
[Python]医療費データを160次元から2次元に圧縮してみた:UMAPによる次元削減(続き)

はじめに
こんにちは、機械学習勉強中のあおじるです。
以前の記事
で、医療費データ(160次元)をPCA, MDS, t-SNE, UMAPによって160次元から2次元に次元削減してみました。このときは年度集計したデータを使ったのですが、今回は月別データでUMAPによる次元削減をしてみました。医療費には季節変動があることが知られていますので、それが見られることを期待して行いました。
言語はPython、環境はGoogle Colaboratoryを使用しました。
使用するデータ
データは、以前の記事で作成した、全国健康保険協会(協会けんぽ)の加入者基本情報、医療費基本情報から作成した、10年間の120か月×47都道府県ごとの医療費の160次元のデータ(性別、年齢階級別の診療種別ごとの「医療費の3要素」)df_ymt_C10_sn を使います。
(120か月×47都道府県)×(10指標×性別2区分×年齢階級8区分)
= 5640行 × 160次元
の形のデータです。
$$
\def\arraystretch{1.5}
\begin{array}{c:c|c:c:c:c}
\texttt{ym} & \texttt{t} & \texttt{KperP\_1\_1\_1} & \texttt{KperP\_1\_1\_2} & \cdots & \texttt{TperN\_4\_2\_8} \\ \hline
201004 & 1 & {} & {} & {} & {} \\
201004 & 2 & {} & {} & {} & {} \\
\vdots & \vdots & \vdots & \vdots & \ddots & \vdots \\
201004 & 47 & {} & {} & {} & {} \\
201005 & 1 & {} & {} & {} & {} \\
\vdots & \vdots & \vdots & \vdots & \ddots & \vdots \\
202003 & 47 & {} & {} & {} & {}
\end{array}
$$
スケールの異なる3要素のデータですので、以前の記事と同じく、スケーリングして用います。
import pandas as pd
# 2010-2019年度データ
df_ym = pd.read_csv('./df_ymt_C10_sn.csv')
print(df_ym.shape) # (5640, 162)
# 数値部分のみ取り出し
X_ym = df_ym.iloc[:,2:]
print(X_ym.shape) # (5640, 160)
# スケーリング
from sklearn import preprocessing
scaler_ym = preprocessing.MinMaxScaler()
X_ym = scaler_ym.fit_transform(X_ym)
print(X_ym.shape) # (5640, 160)結果の表示は、以前の記事では、年度yごとと都道府県tごとに色分けしましたが、今回は、年月ymごと、都道府県tごとの他に、年度yごと、月mごとにも色分けして図示することにしました。
# 年度(y)と月(m)の追加
df_ym['y'] = df_ym['ym'] // 100
df_ym['y'] = df_ym['y'].where(df_ym['ym'] % 100 >= 4, df_ym['y']-1)
df_ym['m'] = df_ym['ym'] % 100
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
# 年月ym
label_ym = le.fit_transform(df_ym['ym'])
cp = sns.color_palette("hls", n_colors=10*12+1)
color_ym = [cp[x] for x in label_ym]
# 都道府県t
label_t = le.fit_transform(df_ym['t'])
cp = sns.color_palette("hls", n_colors=47+1)
color_t = [cp[x] for x in label_t]
# 年度y
label_y = le.fit_transform(df_ym['y'])
cp = sns.color_palette("hls", n_colors=10+1)
color_y = [cp[x] for x in label_y]
# 月m
label_m = le.fit_transform(df_ym['m'])
cp = sns.color_palette("hls", n_colors=12+1)
color_m = [cp[x] for x in label_m]UMAPによる次元削減
この160次元のデータをUMAPで2次元へ圧縮します。
結果の図は、左上が年月ごとの色分け、右上が都道府県ごとの色分け、左下が年度ごとの色分け(年月ごとの色分けとほぼ同様)、右下が月ごとの色分けになっています。
! pip install umap-learn
import umap.umap_ as umap
list_n_neighbors = [2,3,4,5,10,15,20,30,40,50,75,100,150,200,300,500,750,
1000,1200,1500,2000]
for n_neighbors in list_n_neighbors:
reducer = umap.UMAP(n_components=2, n_neighbors=n_neighbors, random_state=0)
reducer.fit(X_ym)
embedding = reducer.transform(X_ym)
print(embedding.shape) # (5640, 2)
alg = 'UMAP' # algorithm
param = 'n_neighbors='+str(n_neighbors) # parameter
i = 0
j = 1
print('{}, {}'.format(alg,param))
plt.figure(figsize=(12,12))
plt.subplot(2, 2, 1)
plt.title('{}, {}, colored by ym'.format(alg,param))
plt.xlabel('{}_{}'.format(alg,i+1))
plt.ylabel('{}_{}'.format(alg,j+1))
plt.scatter(x=embedding[:,i], y=embedding[:,j], c=color_ym, s=4)
plt.subplot(2, 2, 2)
plt.title('{}, {}, colored by t'.format(alg,param))
plt.xlabel('{}_{}'.format(alg,i+1))
plt.ylabel('{}_{}'.format(alg,j+1))
plt.scatter(x=embedding[:,i], y=embedding[:,j], c=color_t, s=4)
plt.subplot(2, 2, 3)
plt.title('{}, {}, colored by y'.format(alg,param))
plt.xlabel('{}_{}'.format(alg,i+1))
plt.ylabel('{}_{}'.format(alg,j+1))
plt.scatter(x=embedding[:,i], y=embedding[:,j], c=color_y, s=4)
plt.subplot(2, 2, 4)
plt.title('{}, {}, colored by m'.format(alg,param))
plt.xlabel('{}_{}'.format(alg,i+1))
plt.ylabel('{}_{}'.format(alg,j+1))
plt.scatter(x=embedding[:,i], y=embedding[:,j], c=color_m, s=4)
plt.show()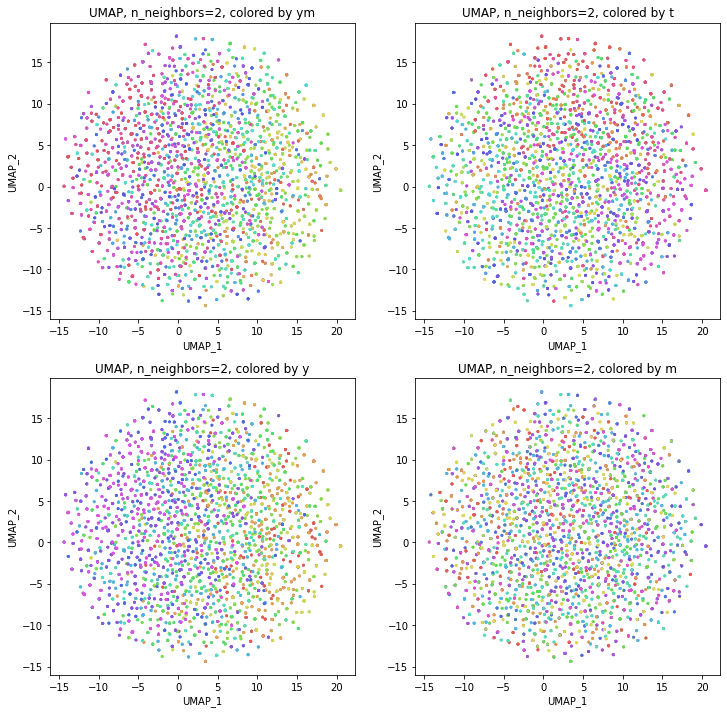
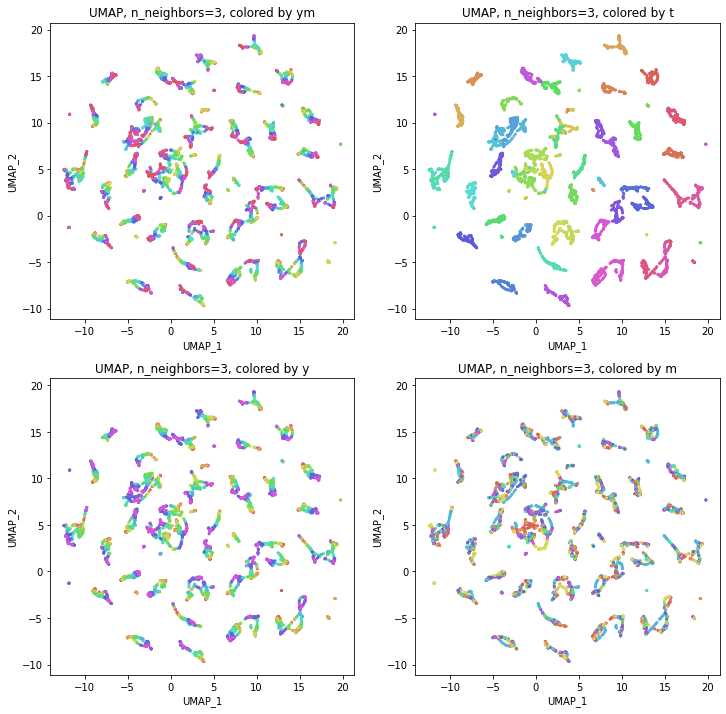

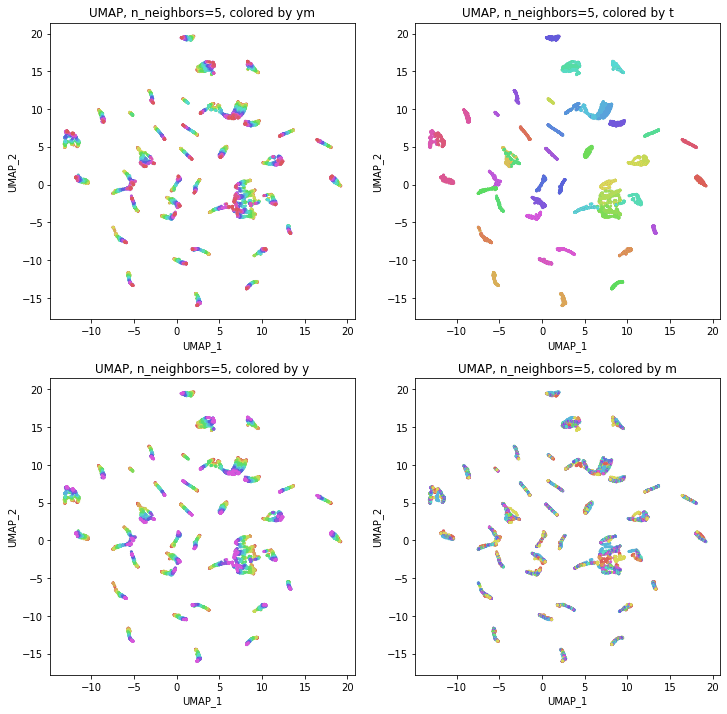





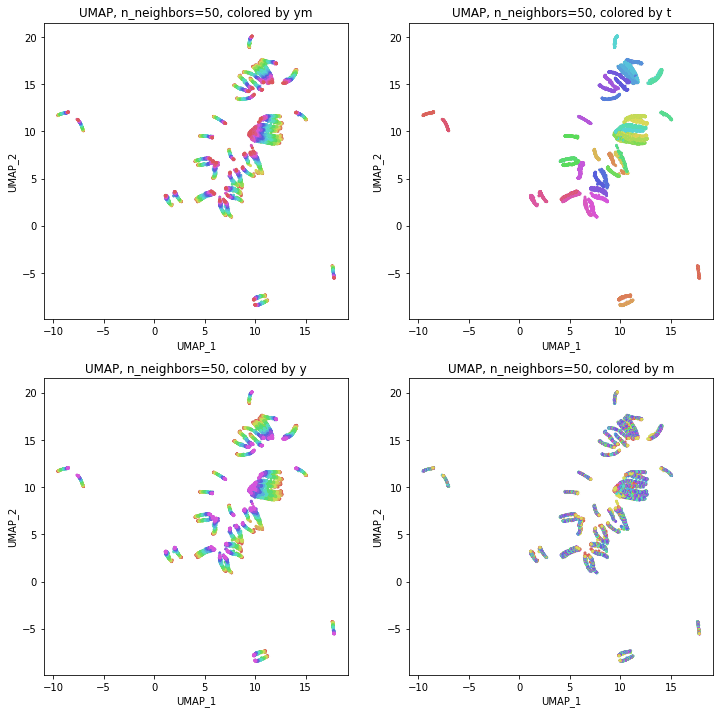



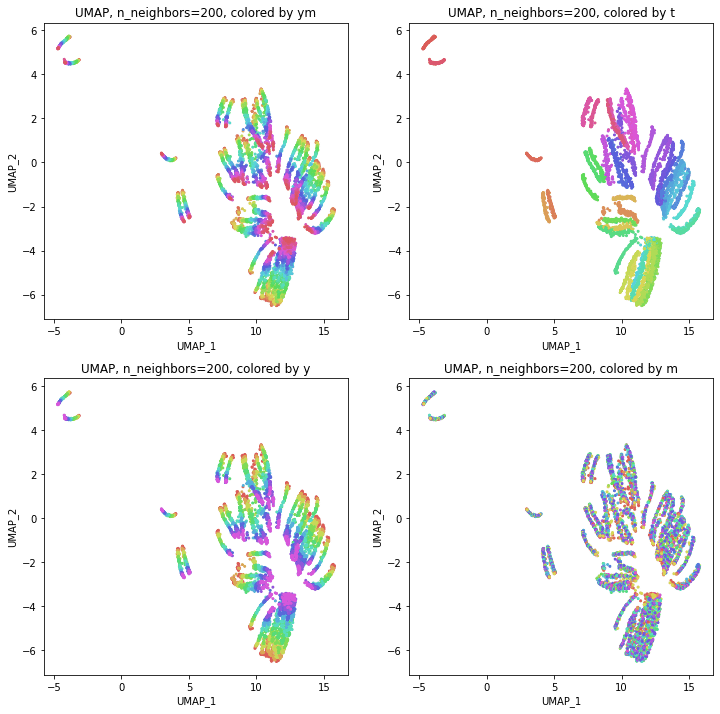







結果は、年度別のデータからUMAPで次元削減したのときと同じような形になりました。つまり、パラメータn_neighborsの値が小さいうちは都道府県ごとに分かれていて年度の向きはバラバラで、パラメータn_neighborsの値を上げていくとだんだん年度の向きがそろってきて、さらに上げていくと年度の向きが完全にそろってきてPCAの結果に近い形になっていきました。
季節(月)の影響が見られことを期待して月別の色分けもしてみましたが、特に季節性らしきものはこの2次元プロットでは見られませんでした。
おわりに
今回は、月別の医療費データを使って、UMAPで160次元から2次元に圧縮してみました。年度のデータでUMAPを実行したときとほとんど同じ結果が得られました。季節性が見られることも期待していましたが、特にそれらしきものは見られませんでした。
最後まで読んでいただき、ありがとうございました。
お気づきの点等ありましたら、コメントいただけますと幸いです。
#医療費 , #医療費の3要素 , #医療費分析 , #医療費の地域差 , #地域差 , #地域間格差 , #UMAP , #機械学習 , #Python , #協会けんぽ , #noteで数式
この記事が気に入ったらサポートをしてみませんか?