や隅田川やその支流のそばに位置する江東区の「深川のようにまさにその土地の地質や地形といった特徴が直接的な形で現れやすいと考えたからですね。
そして、字名に使われている文字のうち、日本全国の字名において最も使われている文字を上から300個選び、その文字が字名に含まれていれば字名の代表点にその文字を割り当てる、なんてことをしています。
ただし、地名に含まれていることが多いが土地を表しているとは言えないような「(大)字△△」「□丁目」や”ヶケのノ之がッツ々町東西南北中上下一二三四五六七八九十〇大小”といった文字、「通り」などにつく送り仮名は選ぶ前に取り除きました。
データを作成したコードが気になっている方もいるかと思いますので、下記に掲載します。
import pandas as pd
import geopandas as gpd
from collections import Counter
from itertools import chain
from shapely import Point
df_address = pd.read_csv("{Geolonia 住所データ}")
df_address["normalized 大字"] = df_address["大字町丁目名"].replace(r"[一二三四五六七八九十〇]+(丁目)$", "", regex=True)
df_address = df_address.drop_duplicates(subset=["normalized 大字"])
df_address["normalized 大字"] = df_address["normalized 大字"].str.replace("([希|望])み", "\\\\0", regex=True)
df_address["normalized 大字"] = df_address["normalized 大字"].str.replace("([上|通])り", "\\\\0", regex=True)
df_address["normalized 大字"] = df_address["normalized 大字"].str.replace(r"大?字(\\w+)", "\\\\1", regex=True)
df_address["normalized 大字"] = df_address["normalized 大字"].str.replace("[ヶケのノ之がッツ々町東西南北中上下一二三四五六七八九十〇大小]", "", regex=True)
df_address["大字 as set"] = df_address["normalized 大字"].apply(set)
counter = Counter(chain.from_iterable(df_address["大字 as set"].tolist()))
target_words = set([char for char, count in counter.most_common(n=300)])
most_chars_in_town = df_address["大字 as set"].apply(lambda cs: cs & target_words).tolist()
most_char_in_town = [sorted(list(cs), key=lambda x: counter[x])[-1] if len(cs) != 0 else "" for cs in most_chars_in_town]
gdf_chars = gpd.GeoDataFrame([(c, Point(lng, lat)) for (c, lat, lng) in zip(most_char_in_town, df_address["緯度"].tolist(), df_address["経度"].tolist()) if c != ""], columns=["char", "geometry"])
gdf_chars.to_file(f"{OUTPUT_PATH}/大字マップ.geojson", driver="GeoJSON")このコードで作成したGeoJSONをmapboxで読み込んで、mapbox studioで地図を作成しました。
マップをみて面白いと思った箇所をピックアップ
長崎県には郷が集まっている地域があった
郷が多いなぁと思って調べてみたら、どうも長崎には「◯◯郷」という地名が「◯◯町」のように使われているようでした。
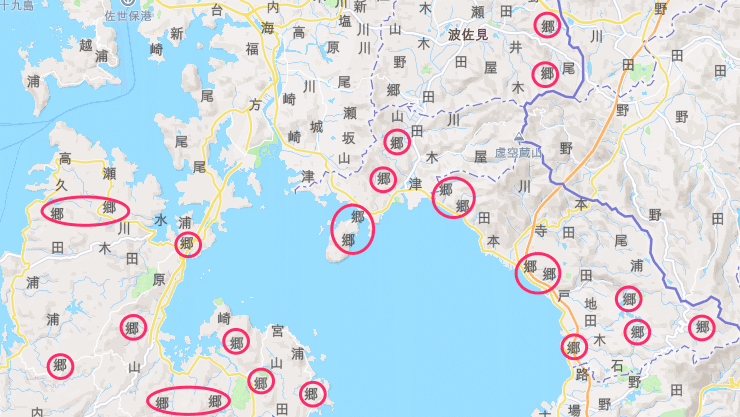

そこで、郷とはなんぞや?と調べてみたところ、Wikipediaに下記のような記述を発見。
郷(ごう、きょう、さと)とは田舎または里を意味し、地方行政の単位(村の集合体)である。
### 律令制の郷
日本では奈良時代、律令制における地方行政の最下位の単位として、郡の下に 里 (り、さと)が設置された。
里は50戸を一つの単位とし、里ごとに里長を置いた。
715年に里を郷(ごう、さと)に改称し、郷の下に新しく設定した2~3の里を置く郷里制に改めた。
しかし里がすぐに廃止されて郷のみとなったため、郷が地方行政最下位の単位として残ることになった。
(中略)
### 長崎県
大村藩領(現在の長崎県彼杵地方)や福江藩領(現在の長崎県五島列島)においては、市町村下の行政区画である字(あざ)の単位として「○○郷」が用いられ、現在も西彼杵郡・東彼杵郡の各町、南松浦郡新上五島町、北松浦郡小値賀町、西海市の大部分で「○○郷」が使われ続けている。
長崎市域、佐世保市宮地区および宇久地区、大村市域、諫早市多良見町伊木力地区、五島市では、前近代的イメージを持つ「郷」を都会的イメージを持つ「町」に置き換えたり、「郷」の文字を削除するなどの所在名称変更を実施している。
なお、公的な文書等で「郷」の区域を「大字」と記載している場合があるが、これは便宜上の区域であり、実際には大字と小字の中間の区域にあたるため、大字ではない事に留意されたい。
どうも「◯◯町」と類似した概念であるとの認識で問題ないっぽい。
けれども、なんだか歴史的な経緯がありそうな雰囲気。
こんな時には郷土資料や歴史書などを引きたいものだけれど、あいにく筆者には教養と時間と情熱が足りずに断念。
沖縄県南部には城の付く地名が多い
沖縄では、城を「グスク」と呼ばれているけれども、意味は普通に「城」です。

そこで、私は「『城』を含んだ字名には、城があったのでは?」と安直に思ったので調べてみました。
そこで、Wikipediaの「三山時代」にて、「中山」と「南山」の城の位置の周辺に「城」が含まれている字名があるっぽいように見える地図が掲載されていることを発見。

北海道は線や条とつく字名が多い
これは、北海道に第N線や◯◯N条という字名が多いからのようです。
また、このような字名を持つ地域は綺麗な区画ができているからか、大字の代表点も綺麗に並んでいるように見えています。
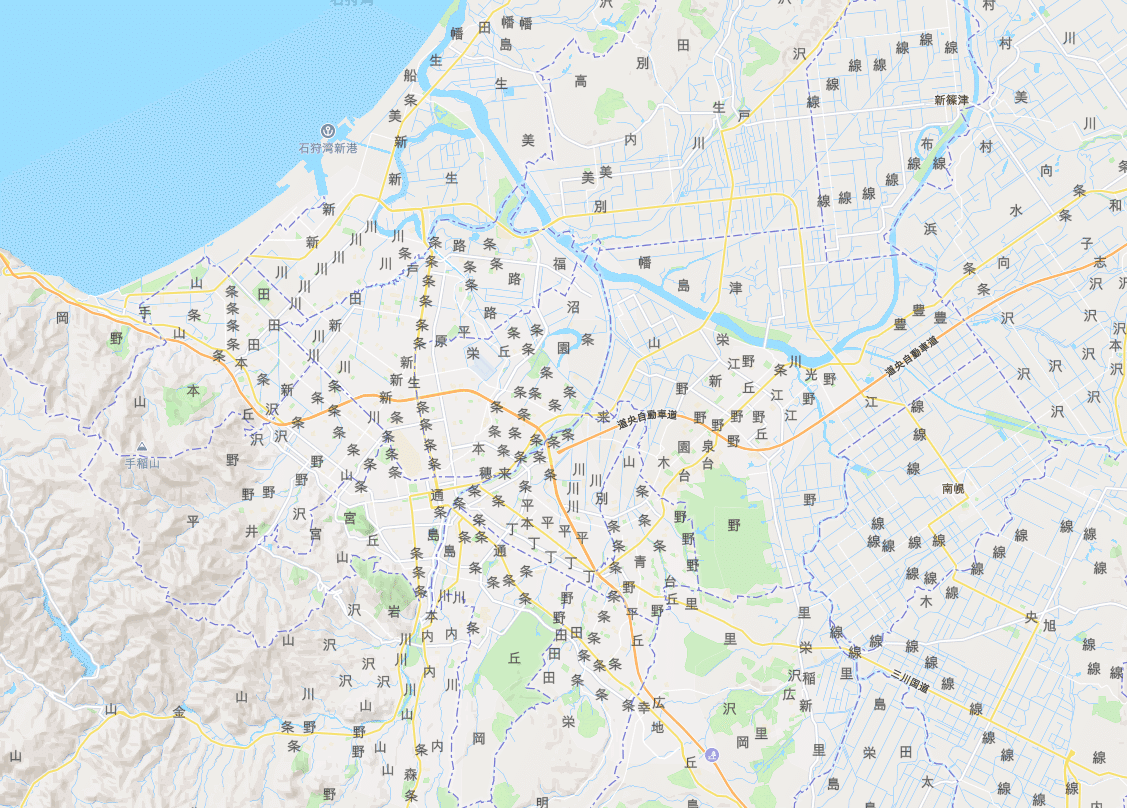
これは北海道が近現代に入ってから開拓によって作られた町が多いからなのかなぁ、と思って調べてみると、北海道庁の資料にこのような記述がありました。
北海道では直線で囲まれた耕地が整然と拡がる風景をよく目にします。これは明治中期から昭和にかけて北海道庁が行った開拓・拓殖の基盤整備事業である殖民地の選定・区画によるものです。
国が選定した殖民地をあらかじめ一定の大きさに区画して地図を作成し、それによって土地の処分をしようとしたものです。現在でも市町村で「○線○号」という町名表示が見られるのはこの名残です。
最初の目的と「面白い」と思った場所が変わっていた…
字名に使われている文字の分布を見ようと思ったのは、「その土地の地質や地形といった特徴が直接的な形で現れやすいと考えたから」でしたが、地図を見て興味を惹かれた箇所は、歴史的経緯によってそのように名付けられていそうな場所ばかりでした。
どれも調べてみると面白そうな経緯なのですが、筆者の力が及ばず…。特に長崎の「郷」については「なんで、そのような名前の付け方になったんだろう?」という疑問を投げっぱなしにしていてすみません…。
地図を眺めていて、地名には地形だけじゃなく歴史も宿っているんだなぁ〜、と改めて思いました。
どれも郷土資料や歴史書などを引ければもっと面白いことが知れそうだなぁと思いつつ、いつかの機会に調べてみたいなと未来の自分に託したいと思います。
(メディア研究開発センター・新妻巧朗)