AWSのAIサービスを使ってみよう

このページでは、AWSのAIサービスである
・Amazon Rekognition
・Amazon Polly
・Amazon Transcribe
の3つを体験できるように作成しました。
これらは学習済みモデルを使用できるサービスになるので、
モデルを準備する必要がなく、簡単に体験できます。
本ページで指定している各サービスのパラメータは一例です。
どんな指定ができるかは、公式ドキュメントを参照してください。
事前準備
①AWSアカウント作成
まずはAWSアカウントを作成します。
以下の公式ページが分かり易いです。
②Python実行環境の準備
各サービスをAPIで実行するので、Pythonの実行環境が必要になります。
以下のページにまとめました。
③IAMユーザの作成と権限の付与
AWSサービスのAPIを使用するために、
IAMユーザの「アクセスキーID」と「シークレットアクセスキー」が必要になります。
IAMダッシュボードの画面左メニューの「ユーザー」をクリックします。
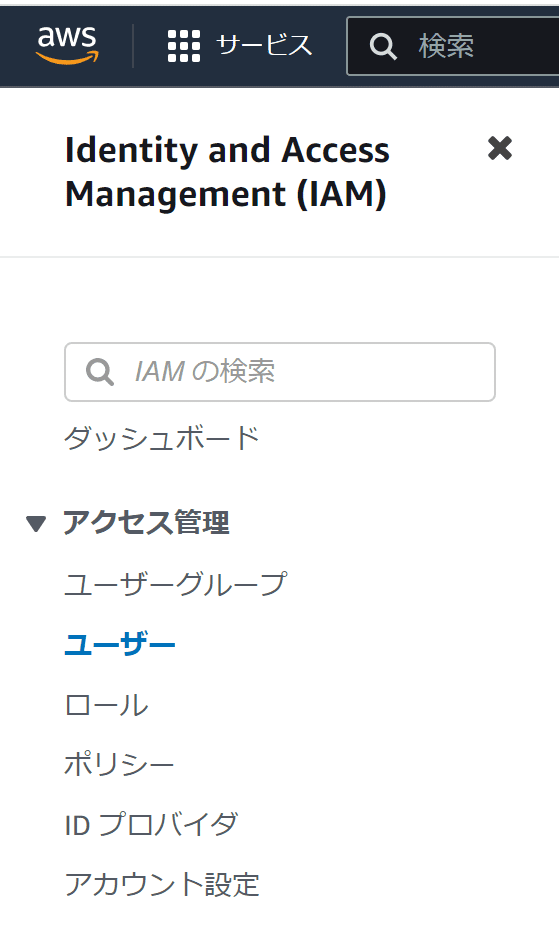
「ユーザーを追加」ボタンをクリックします。
ユーザー名を設定し、「次へ」をクリックします。
「既存のポリシーを直接アタッチ」を選択し、
サービスを使用するための権限を付与します。
例えばAmazon Rekognitionなら、「AmazonRekognitionFullAccess」にチェックを入れます。今回は以下の権限を付与しましょう。
AmazonRekognitionFullAccess
AmazonPollyFullAccess
AmazonTranscribeFullAccess
AmazonS3FullAccess
問題がなければ「ユーザーの作成」をクリックします。
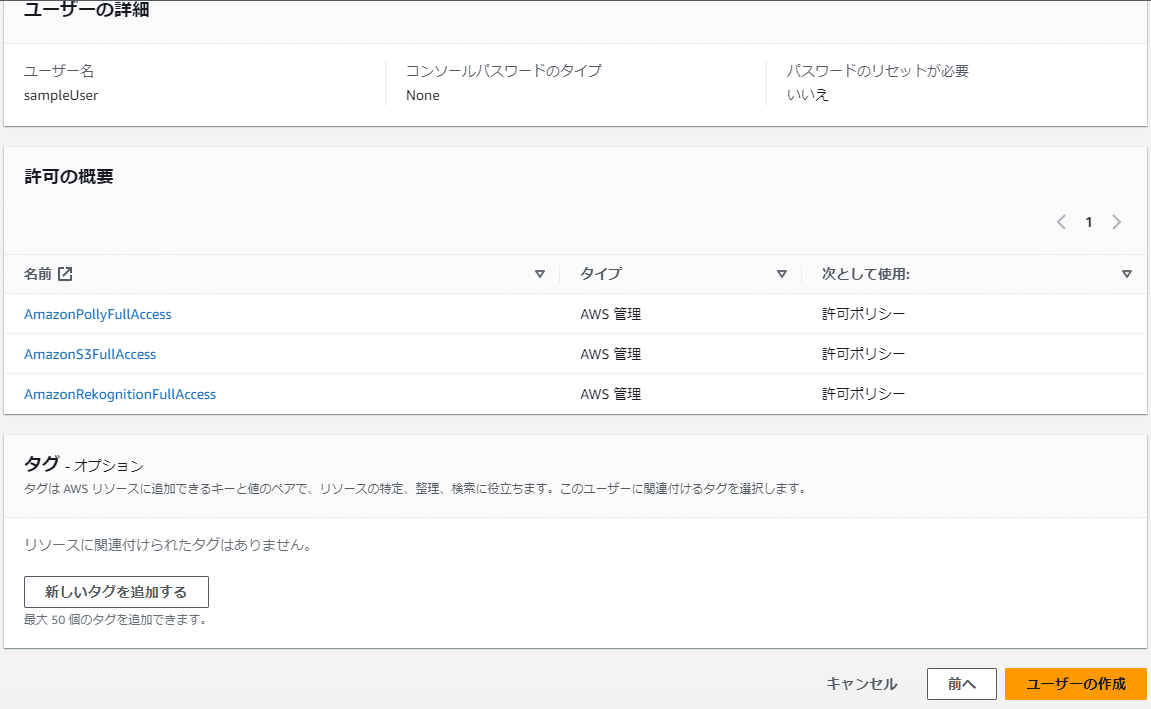
次に、アクセスキーIDとシークレットアクセスキーを作成します。
「セキュリティ認証情報」をクリック
「アクセスキーを作成」クリックします。
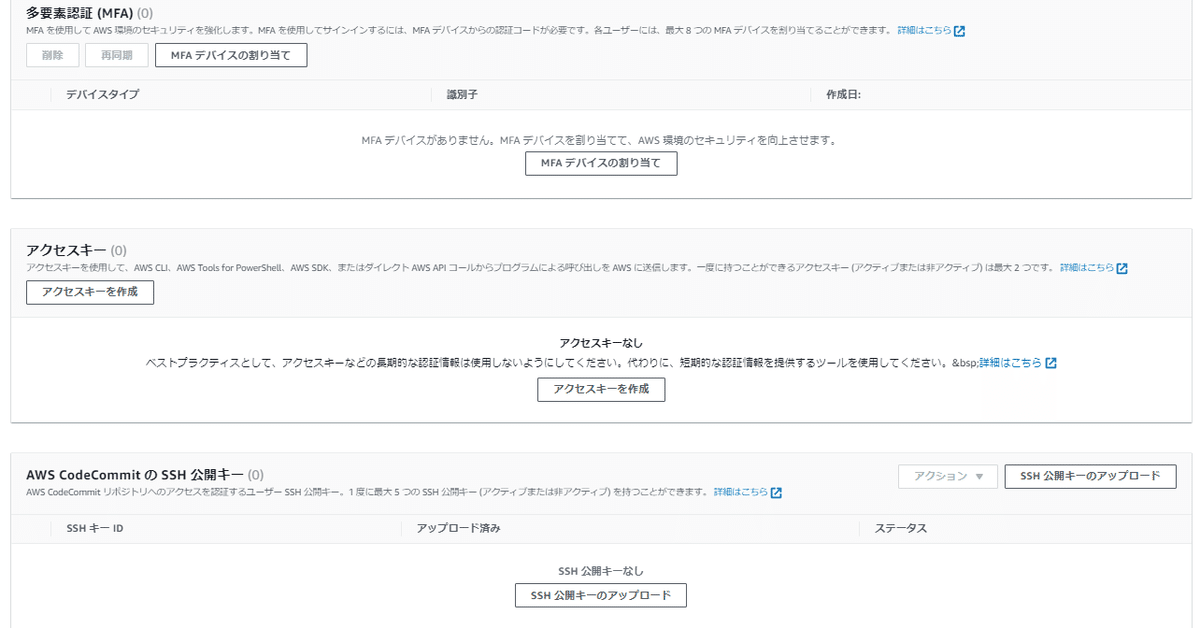
最近では、アクセスキーの作成をクリックすると、以下のページに遷移するようです。
アクセスキーの用途を聞かれています。用途によって、ベストプラクティスな代替案を案内されますが、短期の使用・終わったら無効化および削除することを前提として、「次へ」進みましょう。
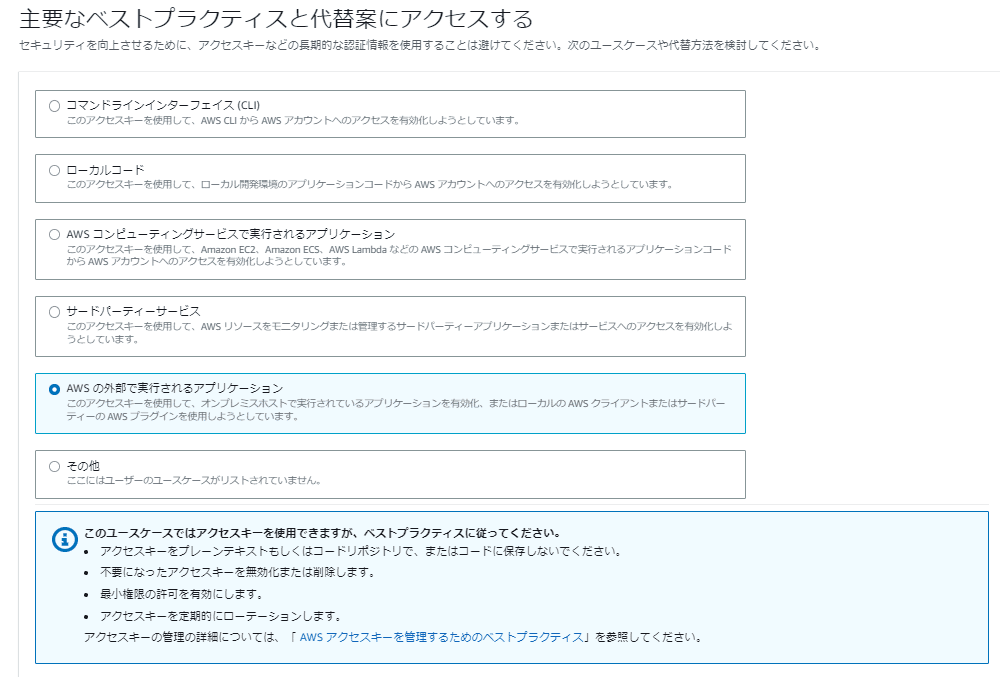
アクセスキーを作成をクリックします。

※シークレットアクセスキーが表示されるのはこの時のみなので注意。※.csvファイルとしてダウンロードすることも可能。
④認証情報ファイルの作成
Windowsの場合: C:\Users\ユーザ名\
macOSの場合: /Users/ユーザ名/
上記パスの直下に「.aws」というディレクトリを作成します。
取得したアクセスキーIDとシークレットアクセスキーを記述した「credentials」というファイルを作成します。
[default]
aws_access_key_id = <アクセスキーID>
aws_secret_access_key = <シークレットアクセスキー>⑤S3バケットにファイルをアップロードする
AWSコンソールから、S3バケットの画面を表示します。
「バケットを作成する」ボタンをクリックします。
リージョンはアジアパシフィック(東京)を選択します。
バケットを作成後、必要なファイルをアップロードします。
作成したバケットの概要画面を表示、
「アップロード」ボタンをクリックします。
アップロードしたファイルをクリックするとURLが表示されます。
ファイルの操作時に、このURLで指定します。
⑥AWS SDK for Pythonの準備
Python実行環境でboto3(AWS SDK for Python)を導入します。
以下のコマンドを実行します。
インストールが完了したら「Successfully installed」と表示されます。
!pip install --upgrade boto3S3のリスト参照を呼び出して、実行できるかを確認してみます。
import boto3
client = boto3.client('s3', region_name='ap-northeast-1')
client.list_buckets()⑦画像を表示させる場合
使用する画像を表示させたい時は、以下を実行してみてください。
S3バケットに保存した画像を指定します。
import boto3
from io import BytesIO
from PIL import Image
# S3クライアントを作成
s3 = boto3.client('s3', region_name='ap-northeast-1')
# 画像が保存されているS3バケットとファイル名を指定
bucket_name = '<バケット名>'
file_name = '<ファイル名>'
# S3から画像をダウンロード
response = s3.get_object(Bucket=bucket_name, Key=file_name)
# ダウンロードした画像をPillow Imageオブジェクトに変換
img = Image.open(BytesIO(response['Body'].read()))
# 画像を表示
img.show()Amazon Rekognition
物の画像認識
以下の画像を使って、Rekognitionを実行してみます。

コード
import boto3
# Amazon Rekognitionクライアントを作成
rekognition = boto3.client('rekognition', region_name='ap-northeast-1')
# S3のオブジェクトキーとバケット名を指定する
bucket_name = '<バケット名>'
photo_name = '<ファイル名>'
# Amazon Rekognition APIを使用して画像を認識する
response = rekognition.detect_labels(
Image={
'S3Object': {
'Bucket': bucket_name,
'Name': photo_name,
}
},
)
# 認識結果を出力する
for label in response['Labels']:
print(label['Name'], label['Confidence'])結果出力
Plant 99.95132446289062
Tree 99.95132446289062
Tree Trunk 99.95132446289062
Grass 99.89602661132812
Nature 99.89602661132812
Outdoors 99.89602661132812
Park 99.89602661132812
Flower 99.7705078125
Arbour 97.12925720214844
Garden 97.12925720214844
Person 96.7469482421875
Grove 92.72981262207031
Land 92.72981262207031
Vegetation 92.72981262207031
Woodland 92.72981262207031
Cherry Blossom 89.33689880371094
Petal 87.25791931152344
Graveyard 63.26444625854492
Spring 55.792938232421875
Cross 55.39891815185547
Symbol 55.39891815185547
Scenery 55.358051883顔の画像認識
以下のフリー画像を使って、Rekognitionで顔画像認識を実行してみます。

import boto3
# Amazon Rekognitionクライアントを作成
rekognition = boto3.client('rekognition', region_name='ap-northeast-1')
# S3のオブジェクトキーとバケット名を指定する
bucket_name = '<バケット名>'
photo_name = '<ファイル名>'
# Amazon Rekognition APIを使用して顔の画像を認識する
response = rekognition.detect_faces(
Image={
'S3Object': {
'Bucket': bucket_name,
'Name': photo_name,
}
},
Attributes=[
'ALL',
]
)
# 検出された顔の情報を出力する
for face_detail in response['FaceDetails']:
print('性別: ' + face_detail['Gender']['Value'])
print('年齢: ' + str(face_detail['AgeRange']['Low']) + '-' + str(face_detail['AgeRange']['High']) + ' 歳')
print('感情: ' + face_detail['Emotions'][0]['Type'])
print()結果出力
性別: Male
年齢: 0-3 歳
感情: CALMAmazon Polly
指定した任意のテキストを、音声に変換します。
コード
import boto3
# Amazon PollyとS3クライアントを作成
polly = boto3.client('polly', region_name='ap-northeast-1')
s3 = boto3.client('s3', region_name='ap-northeast-1')
# 音声合成のためのテキストを指定する
text = "<ここに音声にしたいテキストを入力>"
# Amazon Polly APIを使用して音声を合成する
response = polly.synthesize_speech(
Text=text,
OutputFormat='mp3',
VoiceId='Takumi'
)
# S3バケット名と音声ファイル名を指定する
bucket_name = '<バケット名>'
file_name = '<作成するファイル名>'
# 生成された音声ファイルをS3バケットに保存する
s3.put_object(
Body=response['AudioStream'].read(),
Bucket=bucket_name,
Key=file_name
)出力結果
{'ResponseMetadata': {'RequestId': 'KKWHJ3THCPYF83KT',
'HostId': '+dZUfjS9FL4bs7LnN5p9g/eR+JFfY3dy4L+6DZaPZDOnrxpKLmR1T8nsE3DQ6j+bXOGbq7Bu3JU=',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amz-id-2': '+dZUfjS9FL4bs7LnN5p9g/eR+JFfY3dy4L+6DZaPZDOnrxpKLmR1T8nsE3DQ6j+bXOGbq7Bu3JU=',
'x-amz-request-id': 'KKWHJ3THCPYF83KT',
'date': 'Sun, 09 Apr 2023 16:21:27 GMT',
'x-amz-server-side-encryption': 'AES256',
'etag': '"ecefa840a5ee1b6b216246dd1fe31e5d"',
'server': 'AmazonS3',
'content-length': '0'},
'RetryAttempts': 0},
'ETag': '"ecefa840a5ee1b6b216246dd1fe31e5d"',
'ServerSideEncryption': 'AES256'}S3の指定したバケット内にmp3ファイルが保存されるので、ダウンロードして確認します。
Amazon Transcribe
Amazon Pollyで作成されたmp3ファイルを設定して、
今度は音声からテキストに変換してみます。
コード
import boto3
# 認証情報を設定する
transcribe = boto3.client('transcribe', region_name='ap-northeast-1')
# S3のオブジェクトキーとバケット名を指定する
bucket_name = '<バケット名>'
object_key = '<ファイル名>'
object_url = '<音声ファイルのURLを入力>'
# 変換ジョブを作成する
job_name='testjob'
response = transcribe.start_transcription_job(
TranscriptionJobName=job_name,
Media={'MediaFileUri': object_url},
MediaFormat='mp3',
LanguageCode='ja-JP'
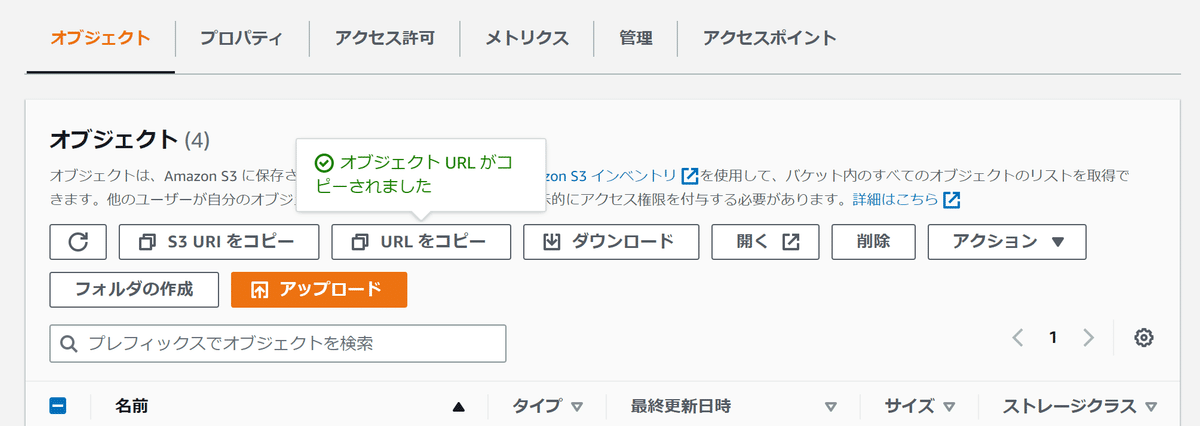
)S3のバケットに格納されたファイルのURLは、
バケット内のファイル一覧から該当のファイルを選択した状態で「URLをコピー」をクリックすると、取得できます。
job確認
status = transcribe.get_transcription_job(TranscriptionJobName=job_name)
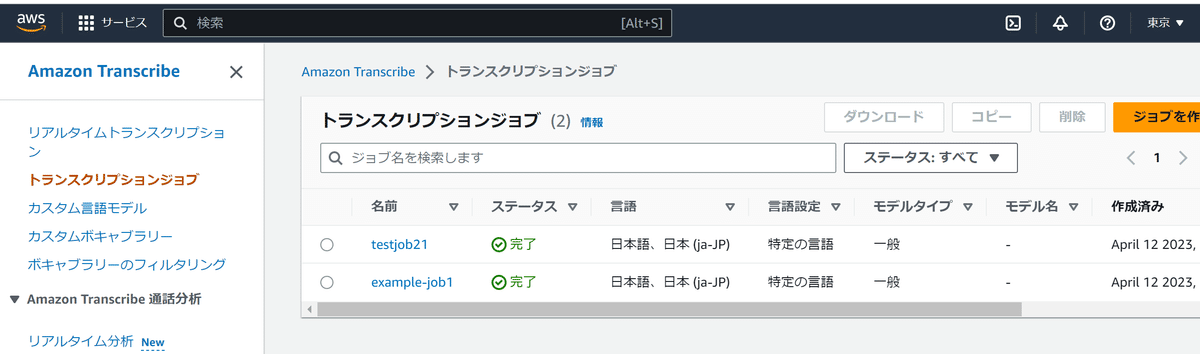
print(response)実行されたジョブは、Amazon Transcribeの「トランスクリプションジョブ」で確認ができます。
該当のジョブの名前をクリックすると、変換されたテキストを確認することができます。
後片付け
体験後は、
使わなくなったIAMユーザや認証ファイル、S3バケット等を削除してください。