
【AWS】Auto Scaling Groupで勝手にEC2がterminateされるのを防ぐ

こんにちは、情報技術本部開発部サイト開発チーム(通称Potaufeuチーム)のかいこきと申します。
私たちのチームではPotaufeu(ポトフ)という独自のCMSの開発、またそれを用いた新規サイトの開発等を行っています。私は、チームの中でも、特にインフラに関わることを多く担当しています。
さて、少し前にCloudWatchのalarmをトリガとしてLambdaを起動し、EC2のAuto Scaling Groupの設定を変更する、という仕組みを作りましたので、そのご紹介をします。
なぜこの仕組みが必要だったか?
そもそもこの仕組みを作ったのは、データベースサーバが高負荷になってしまった時に、アプリケーションのレスポンスが遅くなってしまい、APサーバにはなんら異常がないのにALBによって異常と判断され、Auto Scaling GroupにEC2がterminateされてしまうことが何度かあったからです。
高負荷への根本的な対応ができればよいのですが、これには時間がかかるため、それまでは不要な対応を減らしたいですよね。まずは「RDSの高負荷が起因で、EC2がterminateされるのを防ぐ」という暫定の対応をしようと考えました。
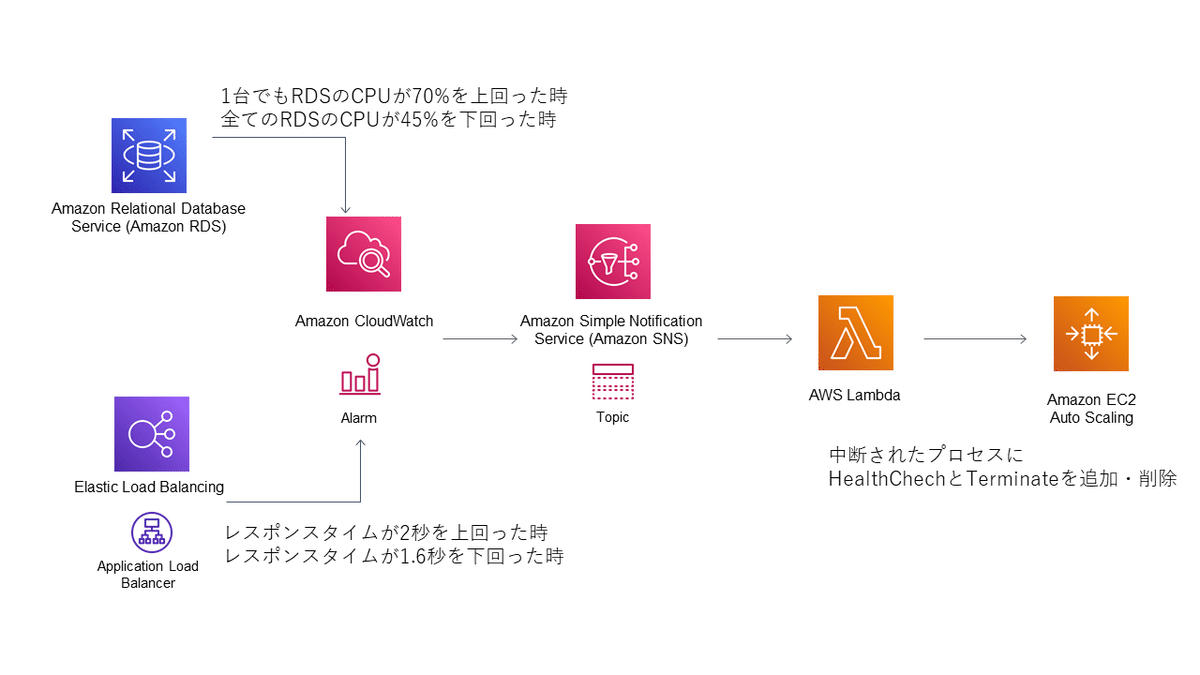
構成図は以下の通りです。
Auto Scaling Group設定までの流れ
(1)RDSを監視するメトリクスアラームを準備
まず、RDSのCPU使用率を監視するメトリクスアラームを用意します。アラーム状態はCPU使用率が75%以上、OK状態は45%以下と設定しました。RDSは複数台あるため、アラーム状態のアクションはどれか1つのRDSサーバでもアラーム状態となった場合にアクションを起動、逆にOK状態のアラームは2020年3月に利用可能となった複合アラームを導入し、全てのRDSがOK状態になった場合にのみアクションを起動するようにしました。
(2)状態変化でLambdaにメッセージ送信
OKからアラームへ、もしくはアラームからOKへ状態が変化した際には、CloudWatchアラームのアクションにより、SNSを経由してLambdaにメッセージを送信します。
(3)Auto Scaling Groupの設定を変更
Lambdaでは、送られてきたメッセージを元に、RDSの種類(master/readreplica)から、どのAuto Scaling Groupを対象とするか、また、アラームの状態により、停止したプロセスにHealthCheckとTermianteを追加するか削除するかを判断し、Auto Scaling Groupの設定を変更します。
try:
for name in autoscaling_group_names:
if name is None:
continue
if new_state == 'OK':
client.resume_processes(
AutoScalingGroupName=name,
ScalingProcesses=[
'HealthCheck', 'Terminate'
]
)
logger.info("プロセスを再開しました: %s" % name)
elif new_state == 'ALARM':
client.suspend_processes(
AutoScalingGroupName=name,
ScalingProcesses=[
'HealthCheck', 'Terminate'
]
)
logger.info("プロセスを停止しました: %s" % name)
else:
# new_state == 'IGNORE'
pass
except Exception as e:
logger.error(e)
これでRDSが異常になった時のみ、HealthCheckを停止し、EC2がterminateされることを防ぐことができるようになりました。これで心置きなく高負荷への対応ができます。
また、同様の仕組みを用いて、ALBのTargetResponseTimeメトリクスからもAuto Scaling Groupの設定を変更できるようにしています。
ちなみにCLoudWatchアラームの通知のテストにはset-alarm-stateコマンドが便利です。
この仕組みを作るときには以下の記事を参考にさせていただきました。