
[Python]医療費データで新型コロナウイルス感染症の影響を可視化してみた:PCAの主成分座標平面上にコロナ禍の2020年度のデータを追加プロット

はじめに
こんにちは、機械学習勉強中のあおじるです。
以前の記事で、協会けんぽの過去10年間、47都道府県別の医療費データを使って主成分分析(PCA)をしてみました。このときは、新型コロナウイルス感染症の影響が強く出ていると思われる2020年度(令和2年度)以降のデータをあえて除いて、2010年度(平成22年度)~2019年度(令和元年度)までの10年間のデータを使用しました。
今回は、そのときに除いたコロナ禍の2020年度のデータをPCAの主成分座標平面上に追加でプロットすることで、医療費の構造が変わったかどうかを見てみます。
言語はPython、環境はGoogle Colaboratoryを使用しました。
主成分座標平面上に2020年度をプロット
データ
データは、以前の記事と同じで、全国健康保険協会(協会けんぽ)が公表している「加入者基本情報、医療費基本情報」を用います。今回は、以前除いた2020年度(令和2年度)のデータについて、以前の記事と同じ操作によって、160次元のデータ(性別年齢階級別診療種別ごとの医療費の3要素10項目)に変換します。
年月別
年月別に集計します。
# データの集計
df_ymtsn_P = df_P.iloc[:,[0,1,4,5,6]]
col_names = ['ym', 't', 's', 'n', 'P']
df_ymtsn_P.set_axis(col_names, axis='columns', inplace=True)
df_ymtsn_P = df_ymtsn_P.groupby(['ym', 't', 's', 'n'], as_index=False).sum()
df_ymtsnk_X = df_X.iloc[:,[0,1,3,4,5,7,8,9,10]]
col_names = ['ym', 't', 's', 'n', 'k', 'Ken', 'Nit', 'Ten', 'Ten2']
df_ymtsnk_X.set_axis(col_names, axis='columns', inplace=True)
df_ymtsnk_X = df_ymtsnk_X.groupby(['ym', 't', 's', 'n', 'k'], as_index=False).sum()
print(df_ymtsn_P.shape, df_ymtsnk_X.shape)
# (9024, 5) (27072, 9)
# 1*12*47*28, 1*12*47*2*8*3
# データの変形
df_ymtsn_X_k = df_ymtsnk_X.pivot(index=['ym','t','s','n'],
columns=['k'],
values=['Ken','Nit','Ten','Ten2'])
col_names = []
for x in ['Ken','Nit','Ten','Ten2']:
for k in [1,2,3]:
col_names.append(x+'_'+str(k))
df_ymtsn_X_k = df_ymtsn_X_k.set_axis(col_names, axis='columns')
df_ymtsn_X_k = df_ymtsn_X_k.reset_index()
print(df_ymtsn_X_k.columns)
# Index(['ym', 't', 's', 'n', 'Ken_1', 'Ken_2', 'Ken_3', 'Nit_1', 'Nit_2',
# 'Nit_3', 'Ten_1', 'Ten_2', 'Ten_3', 'Ten2_1', 'Ten2_2', 'Ten2_3'],
# dtype='object')
print(df_ymtsn_X_k.shape)
# (9024, 16)
# 調剤点数の計算
df_ymtsn_X_k['Ten_4'] = df_ymtsn_X_k['Ten2_2'] - df_ymtsn_X_k['Ten_2'] + df_ymtsn_X_k['Ten2_3'] - df_ymtsn_X_k['Ten_3']
col_names = ['ym','t','s','n']
for x in ['Ken','Nit','Ten']:
for k in [1,2,3]:
col_names.append(x+'_'+str(k))
col_names = col_names + ['Ten_4']
df_ymtsn_X_k = df_ymtsn_X_k[col_names]
print(df_ymtsn_X_k.columns)
# Index(['ym', 't', 's', 'n', 'Ken_1', 'Ken_2', 'Ken_3', 'Nit_1', 'Nit_2',
# 'Nit_3', 'Ten_1', 'Ten_2', 'Ten_3', 'Ten_4'],
# dtype='object')
print(df_ymtsn_X_k.shape)
# (9024, 14)
# 医療費の3要素の計算
df_ymtsn_XC_k = pd.merge(df_ymtsn_P, df_ymtsn_X_k,
on=['ym','t','s','n'], how='left')
df_ymtsn_XC_k['KperP_1'] = df_ymtsn_XC_k['Ken_1'] / df_ymtsn_XC_k['P']
df_ymtsn_XC_k['KperP_2'] = df_ymtsn_XC_k['Ken_2'] / df_ymtsn_XC_k['P']
df_ymtsn_XC_k['KperP_3'] = df_ymtsn_XC_k['Ken_3'] / df_ymtsn_XC_k['P']
df_ymtsn_XC_k['NperP_1'] = df_ymtsn_XC_k['Nit_1'] / df_ymtsn_XC_k['P']
df_ymtsn_XC_k['NperP_2'] = df_ymtsn_XC_k['Nit_2'] / df_ymtsn_XC_k['P']
df_ymtsn_XC_k['NperP_3'] = df_ymtsn_XC_k['Nit_3'] / df_ymtsn_XC_k['P']
df_ymtsn_XC_k['TperP_1'] = df_ymtsn_XC_k['Ten_1'] / df_ymtsn_XC_k['P']
df_ymtsn_XC_k['TperP_2'] = df_ymtsn_XC_k['Ten_2'] / df_ymtsn_XC_k['P']
df_ymtsn_XC_k['TperP_3'] = df_ymtsn_XC_k['Ten_3'] / df_ymtsn_XC_k['P']
df_ymtsn_XC_k['TperP_4'] = df_ymtsn_XC_k['Ten_4'] / df_ymtsn_XC_k['P']
df_ymtsn_XC_k['NperK_1'] = df_ymtsn_XC_k['Nit_1'] / df_ymtsn_XC_k['Ken_1']
df_ymtsn_XC_k['NperK_2'] = df_ymtsn_XC_k['Nit_2'] / df_ymtsn_XC_k['Ken_2']
df_ymtsn_XC_k['NperK_3'] = df_ymtsn_XC_k['Nit_3'] / df_ymtsn_XC_k['Ken_3']
df_ymtsn_XC_k['TperK_1'] = df_ymtsn_XC_k['Ten_1'] / df_ymtsn_XC_k['Ken_1']
df_ymtsn_XC_k['TperK_2'] = df_ymtsn_XC_k['Ten_2'] / df_ymtsn_XC_k['Ken_2']
df_ymtsn_XC_k['TperK_3'] = df_ymtsn_XC_k['Ten_3'] / df_ymtsn_XC_k['Ken_3']
df_ymtsn_XC_k['TperK_4'] = df_ymtsn_XC_k['Ten_4'] / df_ymtsn_XC_k['Ken_2']
df_ymtsn_XC_k['TperN_1'] = df_ymtsn_XC_k['Ten_1'] / df_ymtsn_XC_k['Nit_1']
df_ymtsn_XC_k['TperN_2'] = df_ymtsn_XC_k['Ten_2'] / df_ymtsn_XC_k['Nit_2']
df_ymtsn_XC_k['TperN_3'] = df_ymtsn_XC_k['Ten_3'] / df_ymtsn_XC_k['Nit_3']
df_ymtsn_XC_k['TperN_4'] = df_ymtsn_XC_k['Ten_4'] / df_ymtsn_XC_k['Nit_2']
print(df_ymtsn_XC_k.columns)
# Index(['ym', 't', 's', 'n', 'P', 'Ken_1', 'Ken_2', 'Ken_3', 'Nit_1', 'Nit_2',
# 'Nit_3', 'Ten_1', 'Ten_2', 'Ten_3', 'Ten_4', 'KperP_1', 'KperP_2',
# 'KperP_3', 'NperP_1', 'NperP_2', 'NperP_3', 'TperP_1', 'TperP_2',
# 'TperP_3', 'TperP_4', 'NperK_1', 'NperK_2', 'NperK_3', 'TperK_1',
# 'TperK_2', 'TperK_3', 'TperK_4', 'TperN_1', 'TperN_2', 'TperN_3',
# 'TperN_4'],
# dtype='object')
print(df_ymtsn_XC_k.shape)
# (9024, 36)
col_names = ['ym','t','s','n']
var_names = []
for x in ['KperP','NperK','TperN']:
if x != 'TperN':
for k in [1,2,3]:
var_names.append(x+'_'+str(k))
else:
for k in [1,2,3,4]:
var_names.append(x+'_'+str(k))
col_names = col_names + var_names
df_ymtsn_C10 = df_ymtsn_XC_k.copy()
df_ymtsn_C10 = df_ymtsn_C10[col_names]
print(df_ymtsn_C10.columns)
# Index(['ym', 't', 's', 'n', 'KperP_1', 'KperP_2', 'KperP_3', 'NperK_1',
# 'NperK_2', 'NperK_3', 'TperN_1', 'TperN_2', 'TperN_3', 'TperN_4'],
# dtype='object')
print(df_ymtsn_C10.shape)
# (9024, 14)
# データの完成形
df_ymt_C10_sn = df_ymtsn_C10.pivot(index=['ym','t'],
columns=['s','n'],
values=var_names)
col_names = []
for ck in var_names:
for s in [1,2]:
for n in [1,2,3,4,5,6,7,8]:
# print(ck+'_'+str(s)+'_'+str(n))
col_names.append(ck+'_'+str(s)+'_'+str(n))
df_ymt_C10_sn = df_ymt_C10_sn.set_axis(col_names, axis='columns')
df_ymt_C10_sn = df_ymt_C10_sn.reset_index()
print(df_ymt_C10_sn.columns)
# Index(['ym', 't', 'KperP_1_1_1', 'KperP_1_1_2', 'KperP_1_1_3', 'KperP_1_1_4',
# 'KperP_1_1_5', 'KperP_1_1_6', 'KperP_1_1_7', 'KperP_1_1_8',
# ...
# 'TperN_4_1_7', 'TperN_4_1_8', 'TperN_4_2_1', 'TperN_4_2_2',
# 'TperN_4_2_3', 'TperN_4_2_4', 'TperN_4_2_5', 'TperN_4_2_6',
# 'TperN_4_2_7', 'TperN_4_2_8'],
# dtype='object', length=162)
print(df_ymt_C10_sn.shape)
# (564, 162)
# データの保存
df_ymt_C10_sn.to_csv('./df_ymt_C10_sn_2020.csv',index=None)12か月×47都道府県=564行のデータができました。
$$
\def\arraystretch{1.5}
\begin{array}{c:c|c:c:c:c}
\texttt{ym} & \texttt{t} & \texttt{KperP\_1\_1\_1} & \texttt{KperP\_1\_1\_2} & \cdots & \texttt{TperN\_4\_2\_8} \\ \hline
202004 & 1 & {} & {} & {} & {} \\
202004 & 2 & {} & {} & {} & {} \\
\vdots & \vdots & \vdots & \vdots & \ddots & \vdots \\
202004 & 47 & {} & {} & {} & {} \\
202005 & 1 & {} & {} & {} & {} \\
\vdots & \vdots & \vdots & \vdots & \ddots & \vdots \\
202103 & 47 & {} & {} & {} & {}
\end{array}
$$
年度別
また、年度別(2020年度)のデータも作成します。
# 年度追加
df_ymtsn_P['y'] = df_ymtsn_P['ym'] // 100
df_ymtsn_P['y'] = df_ymtsn_P['y'].where(df_ymtsn_P['ym'] % 100 >= 4, df_ymtsn_P['y']-1)
df_ymtsnk_X['y'] = df_ymtsnk_X['ym'] // 100
df_ymtsnk_X['y'] = df_ymtsnk_X['y'].where(df_ymtsnk_X['ym'] % 100 >= 4, df_ymtsnk_X['y']-1)
print(df_ymtsn_P.shape, df_ymtsnk_X.shape)
# (9024, 6) (27072, 10)
# 年度集計
df_ytsn_P = df_ymtsn_P.loc[:,['y','t','s','n','P']]
df_ytsn_P = df_ytsn_P.groupby(['y','t','s','n'], as_index=False).sum()
df_ytsnk_X = df_ymtsnk_X.loc[:,['y','t','s','n','k','Ken','Nit','Ten','Ten2']]
df_ytsnk_X = df_ytsnk_X.groupby(['y','t','s','n','k'], as_index=False).sum()
print(df_ytsn_P.shape, df_ytsnk_X.shape)
# (752, 5) (2256, 9)
# 医療費データのpivot
df_ytsn_X_k = df_ytsnk_X.pivot(index=['y','t','s','n'],
columns=['k'],
values=['Ken','Nit','Ten','Ten2'])
col_names = []
for x in ['Ken','Nit','Ten','Ten2']:
for k in [1,2,3]:
col_names.append(x+'_'+str(k))
df_ytsn_X_k = df_ytsn_X_k.set_axis(col_names, axis='columns')
df_ytsn_X_k = df_ytsn_X_k.reset_index()
print(df_ytsn_X_k.columns)
# Index(['y', 't', 's', 'n', 'Ken_1', 'Ken_2', 'Ken_3', 'Nit_1', 'Nit_2',
# 'Nit_3', 'Ten_1', 'Ten_2', 'Ten_3', 'Ten2_1', 'Ten2_2', 'Ten2_3'],
# dtype='object')
print(df_ytsn_X_k.shape)
# (752, 16)
# 調剤点数計算
df_ytsn_X_k['Ten_4'] = df_ytsn_X_k['Ten2_2'] - df_ytsn_X_k['Ten_2'] + df_ytsn_X_k['Ten2_3'] - df_ytsn_X_k['Ten_3']
col_names = ['y','t','s','n']
for x in ['Ken','Nit','Ten']:
for k in [1,2,3]:
col_names.append(x+'_'+str(k))
col_names = col_names + ['Ten_4']
df_ytsn_X_k = df_ytsn_X_k[col_names]
print(df_ytsn_X_k.columns)
# Index(['y', 't', 's', 'n', 'Ken_1', 'Ken_2', 'Ken_3', 'Nit_1', 'Nit_2',
# 'Nit_3', 'Ten_1', 'Ten_2', 'Ten_3', 'Ten_4'],
# dtype='object')
print(df_ytsn_X_k.shape)
# (752, 14)
# 医療費の3要素の計算
df_ytsn_XC_k = pd.merge(df_ytsn_P, df_ytsn_X_k,
on=['y','t','s','n'], how='left')
df_ytsn_XC_k['KperP_1'] = df_ytsn_XC_k['Ken_1'] /(df_ytsn_XC_k['P']/12)
df_ytsn_XC_k['KperP_2'] = df_ytsn_XC_k['Ken_2'] /(df_ytsn_XC_k['P']/12)
df_ytsn_XC_k['KperP_3'] = df_ytsn_XC_k['Ken_3'] /(df_ytsn_XC_k['P']/12)
df_ytsn_XC_k['NperP_1'] = df_ytsn_XC_k['Nit_1'] /(df_ytsn_XC_k['P']/12)
df_ytsn_XC_k['NperP_2'] = df_ytsn_XC_k['Nit_2'] /(df_ytsn_XC_k['P']/12)
df_ytsn_XC_k['NperP_3'] = df_ytsn_XC_k['Nit_3'] /(df_ytsn_XC_k['P']/12)
df_ytsn_XC_k['TperP_1'] = df_ytsn_XC_k['Ten_1'] /(df_ytsn_XC_k['P']/12)
df_ytsn_XC_k['TperP_2'] = df_ytsn_XC_k['Ten_2'] /(df_ytsn_XC_k['P']/12)
df_ytsn_XC_k['TperP_3'] = df_ytsn_XC_k['Ten_3'] /(df_ytsn_XC_k['P']/12)
df_ytsn_XC_k['TperP_4'] = df_ytsn_XC_k['Ten_4'] /(df_ytsn_XC_k['P']/12)
df_ytsn_XC_k['NperK_1'] = df_ytsn_XC_k['Nit_1'] / df_ytsn_XC_k['Ken_1']
df_ytsn_XC_k['NperK_2'] = df_ytsn_XC_k['Nit_2'] / df_ytsn_XC_k['Ken_2']
df_ytsn_XC_k['NperK_3'] = df_ytsn_XC_k['Nit_3'] / df_ytsn_XC_k['Ken_3']
df_ytsn_XC_k['TperK_1'] = df_ytsn_XC_k['Ten_1'] / df_ytsn_XC_k['Ken_1']
df_ytsn_XC_k['TperK_2'] = df_ytsn_XC_k['Ten_2'] / df_ytsn_XC_k['Ken_2']
df_ytsn_XC_k['TperK_3'] = df_ytsn_XC_k['Ten_3'] / df_ytsn_XC_k['Ken_3']
df_ytsn_XC_k['TperK_4'] = df_ytsn_XC_k['Ten_4'] / df_ytsn_XC_k['Ken_2']
df_ytsn_XC_k['TperN_1'] = df_ytsn_XC_k['Ten_1'] / df_ytsn_XC_k['Nit_1']
df_ytsn_XC_k['TperN_2'] = df_ytsn_XC_k['Ten_2'] / df_ytsn_XC_k['Nit_2']
df_ytsn_XC_k['TperN_3'] = df_ytsn_XC_k['Ten_3'] / df_ytsn_XC_k['Nit_3']
df_ytsn_XC_k['TperN_4'] = df_ytsn_XC_k['Ten_4'] / df_ytsn_XC_k['Nit_2']
print(df_ytsn_XC_k.columns)
# Index(['y', 't', 's', 'n', 'P', 'Ken_1', 'Ken_2', 'Ken_3', 'Nit_1', 'Nit_2',
# 'Nit_3', 'Ten_1', 'Ten_2', 'Ten_3', 'Ten_4', 'KperP_1', 'KperP_2',
# 'KperP_3', 'NperP_1', 'NperP_2', 'NperP_3', 'TperP_1', 'TperP_2',
# 'TperP_3', 'TperP_4', 'NperK_1', 'NperK_2', 'NperK_3', 'TperK_1',
# 'TperK_2', 'TperK_3', 'TperK_4', 'TperN_1', 'TperN_2', 'TperN_3',
# 'TperN_4'],
# dtype='object')
print(df_ytsn_XC_k.shape)
# (752, 36)
col_names = ['y','t','s','n']
var_names = []
for x in ['KperP','NperK','TperN']:
if x != 'TperN':
for k in [1,2,3]:
var_names.append(x+'_'+str(k))
else:
for k in [1,2,3,4]:
var_names.append(x+'_'+str(k))
col_names = col_names + var_names
df_ytsn_C10 = df_ytsn_XC_k.copy()
df_ytsn_C10 = df_ytsn_C10[col_names]
print(df_ytsn_C10.columns)
# Index(['y', 't', 's', 'n', 'KperP_1', 'KperP_2', 'KperP_3', 'NperK_1',
# 'NperK_2', 'NperK_3', 'TperN_1', 'TperN_2', 'TperN_3', 'TperN_4'],
# dtype='object')
print(df_ytsn_C10.shape)
# (752, 14)
# データのpivot
df_yt_C10_sn = df_ytsn_C10.pivot(index=['y','t'],
columns=['s','n'],
values=var_names)
col_names = []
for ck in var_names:
for s in [1,2]:
for n in [1,2,3,4,5,6,7,8]:
col_names.append(ck+'_'+str(s)+'_'+str(n))
df_yt_C10_sn = df_yt_C10_sn.set_axis(col_names, axis='columns')
df_yt_C10_sn = df_yt_C10_sn.reset_index()
print(df_yt_C10_sn.columns)
# Index(['y', 't', 'KperP_1_1_1', 'KperP_1_1_2', 'KperP_1_1_3', 'KperP_1_1_4',
# 'KperP_1_1_5', 'KperP_1_1_6', 'KperP_1_1_7', 'KperP_1_1_8',
# ...
# 'TperN_4_1_7', 'TperN_4_1_8', 'TperN_4_2_1', 'TperN_4_2_2',
# 'TperN_4_2_3', 'TperN_4_2_4', 'TperN_4_2_5', 'TperN_4_2_6',
# 'TperN_4_2_7', 'TperN_4_2_8'],
# dtype='object', length=162)
print(df_yt_C10_sn.shape)
# (47, 162)
# データの保存
df_yt_C10_sn.to_csv('./df_yt_C10_sn_2020.csv',index=None)2020年度の1年度分の47都道府県別のデータができました。
$$
\def\arraystretch{1.5}
\begin{array}{c:c|c:c:c:c}
\texttt{ym} & \texttt{t} & \texttt{KperP\_1\_1\_1} & \texttt{KperP\_1\_1\_2} & \cdots & \texttt{TperN\_4\_2\_8} \\ \hline
2020 & 1 & {} & {} & {} & {} \\
2020 & 2 & {} & {} & {} & {} \\
\vdots & \vdots & \vdots & \vdots & \ddots & \vdots \\
2020 & 47 & {} & {} & {} & {}
\end{array}
$$
主成分座標に変換
以前の記事で作成した2010年~2019年度の10年間のデータと、今回新たに作成した2020年度のデータをそれぞれ読み込み、10年間のデータで行ったPCAと同じ変換を2020年度のデータにも適用します。
年月別、年度計のそれぞれについて行います。
年月別
# 2010-2019年度データ
df_ym = pd.read_csv('./df_ymt_C10_sn.csv')
print(df_ym.shape) # (5640, 162)
# 数値部分
X = df_ym.iloc[:,2:]
print(X.shape) # (5640, 160)
# スケーリング
from sklearn import preprocessing
scaler_ym = preprocessing.MinMaxScaler()
X = scaler_ym.fit_transform(X)
print(X.shape) # (5640, 160)
# PCA
from sklearn.decomposition import PCA
pca_ym = PCA(n_components=160)
PC_ym = pca_ym.fit_transform(X)
print(PC_ym.shape) # (5640, 160)
# 2020年度データ
df_ym_2020 = pd.read_csv('./df_ymt_C10_sn_2020.csv')
print(df_ym_2020.shape) # (564, 162)
# 数値部分
X_2020 = df_ym_2020.iloc[:,2:]
print(X_2020.shape) # (564, 160)
# 上と同じスケーリングの変換を適用
X_2020 = scaler_ym.transform(X_2020)
print(X_2020.shape) # (564, 160)
# 上と同じPCAの変換を適用
PC_ym_2020 = pca_ym.transform(X_2020)
print(PC_ym_2020.shape) # (564, 160)年度別
# 2010-2019年度データ
df_y = pd.read_csv('./df_yt_C10_sn.csv')
print(df_y.shape) # (470, 162)
# 数値部分
X_y = df_y.iloc[:,2:]
print(X_y.shape) # (470, 160)
# スケーリング
from sklearn import preprocessing
scaler_y = preprocessing.MinMaxScaler()
X_y = scaler_y.fit_transform(X_y)
print(X_y.shape) # (470, 160)
# PCA
from sklearn.decomposition import PCA
pca_y = PCA(n_components=160)
PC_y = pca_y.fit_transform(X_y)
print(PC_y.shape) # (470, 160)
# 2020年度データ
df_y_2020 = pd.read_csv('./df_yt_C10_sn_2020.csv')
print(df_y_2020.shape) # (47, 162)
# 数値部分
X_y_2020 = df_y_2020.iloc[:,2:]
print(X_y_2020.shape) # (47, 160)
# 上と同じスケーリングの変換を適用
X_y_2020 = scaler_y.transform(X_y_2020)
print(X_y_2020.shape) # (47, 160)
# 上と同じPCAの変換を適用
PC_y_2020 = pca_y.transform(X_y_2020)
print(PC_y_2020.shape) # (47, 160)主成分座標平面上にプロット
2010~2019年度のデータを使ったPCAの結果の主成分座標平面上に、2020年度を追加でプロットします。
年月別
以前の記事で、PCAの結果を年月別、都道府県別に色分けして図示(左側が年月別の色分け、右側が都道府県別の色分け)しましたが、それと同じ平面上に2020年度を追加でプロットします。
左側の年月別の色分けでは2020年度は黒色で、右側の都道府県別の色分けでは2020年度も同じ都道府県別の色で表示しました。
# プロット
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
# 2010-2019年度データ_年月ym
le.fit(df_ym['ym'])
label_ym = le.transform(df_ym['ym'])
cp = sns.color_palette('hls', n_colors=10*12+1)
color_ym = [cp[x] for x in label_ym]
# 2010-2019年度データ_都道府県t
le.fit(df_ym['t'])
label_t = le.transform(df_ym['t'])
cp = sns.color_palette('hls', n_colors=47+1)
color_t = [cp[x] for x in label_t]
# 2020年度データ_都道府県t
le.fit(df_ym_2020['t'])
label_t_2020 = le.transform(df_ym_2020['t'])
cp = sns.color_palette('hls', n_colors=47+1)
color_t_2020 = [cp[x] for x in label_t_2020]
n = 10
for i in range(n-1):
for j in range(i+1,n):
if (i==0 or j==i+1):
print('PC{} x PC{}'.format(i+1, j+1))
plt.figure(figsize=(12,5))
plt.subplot(1, 2, 1)
plt.title('PC{} x PC{}, colored by ym'.format(i+1, j+1))
plt.xlabel('PC{}'.format(i+1))
plt.ylabel('PC{}'.format(j+1))
plt.scatter(x=PC_ym[:,i], y=PC_ym[:,j], c=color_ym, s=10, alpha=0.5)
plt.scatter(x=PC_ym_2020[:,i], y=PC_ym_2020[:,j], c='black', s=10)
plt.subplot(1, 2, 2)
plt.title('PC{} x PC{}, colored by t'.format(i+1, j+1))
plt.xlabel('PC{}'.format(i+1))
plt.ylabel('PC{}'.format(j+1))
plt.scatter(x=PC_ym[:,i], y=PC_ym[:,j], c=color_t, s=10, alpha=0.2)
plt.scatter(x=PC_ym_2020[:,i], y=PC_ym_2020[:,j], c=color_t_2020, s=10)
plt.show()




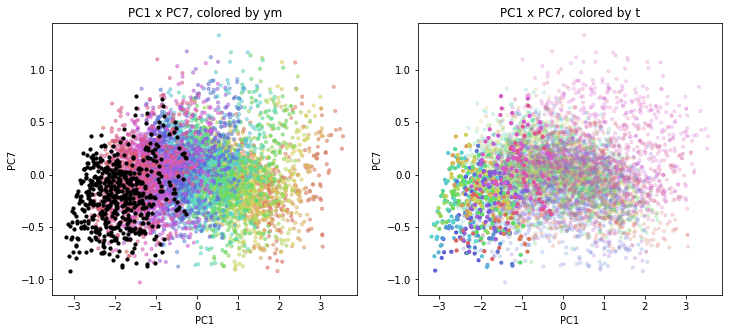






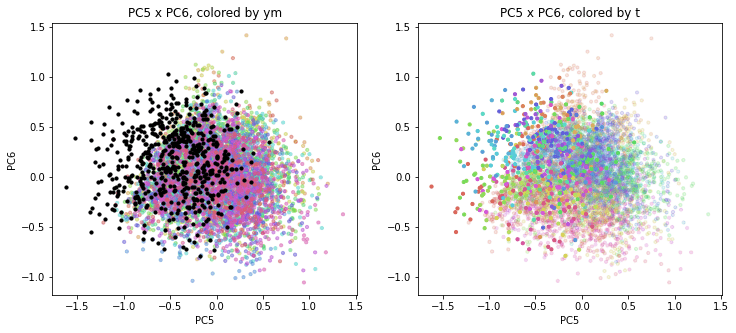

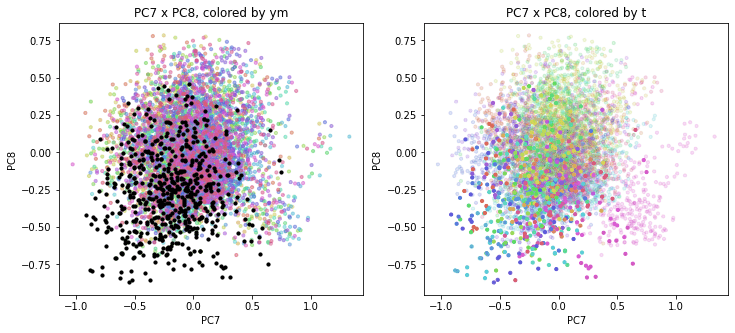


2020年度は、PC1方向(時間軸)を見ると2010~2019年度の延長上にあるような感じですが、PC2以降の座標は2010~2019年度までとは色の出方やプロットの位置がかなり違っているように見えます。
年度別
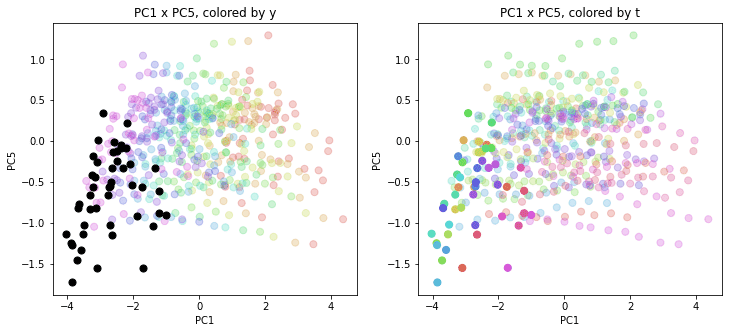
以前の記事で、PCAの結果を年度別、都道府県別に色分けして図示(左側が年度別の色分け、右側が都道府県別の色分け)しましたが、それと同じ平面上に2020年度を追加でプロットします。
左側の年度別の色分けでは2020年度は黒色で、右側の都道府県別の色分けでは2020年度も同じ都道府県別の色で表示しました。2010~2019年度のプロットは色を少し薄くしてあります。
# プロット
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
# 2010-2019年度データ_年度y
le.fit(df_y['y'])
label_y = le.transform(df_y['y'])
cp = sns.color_palette('hls', n_colors=10+1)
color_y = [cp[x] for x in label_y]
# 2010-2019年度データ_都道府県t
le.fit(df_y['t'])
label_t = le.transform(df_y['t'])
cp = sns.color_palette('hls', n_colors=47+1)
color_t = [cp[x] for x in label_t]
# 2020年度データ_都道府県t
le.fit(df_y_2020['t'])
label_t_2020 = le.transform(df_y_2020['t'])
cp = sns.color_palette('hls', n_colors=47+1)
color_t_2020 = [cp[x] for x in label_t_2020]
n = 10
for i in range(n-1):
for j in range(i+1,n):
if (i==0 or j==i+1):
print('PC{} x PC{}'.format(i+1, j+1))
plt.figure(figsize=(12,5))
plt.subplot(1, 2, 1)
plt.title('PC{} x PC{}, colored by y'.format(i+1, j+1))
plt.xlabel('PC{}'.format(i+1))
plt.ylabel('PC{}'.format(j+1))
plt.scatter(x=PC_y[:,i], y=PC_y[:,j], c=color_y, s=50, alpha=0.3)
plt.scatter(x=PC_y_2020[:,i], y=PC_y_2020[:,j], c='black', s=50)
plt.subplot(1, 2, 2)
plt.title('PC{} x PC{}, colored by t'.format(i+1, j+1))
plt.xlabel('PC{}'.format(i+1))
plt.ylabel('PC{}'.format(j+1))
plt.scatter(x=PC_y[:,i], y=PC_y[:,j], c=color_t, s=50, alpha=0.3)
plt.scatter(x=PC_y_2020[:,i], y=PC_y_2020[:,j], c=color_t_2020, s=50)
plt.show()













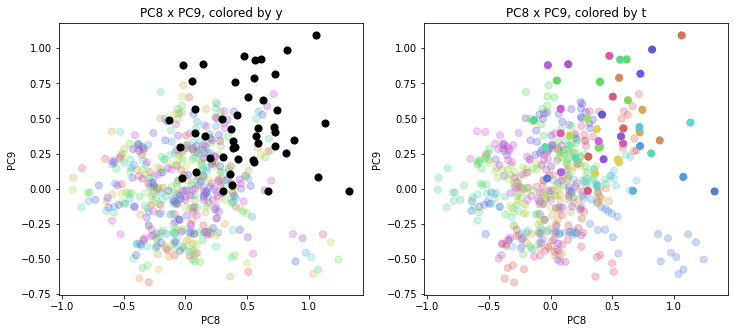

都道府県番号もプロットしておきます。
2020年度のプロットは文字を少し大きくしてあります。
n = 10
for i in range(n):
for j in range(i+1,n):
if (i==0 or j==i+1):
print('PC{} x PC{}'.format(i+1, j+1))
xmin = min([min(PC_y[:,i]), min(PC_y_2020[:,i])])
xmax = max([max(PC_y[:,i]), max(PC_y_2020[:,i])])
ymin = min([min(PC_y[:,j]), min(PC_y_2020[:,j])])
ymax = max([max(PC_y[:,j]), max(PC_y_2020[:,j])])
plt.figure(figsize=(12,5))
plt.subplot(1, 2, 1)
plt.title('PC{} x PC{}, colored by y'.format(i+1, j+1))
plt.xlabel('PC{}'.format(i+1))
plt.ylabel('PC{}'.format(j+1))
plt.xlim(xmin-(xmax-xmin)/20, xmax+(xmax-xmin)/20)
plt.ylim(ymin-(ymax-ymin)/20, ymax+(ymax-ymin)/20)
for p in range(10*47):
plt.text(x=PC_y[:,i][p], y=PC_y[:,j][p], s=df.iloc[:,1][p],
ha='center', va='center', fontsize=10, color=color_y[p])
for p in range(47):
plt.text(x=PC_y_2020[:,i][p], y=PC_y_2020[:,j][p], s=df_y_2020.iloc[:,1][p],
ha='center', va='center', fontsize=15, color='black')
plt.subplot(1, 2, 2)
plt.title('PC{} x PC{}, colored by t'.format(i+1, j+1))
plt.xlabel('PC{}'.format(i+1))
plt.ylabel('PC{}'.format(j+1))
plt.xlim(xmin-(xmax-xmin)/20, xmax+(xmax-xmin)/20)
plt.ylim(ymin-(ymax-ymin)/20, ymax+(ymax-ymin)/20)
for p in range(10*47):
plt.text(x=PC_y[:,i][p], y=PC_y[:,j][p], s=df.iloc[:,1][p],
ha='center', va='center', fontsize=10, color=color_t[p])
for p in range(47):
plt.text(x=PC_y_2020[:,i][p], y=PC_y_2020[:,j][p], s=df_y_2020.iloc[:,1][p],
ha='center', va='center', fontsize=15, color=color_t_2020[p])
plt.show()













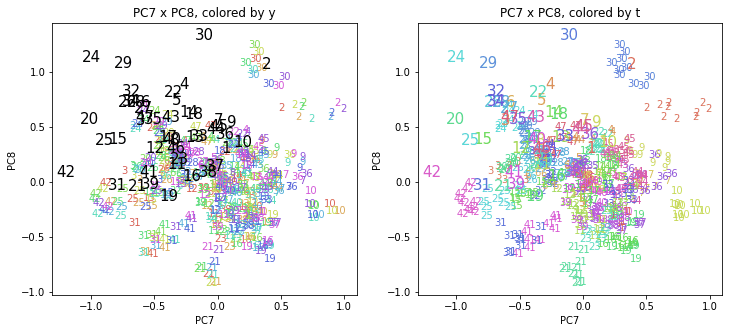


2020年度は、2010~2019年度までとかなり違った位置に現れています。
おわりに
今回は、以前に行った2010年度(平成22年度)~2019年度(令和元年度)の10年間の都道府県別の医療費データの主成分分析(PCA)の結果と同じ主成分座標平面上に、新型コロナウイルス感染症の影響が強く出ていると思われる2020年度(令和2年度)のデータをプロットしてみました。2020年度は2010~2019年度までの傾向とかなり違っていたことが確認できました。
最後まで読んでいただき、ありがとうございました。
お気づきの点等ありましたら、コメントいただけますと幸いです。
#医療費 , #医療費の3要素 , #医療費分析 , #医療費の地域差 , #地域差 , #地域間格差 , #機械学習 , #PCA , #主成分分析 , #新型コロナウイルス感染症 , # 2020年度 , #Python , #協会けんぽ