二分探索木

参考
各ノードは親へのリンク無し、削除操作あり。
各ノードに親へのリンク有り、削除操作あり。
根付き木(Rooted Tree)
最上位の親ノードである、ルートノードが存在する。
ルートノードは親ノードを持たない唯一のノードである。
二分木(Binary Tree)
ルートがある。
各ノードに各々2つの子がある。
逆に言えばそれ以外の条件はない。
データ構造であるからには
格納すべきデータと
他のノードへのポインタないし参照が
実装の本丸である。
二分木のノードクラスはコード的には以下で済む
class BinaryTreeNode<T>
{
T Value;
BinaryTreeNode Left;
BinaryTreeNode Right;
}木構造であるためには、
ここにデータ構造に対する演算
検索、探索(search, find, )
追加、挿入(add, insert)
削除(delete, remove)
を定義する必要がある。
とりわけ木構造であるからには、
木構造として格納することにメリットがなければ意味がない。
木構造として格納する代表的なメリット、その具体的な例の一つは二分探索木である。
二分探索木はノードの格納方法にルールを設け、木構造にデータを格納した瞬間にソートが完了する。また、データがソート済みであるため、データのの検索時間が短縮される。
ひるがえってデータ構造としての木構造に必要なものは
格納すべきデータ
ノード間のポインタないし参照
データ構造、木構造に対する追加や削除などの演算
ノード格納に関するルール
である。
二分探索木(Binary Search Tree)
左子<親<右子となるルールを設ける。
あるいは
左子<親<=右子
左子<=親<右子
左子>親>右子
などのパターンとなる。
注意すべきはノード自体とノードが格納する値は別ということ。これら左右の子への参照機構さえ有すれば、そのクラスは二分木のノードとしての役割を果たすということである。
二分探索木は順序構造を持つので、processingだと
class BinarySearchTreeNode<T extends Comparable<T>>
{
//なんらかのValue,ただしComperableを実装
T Value;
BinarySearchTreeNode<T> Left;
BinarySearchTreeNode<T> Right;
}T型が嫌いな人は頭の中で以下のように読み替える。
class BinarySearchTreeNode
{
int Value;
BinarySearchTreeNode Left;
BinarySearchTreeNode Right;
}C#だと
class BinarySearchTreeNode<T> where T : IComparable<T>
{
T Value { get; set; }
BinarySearchTreeNode<T> Left { get; set; }
BinarySearchTreeNode<T> Right { get; set; }
}二分木の時は何でもよかったT型が、二分探索木では比較可能である必要がある。比較可能であるとは、比較演算子>とか<とか>=とか<=にひっかけることができるということである。
さらに便利に、しかし複雑にするならば、ノード内部のkeyと値を分けるという方向になる。これは木の探索には互いに比較可能なkey値を手掛かりとし、格納する値は比較可能でなくとも良いというやり口になる。
//processing
class KeyValueNode<K extends Comparable<K>, V>
{
KeyValueNode<K,V> Parent;
K Key;//Comperable可能なkey
V Value;
KeyValueNode<K,V> Left;
KeyValueNode<K,V> Right;
//コンストラクタ
KeyValueNode(K key_, V value_)
{
this.Key = key_;
this.Value = value_;
}
}比較可能な最も単純なクラスはint, float, doubleである。javaではInteger, Float, Double。すなわちこれらの基本的な型は、特に余計な実装もなく、二分探索木のノードのkey値として使用できる。
自分で作ったクラスを二分探索木のノードのkey値として使用可能、すなわち比較可能にするには、ノードに格納したいクラスにComparableインターフェースを実装する必要がある。javaだと
public class Vector2D implements Comparable<Vector2D>
{
double X;
double Y;
double Length(){return Math.sqrt(X*X+Y*Y);}
@Override
public int compareTo(Vector2D other)
{
//other値の方が大ならば負値を返す
//thisの値の方が大ならば正値を返す
//Xで比較する
//return Double.compare(this.X, other.X);
//Yで比較する
//return Double.compare(this.Y, other.Y);
//長さで比較する
//return Double.compare(this.Length(), other.Length());
}
}compareToは比較の相手方(入力値other)が大きい場合に負値を返せば良い。
なので簡単に実装するなら以下でも良いが、この実装だと計算値がオーバーフローする可能性がある。
@Override
public int compareTo(Vector2D other)
{
return this.X-other.X;
}C#(IComparable)の場合、入力がobjectでありキャストが必要。逆に言えばキャストさえすればいかなるクラスも比較可能となる。
public int CompareTo(object obj)
{
if (obj == null) return 1;//無よりはthisが大きい
var other_v = obj as Vector2D ;
if (other_v == null) return 1;//無よりはthisが大きい
//Xで比較する
//return this.X.CompareTo(other_v.X);
}C#(IComparable<T>)の場合。
public int CompareTo(Vector2D other)
{
if (other == null) return 1;
return this.X.CompareTo(other.X);
}ここまでは木構造のノードと、それに格納するkey値および値が備えるべき性質の話。
二分探索木の場合、ここに探索、追加、削除なる操作が加わって初めてデータ構造としての意味を持つ。
探索操作
関数名はFindとかContainとかでも良い。
木構造の中に、入力key値に等しいkey値が存在するか否か探す。keyとなる値を保持するノードを探す。
二分探索木はノード間の大小関係が既に明らかであるはずなので(そのルールが保たれていないならば二分探索木ではないので)、あるノードのkey値より入力のkey値が大なら右のノードへ、小なら左のノードへと進み、一致したなら探索を完了するというふうにする。さすれば高速で探索が終わるはずである。
//processing
BinarySearchTreeNode Search(BinarySearchTreeNode start_node, BinarySearchTreeNode node)
{
BinarySearchTreeNode current = start_node;
while(true)
{
//引数の方が大きいならreturn -1
//引数の方が小さいならreturn +1
if(current.Value.compareTo(node.Value)<0)
{
//入力の方が大
current = current.Right;
if(current == null){return null;}//終了:発見できないまま末端に達した
}
else if(current.Value.compareTo(node.Value)>0)
{
//入力の方が小
current = current.Left;
if(current == null){return null;}//終了:発見できないまま末端に達した
}
else//等しい:発見できた
{
return current;
//終了
}
}
}あるkeyが木に含まれるか否かを判定するだけならbooleanを返すようにすればよく、key値を手掛かりに二分探索し、ノードに格納されているなにか別のデータを利用するようならそのままノード、あるいはデータを返すようにすればよい。
実装方法はいろいろあって
プログラミングコンテスト攻略のためのアルゴリズムとデータ構造 (日本語) 単行本(ソフトカバー) – 2015/1/30
のP215
//疑似コード
BinarySearchTreeNode Search(BinarySearchTreeNode start_node, T key)
{
BinarySearchTreeNode current = start_node;
while(curren!=null&&key!=current.Value)
{
if(key<current.Value)
{
current = current.Left;
}
else
{
current = current.Right;
}
}
//末端に達するか、目的値を発見した場合whileを抜ける
return current;//未発見ならnullを返す
}再帰だと
プログラミングコンテストチャレンジブック [第2版] ~問題解決のアルゴリズム活用力とコーディングテクニックを鍛える~ 単行本(ソフトカバー) – 2012/1/28 P78
//疑似コード
BinarySearchTreeNode Search(BinarySearchTreeNode start_node, T key)
{
BinarySearchTreeNode current = start_node;
if(current==null){return null;}
else if(x==current.Value){return current;}//発見した
else if(x<current.Value){return Search(current.Left, key);}//左子へ
else return Search(current.Right, key);//右子へ
}応用するとノードの深さ(Rootから目的ノードまでのエッジ数,Rootの深さ=0)を得ることができたりもする。
//processing
int GetDepth(BinarySearchTreeNode start_node, BinarySearchTreeNode node)
{
int depth = 0;
BinarySearchTreeNode current = start_node;
while(true)
{
//引数の方が大きいならreturn -1
//引数の方が小さいならreturn +1
if(current.Value.compareTo(node.Value)<0)
{
current = current.Right;//右子に移動
if(current == null){return depth;}//終了:発見できなかった
depth++;
}
else if(current.Value.compareTo(node.Value)>0)
{
current = current.Left;//左子に移動
if(current == null){return depth;}//終了:発見できなかった
depth++;
}
else//等しい:発見できた
{
//return current;
return depth;
//終了
}
}
}木構造が同一のkey値を許容する場合、処理の仕方が少し変わる。この場合素直な二分探索を行うと、最初に見つかったノードが返されることとなり、目的のノードにたどり着かない場合がある。
key値となるT型、あるいはノードに対するReference Equalsを用いればkey値が同一であってもノード毎の区別がつくが、このやり方はあるノードの性質を調べたい時、すでに調べたいノードの参照が手元にある場合に限られる。
Reference Equalsは言語ごとにそのやり方は異なるが、クラスのインスタンスの同一性を判断するものである。すなわちメモリ上の同じ領域にあるデータであるか否かを判断するやり口であって、簡単に言うとnewしたインスタンスが既存のインスタンスとReference Equalsでtrueになることは、なんか余計なことをしない限りない。
つまりReference Equalsによる比較は、上記GetDepth()や、下記で少し触れている、あるノードの親を取得するような場合でのみ使えるのであって、まっさらなkey値による探索では木構造内に同一値があった場合に区別はつかない。
追加操作
あるいは挿入(Insert)処理
探索し、子ノードがnullならばその場所に新規にノードを追加する。
二分探索木においては、ノードの追加は木が伸びるという形で行われる。例えば単純なリスト構造だと、ノードの追加は参照の繋ぎ直しが必要になる場合があるが、二分探索木ならばそのような手間は不要。新規の要素が既存の要素の間に割って入ったとしても木が伸びるだけである。新規の要素は常に木の末端に位置する。
boolean Add(BinaryTreeNode start_node, BinaryTreeNode node)
{
BinaryTreeNode current = start_node;
while(true)
{
//引数の方が大きいならreturn -1
//引数の方が小さいならreturn +1
if(current.Value.compareTo(node.Value)<0)
{
if(current.Right == null)
{
current.Right=node;
return true;//成功
}
else{current = current.Right;}//次のノードへ
}
else if(current.Value.compareTo(node.Value)>0)
{
if(current.Left == null)
{
current.Left=node;
return true;//成功
}
else{current = current.Left;}//次のノードへ
}
else//等しい:受け入れ拒否
{
return false;
}
}//while
return true;
}プログラミングコンテスト攻略のためのアルゴリズムとデータ構造 (日本語) 単行本(ソフトカバー) – 2015/1/30 P212
の場合、子ノードが親ノードへの参照を持っている。すなわち木構造を逆向きに辿れる。二分探索木自体は必ずしも各ノードに親ノードへの参照を保持する必要はないが、使う分にはあった方が便利である。作る分には無い方が良い。
参照を増やした場合、ノードを操作するごとに全ての参照に関してきっちり処理していかなければならない手間が増える。
二分探索木の場合、必ず必要な参照は各ノードから左右の子へ渡る2つ。親からそのノードへ渡る1つの合計3本である。
ここに、あるノードから親へ向かう参照を追加すると、パッと見の参照の合計は4本であろうが、実際の操作においてはあるノードがその左右の子から渡ってこられるノードも考慮する必要があるため、6本である。
すなわち子から親に向かって渡ることができるという道筋を作るだけで、各ノードは往路と復路を考える必要が出てくるのであって、手間暇2倍である。あと、自分で実装すると必ずバグる。
それほど面倒であっても、最終的には子から親へは渡れた方が便利である。
あるノードの左の子から右の子に渡ろうと考えた場合、一度親ノードを経由する必要がある。
あるノードを移動ないし削除ないしする場合、そのノードは親ノードから離脱する必要があり、その際には親ノードの情報が必要となる。
各ノードが親ノードへの参照を保持しているか、あるいは親の情報をどこか別の辞書なりに保存していない場合、親ノードは木構造をルートから辿りなおさなければ取得できない。とりわけ木構造が同一key値を許容しているなら、子ノードに関するReference Equalsを行わなければ必ずしも正しい親ノードは取得できない。
あるいは親情報が必要な操作をする際に、常に親情報をどこかに保持しながら操作を進めていく方法もあるが、これらのことは要するに面倒である。
各ノードが親ノードへの参照を持つ場合、親ノードがnullならばそれすなわちRootであるという判定が可能となる。
Rootへの参照はどこかに保持しておくと便利であるが、親ノードがnullであることを利用すれば、適当なノードからでもRootを取得できる。
以下は
プログラミングコンテスト攻略のためのアルゴリズムとデータ構造 (日本語) 単行本(ソフトカバー) – 2015/1/30 P212
の挿入操作
//疑似コード
void Add(BinarySearchTreeNode start_node, BinarySearchTreeNode node)
{
BinarySearchTreeNode parent = null;
BinarySearchTreeNode current = start_node;
while(current!=null)
{
parent = current;//親ノードを保持しながら木構造を下へ
if(node.Value<current.Value)
{
current=current.Left;
}
else
{
current=current.Right;
}
}
//末端に到着
//新規追加ノードの参照を整える
//新規追加ノードに子は無いか、あるいは既に整ってると考えて触る必要はない
//新規追加ノードから親ノードへ
node.Parent = parent;
//親ノードから子ノードへ
if(node.Value<parent.Value)
{
parent.Lfet=node;
}
else
{
parent.Right=node;
}
//これで合計4本の参照が整った
//実際に整えたのは2本
再帰の場合
プログラミングコンテストチャレンジブック [第2版] ~問題解決のアルゴリズム活用力とコーディングテクニックを鍛える~ 単行本(ソフトカバー) – 2012/1/28 P78
こちらは親ノードへの参照が無いケース。この場合、整えるべき参照は親から子への1本のみ。
BinarySearchTreeNode Add(BinarySearchTreeNode current , BinarySearchTreeNode node)
{
if(current == null)
{
//木の末端、再帰の終焉
return node;
}
else
{
if(node.Value<current.Value)
{
current.Left = Add(current.Left, node);
}
else
{
current.Right = Add(current.Right, node);
}
return current;//最終的に最初に入力したstartノードが返る
}
}削除操作
削除のルールはwikipediaによれば
・削除対象ノードが子を持たないならそのまま削除する。
・削除対象ノードが子ノードを左右のどちらかしかもっていない場合は、削除ノードを削除してその子と置き換える。
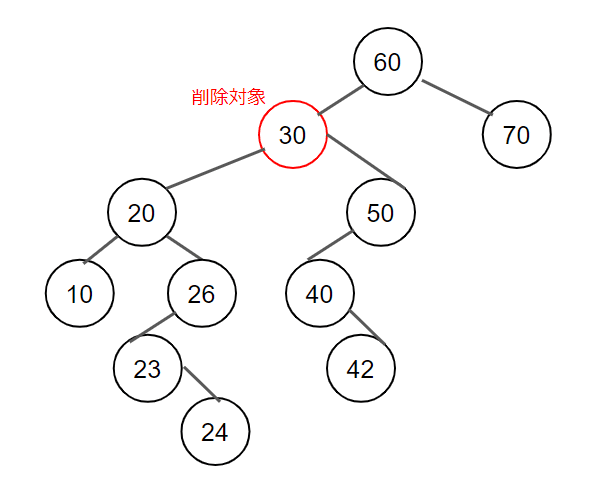
・削除対象ノードが子ノードを左右に両方持つ場合
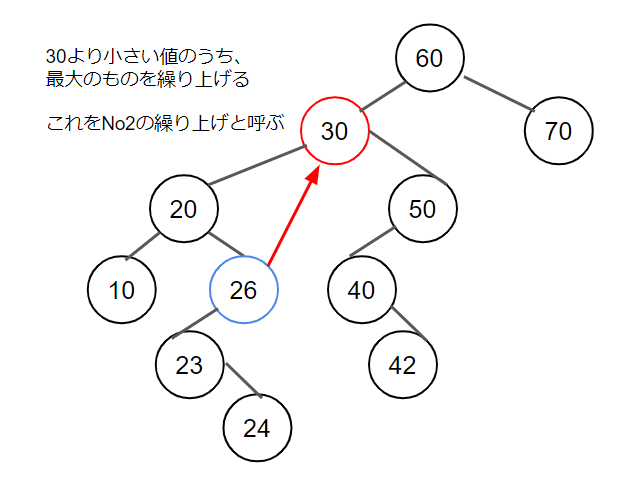
削除対象ノードの左子をルートとする部分木のうちから最大のkey値を持つノードを探索する。探索して発見したノード(No2ノード)を削除対象のノードと置き換えて、削除対象のノードを削除する。このとき(No2ノード)の左子をNo2ノードの空席にそのまますえる。

すなわちノードのkey値が意味を持つケースと、ノード間の参照が意味を持つケースを考えるということである。
No2の繰り上げに関しては参照は触らない。場合によってはkey値を上書きして修正するだけでも良い(ただしReference Equalsを使い倒している場合、影響が出る)。No2の世襲の場合は、key値は触らないが参照は組み替える。
また、二分探索木の重要な性質として
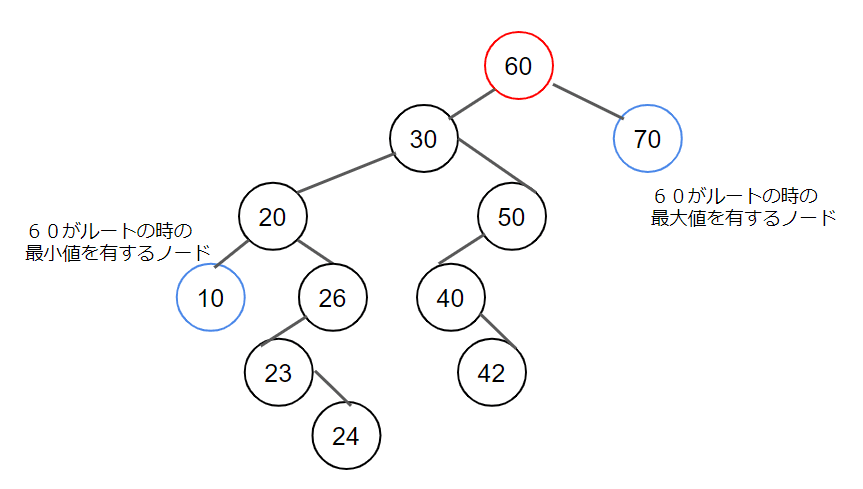
・ある木、ないし部分木のルートからずっと左子をたどった先は最小値を有するノードである。
・ある木、ないし部分木のルートからずっと右子をたどった先は最大値を有するノードである。
というのがある。

これを踏まえたうえである程度強引に作ると以下のようになる。
//processing
//Parent付削除
//ノードがParent持ち
boolean Delete(BinaryTreeNode start_node, BinaryTreeNode node)
{
BinaryTreeNode current = start_node;
while(true)
{
//引数の方が大きいならreturn -1
//引数の方が小さいならreturn +1
if(current.Value.compareTo(node.Value)<0)
{
current = current.Right;
if(current == null){return false;}//終了:削除対象ノードが発見できなかった
}
else if(current.Value.compareTo(node.Value)>0)
{
current = current.Left;
if(current == null){return false;}//終了:削除対象ノードが発見できなかった
}
else
{
//削除対象ノードが発見できた
if(current.Parent==null){return false;}//Root
if(!HasChild(current))
{
//削除対象が子を持たない
return DeleteReference(current);
}
else if(HasSideChild(current))
{
//削除対象が左か右の子系列のみ持つ
return PullOutNode(current);
}
else
{
//currentに左右の子系列がある
//現在のノードの左の子より始めて、最大値を有するノードを得る
BinaryTreeNode max = Max(current.Left);
if(max==current.Left)
{
return ReplaceReference(max,current);
}
//max移動準備
//maxは親の右子であるのが基本であるが
//max=部分木Rootの場合は親の左子である
//どちらにせよmaxは左子しか持たない
PullOutNode(max);
return ReplaceReference(max,current);
}//子が2つ以上の削除
}//探索により、削除対象の発見
}//while
}//Delete削除操作の場合分け①:削除対象ノードに子がない
親から子への参照を削除する

//対象ノードは親の左子か
boolean IsLeftChild(BinaryTreeNode current)
{
if(current==null){return false;}
if(current.Parent==null){return false;}//Rootならfalse
if(current.Parent.Left!=null&¤t.Parent.Left==current){return true;}
return false;
}
//対象ノードは親の右子か
boolean IsRightChild(BinaryTreeNode current)
{
if(current==null){return false;}
if(current.Parent==null){return false;}//Rootならfalse
if(current.Parent.Right!=null&¤t.Parent.Right==current){return true;}
return false;
}//親から子への参照を解除
boolean QuiteParent(BinaryTreeNode current)
{
return QuiteParent(current.Parent, current);
}
//親から子への参照を解除
boolean QuiteParent(BinaryTreeNode parent, BinaryTreeNode current)
{
if(parent==null){return false;}
if(current==null){return false;}
if(current.Parent==null){return false;}
//親から子への接続を解除
//インスタンス間の==演算子はreference equalになる
if(IsLeftChild(current))
{
parent.Left=null;
return true;
}
else if(IsRightChild(current))
{
parent.Right=null;
return true;
}
else{return false;}//謎の状態
}あるノードにかかる参照6本全部削除
boolean DeleteReference(BinaryTreeNode child)
{
return DeleteReference(child.Parent, child);
}
boolean DeleteReference(BinaryTreeNode parent, BinaryTreeNode current)
{
if(parent==null){return false;}
if(current==null){return false;}
if(current.Parent==null){return false;}
//■currentへの参照を削除
//parentからcurrentへの参照を削除
QuiteParent(parent, current);
//Left,Rightからcurrentへの参照を削除
if(current.Left!=null){QuiteParent(current, current.Left);}
if(current.Right!=null){QuiteParent(current, current.Right);}
//■currentからの参照を削除
//currentからparentへの参照を解除
current.Parent=null;
//currentのLeft,Rightへの参照を解除
current.Left = null;
current.Right = null;
return true;
}このように。たかだかこれだけの操作に偏執的なまでのガードとnullチェックがなされているのはバグと戦った痕跡であることは言うまでもない。
削除操作の場合分け②:削除対象ノードに左右のうち片方だけ子系列がある

状況的な場合分けは4パターン

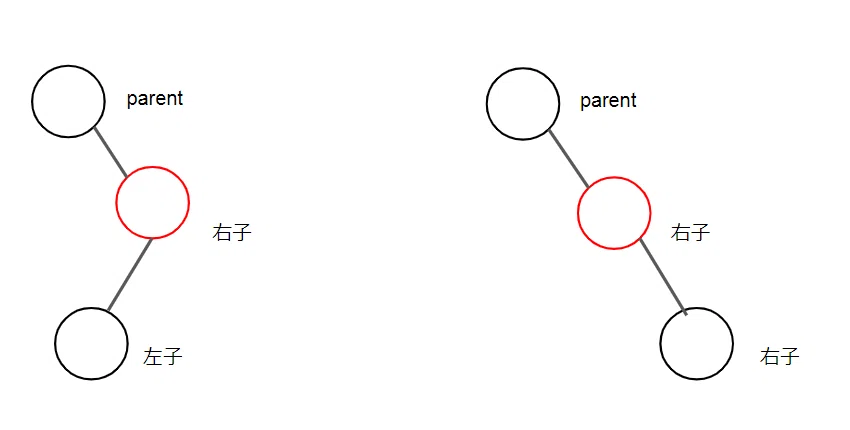
あるノードを木構造から抜出し、周辺参照を再接続。抜き出したノードから発する参照は全部斬る。
//ノードを周辺参照から引っこ抜く
//ノードの抜けた穴は修復される
boolean PullOutNode(BinaryTreeNode current)
{
//両方に子がある=>抜き出すことはできない
if(current.Left!=null&¤t.Right!=null){return false;}
//左にのみ子がある
if(current.Left!=null&¤t.Right==null)
{
//左系列の移植
return PortingLeftChild(current);
}
//右にのみ子がある
else if(current.Left==null&¤t.Right!=null)
{
//右系列の移植
return PortingRightChild(current);
}
//子がない
else if(current.Left==null&¤t.Right==null)
{
//親からの参照だけは抜いておく
return QuiteParent(current);
}
return false;
}
//currentのLeft系列をcurrentの位置に引き上げる
boolean PortingLeftChild(BinaryTreeNode current)
{
if(current==null){return false;}
if(current.Parent==null){return false;}
if(IsLeftChild(current))
{
if(current.Parent!=current.Left)
{
current.Parent.Left=current.Left;
}
if(current.Left!=current.Parent)
{
current.Left.Parent=current.Parent;
}
current.Parent=null;
current.Left=null;
current.Right=null;
return true;
}
else if(IsRightChild(current))
{
if(current.Parent!=current.Left)
{
current.Parent.Right=current.Left;
}
if(current.Left!=current.Parent)
{
current.Left.Parent=current.Parent;
}
current.Parent=null;
current.Left=null;
current.Right=null;
return true;
}
return false;
}
//currentのRight系列をcurrentの位置に引き上げる
boolean PortingRightChild(BinaryTreeNode current)
{
if(current==null){return false;}
if(current.Parent==null){return false;}
if(IsLeftChild(current))
{
//current親から子へ
if(current.Parent!=current.Right)
{
current.Parent.Left=current.Right;
}
//current子から親へ
if(current.Right!=current.Parent)
{
current.Right.Parent=current.Parent;
}
current.Parent=null;
current.Right=null;
current.Left=null;
return true;
}
else if(IsRightChild(current))
{
//current親から子へ
if(current.Parent!=current.Right)
{
current.Parent.Right=current.Right;
}
//current子から親へ
if(current.Right!=current.Parent)
{
current.Right.Parent=current.Parent;
}
current.Parent=null;
current.Right=null;
current.Left=null;
return true;
}
return false;
}削除操作の場合分け③:削除対象ノードに左右両方の子系列がある
この場合、すでに述べてある通り、左子系列の最大値か、あるいは右子系列の最小値を削除対象ノードの位置に移動するという操作が必要となる。要するに削除対象ノードに一番近いkey値のノードを用いれば、削除対象ノードを木構造から引っこ抜いた時も影響は最小限であろうということである。
あるノードから見て最大あるいは最小key値を持つノードを取得するには
//最大ノード(右端)を得る
//Root始動
BinaryTreeNode Max(BinaryTree tree)
{
return Max(tree.Root);
}
//指定のノード始動
BinaryTreeNode Max(BinaryTreeNode node)
{
if(node==null){return null;}
BinaryTreeNode current = node;
while(current.Right!=null)
{
current = current.Right;
}
return current;
}
BinaryTreeNode Min(BinaryTree tree)
{
return Min(tree.Root);
}
BinaryTreeNode Min(BinaryTreeNode node)
{
if(node==null){return null;}
BinaryTreeNode current = node;
while(current.Left!=null)
{
current = current.Left;
}
return current;
}ある部分木の最大値あるいは最小値を有するノードは必ず左右のどちらか、片側系列の子しか持たない。なので最大値あるいは最小値を有するノードを木構造から引っこ抜くには先につくったPullOutNodeを利用できる。
ただし、削除対象ノードの左子が、左子をルートとする部分木の最大key値を有する場合、すなわち右子を持たない場合はPullOutNodeだけで削除操作は完了する。
PullOutNodeだけで削除操作が完了するケース

PullOutNode(max周辺の参照の修復)だけでは削除操作が完了しないケース。PullOutNode後、maxノードを削除対象ノードにブチ込む必要がある。

引っこ抜いた最大値あるいは最小値を有するノードを削除対象ノードが位置する箇所にブチ込めば削除操作は完了である。既存のノードに別のノードをブチ込む操作には、周辺参照6本全ての考慮が必要となる。

boolean ReplaceReference(BinaryTreeNode source, BinaryTreeNode target)
{
if(source==null){return false;}
if(target==null){return false;}
if(target.Parent==null){return false;}
BinaryTreeNode tempParent = target.Parent;
BinaryTreeNode tempLeft = target.Left;
BinaryTreeNode tempRight = target.Right;
//sourceからの参照3本をtargetから奪い取る
if(tempParent!=source)
{
source.Parent = tempParent;
}
if(tempLeft!=source)
{
source.Left = tempLeft;
}
if(tempRight!=source)
{
source.Right = tempRight;
}
//targetの親から子への参照を奪い取る
if(IsLeftChild(target))
{
if(tempParent!=source){tempParent.Left=source;}
}
else if(IsRightChild(target))
{
if(tempParent!=source){tempParent.Right=source;}
}
else
{
return false;
}
//targetの子から親への参照を奪い取る
if(tempLeft!=null&&tempLeft!=source)
{
tempLeft.Parent=source;
}
if(tempRight!=null&&tempRight!=source)
{
tempRight.Parent=source;
}
target.Parent = null;
target.Left = null;
target.Right = null;
return true;
}なお、ここまでしてもまだバグってる可能性がありますのでご注意ください。
木構造の描画はいろいろあるけれども、とりあえずだけなら以下みたいな感じ。
import java.util.ArrayDeque;
import java.util.Queue;
void DrawQueue()
{
Queue<BinaryTreeNode> queue = new ArrayDeque<BinaryTreeNode>();
queue.add(Tree.Root);
while(0<queue.size())
{
BinaryTreeNode node = queue.poll();
PVector coord = GetCoordinate(Tree, node, TreeOrigin, TreeOffsetR);
if(coord!=null)
{
//current
circle(coord.x,coord.y,20);
//current.L,R
PVector coordL = GetCoordinate(Tree, node.Left, TreeOrigin, TreeOffsetR);
if(coordL!=null){line(coordL.x,coordL.y,coord.x,coord.y);}
PVector coordR = GetCoordinate(Tree, node.Right, TreeOrigin, TreeOffsetR);
if(coordR!=null){line(coordR.x,coordR.y,coord.x,coord.y);}
}
fill(255,0,0);
text(str((int)node.Value),coord.x,coord.y);
BinaryTreeNode parent = node.Parent;
if(parent!=null){text("P:"+str((int)parent.Value),coord.x,coord.y+10);}
BinaryTreeNode left = node.Left;
if(left!=null){text("L:"+str((int)left.Value),coord.x,coord.y+20);}
BinaryTreeNode right = node.Right;
if(right!=null){text("R:"+str((int)right.Value),coord.x,coord.y+30);}
noFill();
//queue.add
if(node.Left!=null)
{
queue.add(node.Left);
}
if(node.Right!=null)
{
queue.add(node.Right);
}
}//queue while
}
PVector GetCoordinate(BinaryTree tree, BinaryTreeNode node, PVector origin, PVector offset_r)
{
if(node==null){return null;}
PVector ret_coord = origin.copy();
PVector offset_l = new PVector(-offset_r.x, offset_r.y);
BinaryTreeNode root = tree.Root;
BinaryTreeNode current = root;
while(true)
{
if(current==null){return new PVector(0,0);}
if(node==null){return new PVector(0,0);}
//引数の方が大きいならreturn -1
//引数の方が小さいならreturn +1
if(current.Value.compareTo(node.Value)<0)
{
current = current.Right;
if(current == null){return null;}//終了:発見できなかった
ret_coord.add(offset_r);
int depth = GetDepth(tree, current);
PVector offsetH = CalcuOffsetH(depth, offset_r);
ret_coord.add(offsetH);
}
else if(current.Value.compareTo(node.Value)>0)
{
current = current.Left;
if(current == null){return null;}//終了:発見できなかった
ret_coord.add(offset_l);
//補正
int depth = GetDepth(tree, current);
PVector offsetH = CalcuOffsetH(depth, offset_l);
ret_coord.add(offsetH);
}
else//等しい:発見できた
{
return ret_coord;
//終了
}
}//while
}
PVector CalcuOffsetH(int depth, PVector offset)
{
float range = (offset.x*2)*(depth+1);
int node_count = (int)Math.pow(2,depth);
PVector offsetH = new PVector(range/(float)node_count,0);
return offsetH;
}Parentを持たない場合、あるいは木構造を抽象化する場合はこちら
親あり、削除操作あり、2色木