身近なデータをスプレッドシート×BigQueryで手軽に扱う

BigQueryで扱うデータは、どこかのシステムからBigQueryに連携することが多いと思います。
この記事では、システム構築をするまでもないけれど、もっと身近で更新も自在なデータをスプレッドシートで扱い、BigQueryのデータソースの一つとするケースについて書きます。
※スプレッドシートでデータを扱ううえで「共有」設定も重要です。情報漏洩等のリスクも検討したうえで活用してください。
スプレッドシートでデータを管理するメリット
1ファイルでデータを管理でき、編集も自在
スプレッドシート1ファイルで、複数のシートを使い様々なデータを持たせることができます。また、修正や追加も手軽なため、大変便利です。
シート上部ならコメントを残すことができる
BigQueryでテーブル設定をする際に「スキップするヘッダー行」という設定があります。“シートの上部〇行はデータソースとして扱わない”という設定ができるため、例えばカラムの意味等を持たせることもできます。

1.スプレッドシートでデータソースを作成する
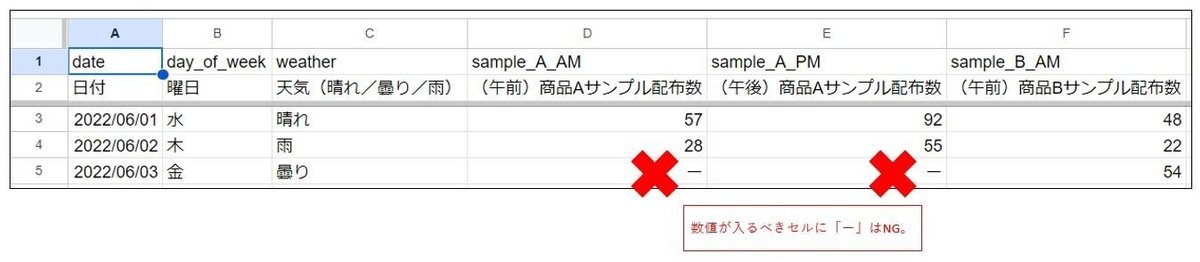
各カラムのデータは、データ型に気を付けよう!
例えば「数値」が入るカラムには「数値」のみを入力するように気を付けましょう。BigQueryのスキーマ定義と合わないデータが入るとクエリできなくなります。
スプレッドシート上では入力が自在な故、数値カラムの特例なデータに対し、コメントを入れてしまったり「ー」や「なし」等、文字列を入れてしまうケースはあるあるです。
2.BigQueryのテーブル設定
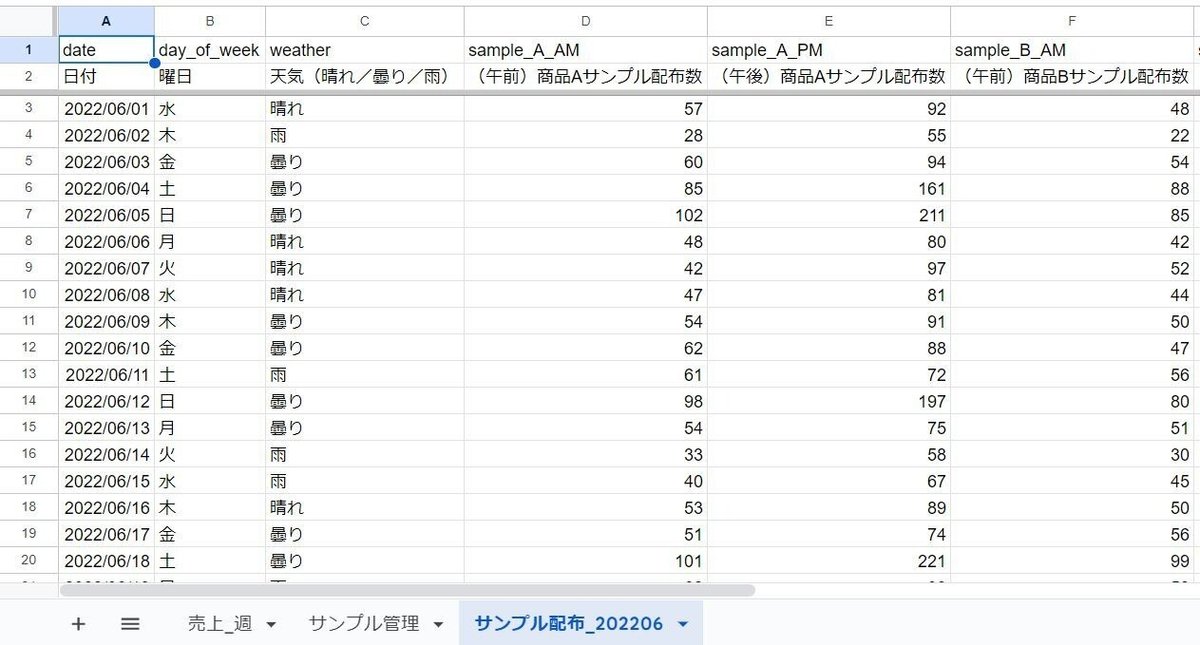
このようなスプレッドシートの「サンプル配布_202206」シートのデータをBigQueryに取り込むケースで、3行目以降からデータソースとして扱う場合の設定です。
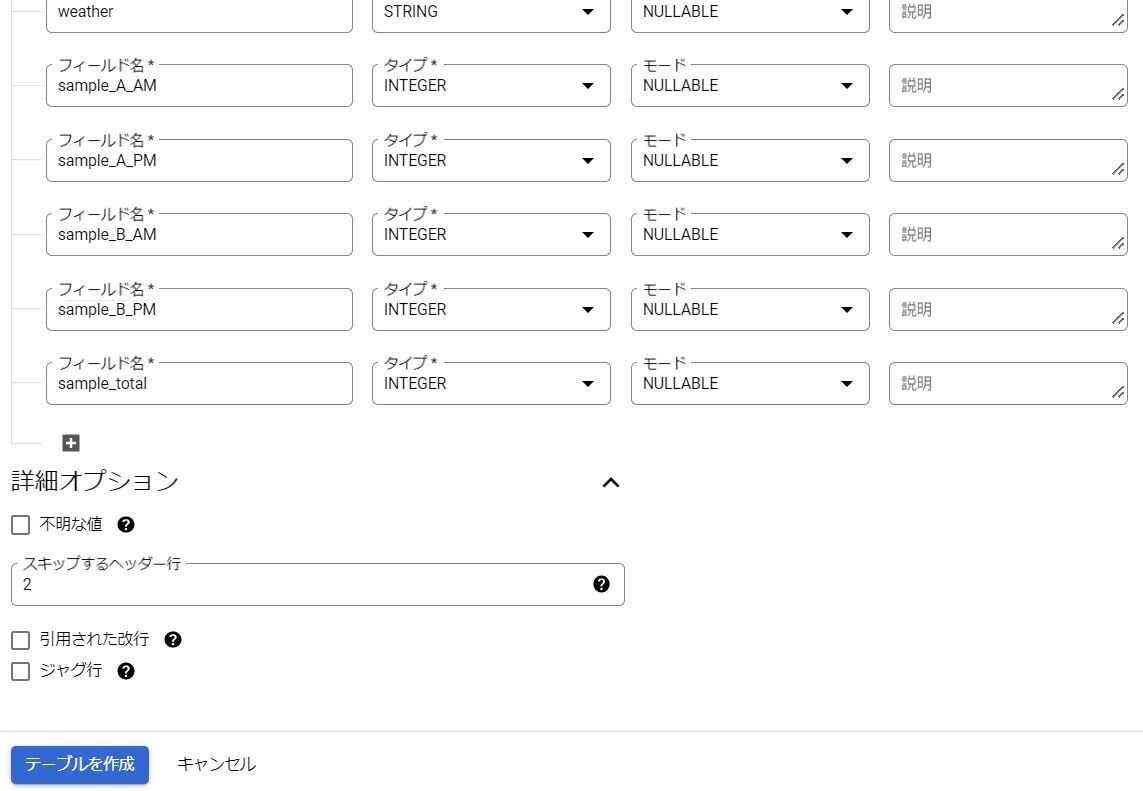
スプレッドシートの設定で固有の設定項目
・スプレッドシートのURL
・取り込むシート名を「シート範囲」に設定する
BigQuery側のテーブル設定
・スキーマ設定 ※「テキストとして編集」でJSONテキストで設定することも可
・スキップするヘッダー行:2

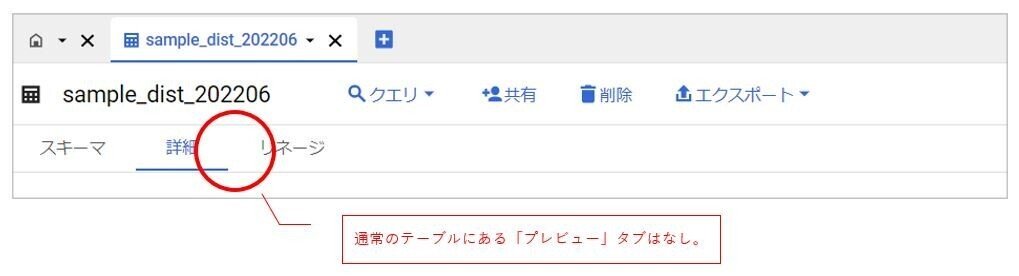
以上で設定完了です。BigQuery上にテーブルが作成され、他のテーブルと同様にクエリが可能になります。
ただし…テーブルといっても、通常のテーブルのように「プレビュー」タブはありません。データの内容を確認したい場合は、以下の操作になります。
・「詳細」タブのソースURLからスプレッドシートに飛ぶ
・クエリで「select * from テーブルID」を実行する
おわり
実は分析に使えそうなデータ、手元にありませんか?
システム構築しなくとも、データソースとして扱えることもあります。
色んなデータを活用してみてください!