
野球選手写真の自動選別プロセス

はじめに
初めまして。メディア研究開発センター(M研)の福沢と申します。
2022年12月に朝日新聞社に中途入社しました。これまで主に画像処理や画像認識の研究開発に携わってきましたが、現在はマルチモーダル基盤モデル(Foundation Model)の構築手法について研究しています。
今回、社内業務の効率化を図るために、全国高等学校野球選手権大会(全国高校野球選手権大会)の地方大会で弊社の記者が試合現場で撮影した大量の選手写真から、販売可能な写真を自動で選別するプロセスを検証しました。この自動化のプロセスをご紹介させて頂きます。
また、M研では自然言語処理だけでなく、音声認識や画像処理・画像認識、マルチモーダルなど幅広い研究開発を進めています。ぜひ、興味をお持ちいただければ幸いです。
自己紹介
もともと中国出身で、2009年に留学のために日本に渡りました。故郷は上海から北に約300キロほど離れた場所で、江蘇省中部の泰州市という町です。揚子江の隣に位置する泰州市は名物として、たっぷりの蟹みそスープが詰まった大きな「蟹黄湯包」が最も美味しいとされています。また、有名人としては中国の前国家主席である胡錦濤氏も泰州の出身です。
大学院で医療画像処理の研究を行い、画像処理の基礎技術から始まり、3次元データの処理やパターン認識などの技術に関するさまざまな研究成果を発表しました。2016年から深層学習の手法を学びながら、AI画像技術をさまざまな産業応用で実践しました。具体的には、安全運転のためのドライブレコーダーの解析、サーマルカメラを使用した太陽光パネル点検の自動化、OCR技術を活用して紙文書を電子化する取り組み、工場のスマート化と自動化のための画像自動解析技術など、多様な画像技術をさまざまな応用場面で開発・運用しました。
ここからは、AI画像技術の取り組みにより、「野球選手写真の自動選別プロセス」に関してご紹介いたします。
プロセスの概要
背景
全国高等学校野球選手権大会(全国高校野球選手権大会)は、日本の兵庫県西宮市に位置する阪神甲子園球場を主会場に、朝日新聞社と日本高等学校野球連盟(高野連)が毎年8月に開催している高校野球の大会です。その地方大会では朝日新聞社の記者は大会中に取材を行いながら、多数の試合現場写真を撮影しています。1試合ごとに数千枚から数万枚の写真を撮影しています。これまでは何万枚もの写真から手作業で販売可能な写真を選ぶ作業を行っていましたが、このプロセスは時間がかかり、手間のかかるものでした。そこで、AI画像技術を活用して写真の自動選別が可能かどうかの検証を行いました。
データの特徴
1試合当たり平均で2,000〜3,000枚の写真を撮影します。この中から、販売可能な写真を手作業で約200〜300枚(約15%)を選定しています。選定の対象となる写真には、さまざまな種類があります。具体的な例を挙げると、以下のようなものです。
・顔が映っていないもの(約17%)

・ネットが映り込んでいるもの(約1%)

・ピンボケしたもの(約1%)

・構図に問題があるもの(約6%)

・露出が不適切なもの(約0.4%)

・不要な連写(約58%)

自動選別のプロセス
データの特徴を考慮すると、さまざまな問題がある写真を取り除いた後、連写の中からポーズが最も良い写真を選りすぐることによって、販売可能な写真を選択できると考えています。このため、写真の自動選別プロセスは以下の通りです。

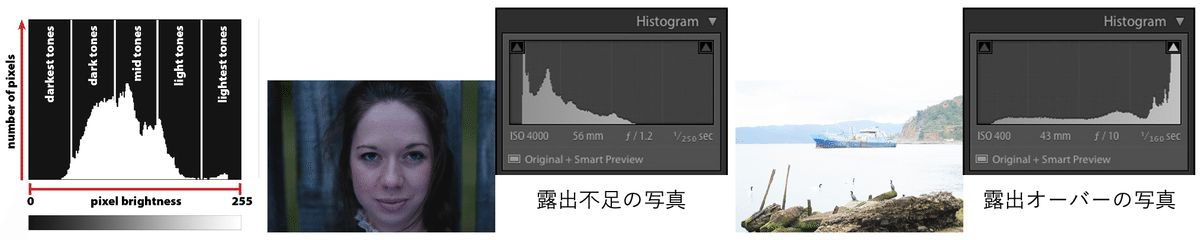
ステップ1 露出フィルター
目的:露出が不適切な写真を検出し、除去する。
手法:画像のヒストグラム分布を利用して、露出不足や露出過剰な写真を判別します。
ステップ2 ピンボケフィルター
目的:ピンボケした写真を検出し、除外する。
手法:ラプラシアン微分を用いたエッジ検出手法を採用し、計算された値に基づいてピンボケを判定する。

ステップ3 イメージグルーピング
目的:できる限り連続撮影の写真を同じグループに分類し、各グループから同じ比率で優れた写真を選定することを目指します。
手法:
1. VGG16 Convolutional Neural Network (CNN)を活用し、画像から特徴量を生成します。
2. 主成分分析(PCA)を使用して、ベクトルの次元を削減します。
3. クラスタリング手法であるG-means[3]を採用し、自動的に適切なクラスタ数を決定しつつ、画像をグループ化します。

以下のプロセスは、各グループごとの写真に対して処理されます。
ステップ4 人物フィルター
目的:人物の不在や不適切なポーズの写真を可能な限り取り除きます。
手法:YOLOv8[4]は、以下の5つの機能を提供しています。
・画像分類
・物体検出
・セグメンテーション
・追跡
・ポーズ推定
この中から、「物体検出」と「ポーズ推定」の2つの機能を活用し、1枚の写真内で人物を検出し、その人物のポーズ(17キーポイント:顔5点、上半身6点、下半身6点)を推定します。
そして、写真内に人物が検出され、かつ良いポーズの場合にのみ、その写真を有用な写真として保持します。さらに、検出された人物の領域内で露出やピンボケなどの問題があるかどうかも確認します。問題がある場合、その人物の領域を取り除きます。

ステップ5 顔フィルター
目的:顔検出技術[5]を用いて、顔の有無や顔の向き情報(ポーズ)[6]から不適切なポーズの顔を特定し、それらを取り除きます。
手法:
1. RetinaFaceという顔検出手法[5]を利用して、顔を検出します。
2. 検出された顔領域に対して、6DRepNetと呼ばれる顔ポーズ推定手法[6]を適用します。
3. 顔ポーズ(主に3次元ベクトルの回転角度「Roll・Pitch・Yaw」で表現される)のパラメータを評価し、不適切なポーズを識別します。通常、正面を向いていないポーズは不適切なポーズとみなされます。
4. 同じ写真内で複数の優れたポーズの人物が存在する場合、以下の情報(ポーズ指標)に基づいて人物領域をランキング付けし、最も優れたパラメータを写真の特徴として選択します。
・ランキング用パラメータ(ポーズ指標):頭ポーズの角度の合計値、人物領域と画像中心との距離、人物領域のサイズ、頭部のキーポイントの数、全身のキーポイントの数。


ステップ6 ポーズ指標によるランキング
目的:各グループごとに、指定された比率で販売可能な写真を選択します。 手法:ステップ5で得られた写真の特徴(人物領域のポーズ指標)に基づいて、各グループ内で写真をランキングします。連写を避けるため、ランキングに入れる写真の撮影時刻と既にランキングされた写真の撮影時刻の間には0.5秒以上の差があるように設定されています。
ステップ7 Top-Nの写真は販売可能な写真として選択
目的:最も優れたポーズの写真を選定します。
手法:一定の枚数の選択(1試合あたり200〜600枚程度の写真を選出したい)を確保するため、指定された比率に基づいて、各グループ内でランキングされた上位N枚の写真を販売可能なものとして選びます。
結果
奈良大会および一部の京都大会で撮影された写真に自動選別プロセスを適用し、以下の2つの表に結果を示しています。
表1 奈良大会
・試合数:34
・総写真枚数:90667
・写真ファイルサイズの合計:約841GB
・自動選別結果(総枚数):12341
・結果対元枚数の比率(全体):14%
基本的に、各試合ごとに選ばれた写真の枚数は200枚以上です。そのため、このプロセスで選ばれた写真は販売サイトにそのまま反映されています。

表2 京都大会
・試合数:14
・総写真枚数:14941
・写真ファイルサイズの合計:約90GB
・自動選別結果(総枚数):1388
・結果対元枚数の比率(全体):10%
京都大会では、ロングショットの同様なアングルからの撮影や連写が多く、現在のプロセスが効果的すぎたため、1試合の処理結果が数十枚に絞られてしまいました。手動で数百枚の写真を追加しました。

まとめ
全国高等学校野球選手権大会の地方大会において、写真の撮影方法は取材現場に委ねられており、撮影された写真の品質や連写の頻度、ファイルのネーミングルールなどが個別に異なる状態です。奈良大会においては、自動選別プロセスの有効性は確認できました。一方京都大会では、同じアングルからの撮影や連写が多かったため、過剰に選別されるケースが発生しました。
全体的な結果を見て、改善の余地や課題が存在すると考えています。次にそれについてまとめます。
残課題
① ピンボケについて
奈良大会および京都大会の写真においても、わずかながらピンボケの写真が結果として残っています。残されたピンボケ写真は、選手の体の一部がピンボケしている場合が多いです。
現在のピンボケ検知手法でこの問題を解決することは難しいと認識しています。しかし、以下の改善案を検討しています。
・セグメンテーション手法を使用して、選手の体の部分を抽出し、その部分に対してピンボケフィルターを適用して判断する方法の試用
② 連写について
現在のプロセスでは、良いポーズと見なされる候補写真から、一定の時間間隔(0.5秒)で連写された写真を一部除外しています。しかしながら、この条件が厳しすぎるため、試合ごとに撮影される総写真枚数が少ない場合、選定される写真の枚数が要求される枚数(1試合あたり200〜600枚程度)に比べて極端に少なくなってしまうケースが発生しています(数十枚など)。
この問題に対して、より柔軟なアプローチを検討して、写真選定プロセスの改善を行う予定です。
③ 写真の主役が一部別の対象に隠された場合について
写真の主役の顔や体などが、場合によっては他の選手によって隠されることがあります。このようなケースが結果に含まれています。この問題を解決するため、主役の領域でHuman Occlusion検出技術やFace Occlusion検出技術を活用することで、改善を見込んでいます。
④ アプリケーション化について
社内の利用者が多くのWindows環境のパソコンを使用しているため、Windows向けのアプリケーションを開発する必要があります。また、写真の特徴に応じていくつかのパラメータの微調整が必要です。そのため、パラメータを調整できる画面を含むアプリケーションを作成することが求められています。
これから、「野球選手写真の自動選別プロセス」の精度向上に取り組みつつ、アプリケーションの開発を進めていく予定です。
参考文献
[1] https://www.creative-photographer.com/exposure-lesson-5-read-camera-histogram/
[2] https://pyimagesearch.com/2015/09/07/blur-detection-with-opencv/
[3] Hamerly, G., & Elkan, C. (2003). Learning the k in k-means. Part of Advances in Neural Information Processing Systems 16 (NIPS 2003).
[4] https://github.com/ultralytics/ultralytics
[5] Deng, J., Guo, J., Zhou, Y., Yu, J., Kotsia, I., & Zafeiriou, S. (2019). Retinaface: Single-stage dense face localisation in the wild. arXiv preprint arXiv:1905.00641.
[6] Hempel, T., Abdelrahman, A. A., & Al-Hamadi, A. (2022, October). 6d rotation representation for unconstrained head pose estimation. In 2022 IEEE International Conference on Image Processing (ICIP) (pp. 2496-2500).
(メディア研究開発センター・福沢栄治)