
scikit-lean 分類 - Naive Bays

今回はこの分類の例(ページの下半分)をフォローしながらNaive Baysでテキストを分類する方法を学ぶ。
Data
まずは、データを理解する。自分で何かを解析したい時、どんなデータを作れば良いのか知っておく為に。
データは"The 20 Newsgroups data set"でこのサイトからdownloadできる。*tar.gzを解凍すれば各カテゴリごとにフォルダがあり、各カテゴリの下には1000のemail(で送られたnewsletter)がある。
fetch_20newsgroups()でデータをdownloadしてくれるが、*pkz (python pkl _pickelの圧縮)の開け方を知らないので。(この方法でできる?)
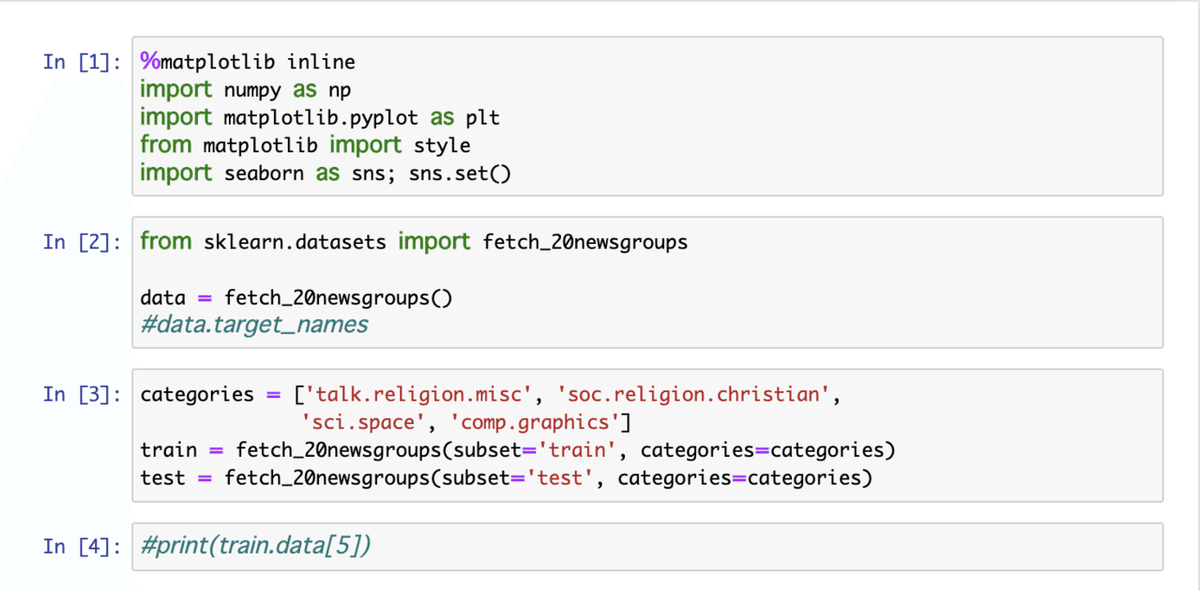
[1] はじめに必要ライブラリを設定
[2] ~/scikit_learn_data/20news-bydate_py3.pkz がdownloadされる。target_nameを確認する。
[3] 解析を簡易化する(理解しやすくする)為に解析するカテゴリを絞る。train用とtest用のデータセットを選んだカテゴリの分だけloadする。
[4] 中身をチェック。outputは参照先にあるのでここでは省略。
TF-IDF
wikipediaのページから以下を引用する。
TF (Term Frequency) : あるドキュメントに出現する用語(term)の重みは、その用語の頻度(frequency)に単純に比例する。
The weight of a term that occurs in a document is simply proportional to the term frequency. - Hans Peter Luhn (1957)
IDF (Inverse Document Frequency):ある用語の特異性は、それが出現するドキュメント(document)の数(frequency)の逆関数(inverse)として定量化できる。
The specificity of a term can be quantified as an inverse function of the number of documents in which it occurs. - Karen Spärck Jones (1972)
[5] TfidVectorizerで大量のニュースレターe-mailのコレクションとして存在する生データをTF-IDFの特徴を持った行列として変換する。
MultinomialNBで用語を数え分類する。
make_pipelineで上記二つのestimator プロセスを統合する。
[6] [7] 途中でプロセスの中身を確認!
[8] pipeline化したモデルでtrain.targetにデータをfitする。ちなみに、dataとtargetはfetch_20newsgroupsのreturn(戻り値)にあるのですぐ呼び出せる。その後、test.dataの分類を予測する。

Confusion Matrix
[9] confusion_matrix (混同行列)でこの分類の質(正しく分類した確率は?)を検証する。行列matの対角、n=mの成分が予測が真のクラスに一致した数となる。
classification_reportで今回の予測はどれくらい正しかったのか、がわかる。例えば、precisionで予測の精度(一致した数/各クラスの真のデータの計)を表す。recallは分母が予測データの計となる。comp.graphics(コンピュータグラフォックス)のクラスを例にとるとprecisionは、344/355=97%, recallは、344/389=88%となる。(Ref)
Heatmap
seaborn.heatmapでカラーマップを作るとどこがhotかすぐわかる(対角成分以外で)。例えば、キリスト教以外の宗教についてのデータなのにキリスト教と認識してしまう間違いが30%(187/635)もある。

Prediction
次に、tutorialに沿って適当に文を入力してモデルで予測させてみる。
[10] でstringを入れれが分類カテゴリを返す関数を定義する。
[11] 正解。"payload" "ISS"という用語がキー??
[12] "islam"なのでsoc.religion.miscのカテゴリのはずだが、この予測は弱いと[9]のclassification_reportでわかった。
[13] "resolution"がキー??
あとで??を調べてみるのも面白い。

All Categories
[14] tutorial だけフォローしても面白くないので、やっぱり全て検証してみる。

[15] "gun"があるので、talk.politics.guns に分類されるのは簡単か。
[16] "gun"を除いても正しい分類。precisionは64%と低いのに?
[17] "solar flare"は宇宙?簡単?
[18] "wmap" "L2"はtest dataの時代にはあった? "orbit"がキーか?
[19] [20] [21] soc.religion.christian分類は弱い。
[22] [23] "cosmic rays" で宇宙、"protons"でエレクトロニクス。

Conclusion
このように機械と自分で対話できるのが面白い。