
【AWS】Lambda@Edgeを使ってわかったメリット+ちょっとデメリット【ロードバランサー卒業】

はじめまして、2年目の土田です。開発部という部署で「朝日新聞デジタル」のWEBサイトを担当しています。ICTRADと私のいる開発部はサービス開発などで一緒に仕事をすることもあります。
私は普段は運用・保守に近い業務ですが、先日、サイト内検索機能の改修にて、「Lambda@Edge」を使って初めて開発を行う機会がありました。(心強い女性先輩社員と二人三脚!)
(↓ 朝日新聞デジタルのサイト内検索ページはこんな感じ)

本日は、「Lambda@Edge」について、実際に使ってみて感じたメリット+ちょっとデメリットを書きたいと思います。
まず、前置きを少し
月間2億PVを超えるアクセスが集まる朝日新聞デジタルでは、ロードバランサーをぶん回して通信の負荷分散を行っています。そこでは、ただWEBサーバーの分散を行うだけではなく、デバイスごとのページの出し分けや機能別のサーバー振り分けなど、スクリプトで細かな制御を仕込んでいます。
例えば、以下のような処理です
・PCやスマホなどデバイスごとに、表示するページを変更
・エンコード処理
・古いURLのリダイレクト処理
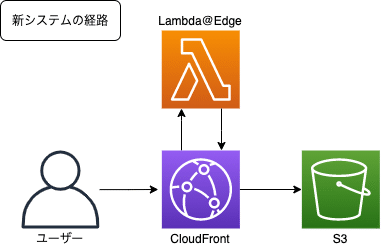
今回、サイト内検索の改修に伴い、サーバー1台でコンテンツ生成まで行っていた既存システムを、APIとフロント(S3サイトホスティング)に分離することになり、CloudFrontを導入しました。
それをきっかけに、既存のロードバランサーのスクリプト処理に代えて、Lambda@Edgeを使用することにしました。
CloudFront化を機に、ロードバランサーをやめてLambda@Edgeに移行した
前置きはさておき、ここでLambda@Edgeの登場です!Lambda@EdgeはCloudFrontに紐付けて利用できるため、これまでのロードバランサーのスクリプトをリライトするだけで実装できるのではないか……?と思い、使ってみました。

スクリプトはこんな感じです。ロードバランサーでの処理をpythonでほぼリライトするだけで実装できました。これは、デバイス判定やページの振り分けなどを設定しています。
from urllib.parse import parse_qs, urlencode, quote
import logging
logger = logging.getLogger()
---省略---
def lambda_handler(event, context):
request = event['Records'][0]['cf']['request']
headers = request['headers']
qs = request['querystring']
parsed_cookies = parse_cookies(headers)
device = 'pc'
# デバイスとcookieによるUA設定
if 'cloudfront-is-mobile-viewer' in headers and headers['cloudfront-is-mobile-viewer'][0]['value'] == 'true':
if 'digital_sp_pcmode' in parsed_cookies and parsed_cookies['digital_sp_pcmode'] == 'ON':
device = 'pc'
else:
device = 'sp'
# 旧パスにきてしまった時のリダイレクト
old_uri = [
---省略---
]
if request['uri'] in old_uri:
response = {
'status': '302',
'statusDescription': 'Found',
'headers': {
'location': [{
'key': 'Location',
'value': '/sitesearch/?' + qs
}]
}
}
return response
# deviceごとのindex.html振り分け
if request['uri'] == '/sitesearch/':
request['headers']['sitesearch-user-agent'] = [{ 'key': 'Sitesearch-User-Agent','value': device }]
request['uri'] = '/' + device + '/index.html'
return requestここからは、Lambda@Edgeを実際に利用してみて感じたことをまとめてみました。
Lambda@edgeのメリット
・CDNで自由にスクリプトが書けるため、ロードバランサーで担っていた処理を一式移行できた
・慣れ親しんだ言語で手軽に実装できた
冒頭にご紹介したように、ロードバランサーではさまざまな処理を行っていました。しかし、インフラを変えると「この処理、どこへ持っていこう…?」と悩みます。
「バックエンドより前で、細々した処理を実行したい」という時に、自由度の高いLambda@Edgeは最適でした。
また、慣れ親しんだ言語(我々はpythonを使いました)で簡単に実現でき、導入コストが低いのも魅力だと思います。
Lambda@Edgeのちょっとデメリット
東京リージョンにないため、
SAMテンプレートで一括管理ができなかった
サイト内検索システムは、基本的に東京リージョン(ap-northeast-1)に構築を進めていました。しかし、Lambda@Edgeだけ東京リージョンにないため、バージニアリージョン(us-east-1)に作成しました。
しかし、ここで問題が発生。
我々、AWS SAMでアプリケーション管理をしていました。しかし、SAMテンプレートには、同じリージョン内の記述しかできません。
そのため、Lambda@EdgeだけがAWS SAMで管理できない…という悲しい状況になりました。
Lambda@Edgeだけ手動管理
結局、GOODな解決方法はなく……
Lambda@Edge周りの編集は手動で行っています。
私のようにすぐ忘れる人間にとって、この管理方法は辛い……(切実)
ひとまず、Lambda@edgeが東京リージョンにできるのを待ち望みたいと思います!
まとめ
以上、Lambda@Edgeのメリット+ちょっとデメリットを体験談を交えて書いてきました。
お伝えしたいのは、ちょっとのデメリットを加味しても、CloudFrontにスクリプトを仕込めるLambda@Edgeはとても便利!ということです。
我々も、ロードバランサーに仕込んでいたスクリプトをまるっとLambda@Edgeに移行することができたので、痒いところに手が届くようなサービスだと感じております〜。
(開発部・土田瞳)