現場で使える機械学習活用 ~その①機械学習プロジェクトの流れと留意すべきこと~

はじめに
このブログは、「現場で使える機械学習活用」をテーマにした4部作のうち1作目です。これらの4部作では「いかにして機械学習を使って現実世界の問題を解決するか」を軸に、陥りやすいポイントやコツを解説していきます。
第1回目は、プロジェクトの流れとプロジェクト成功のため留意すべきことを解説します。
機械学習プロジェクトの流れと留意すべきこと ←イマココ
機械学習プロジェクトの流れ
機械学習を実務に適用するプロジェクトは、下記に示す5つの段階に分けることができます。
課題から機械学習で解決できそうな部分を見つけ、実現性を探る
機械学習で解けるように問題を設定する
必要なデータを集め、前処理をする
機械学習で学習・モデルの改善を行う
機械学習を実務に組み込む
1~4 は「課題が機械学習で解決できるかを検証する」という部分で、本記事を含めた 4 部作で詳細に解説します。5 番目は「実現できそうな機械学習モデルを実務に組み込む」という段階で、本来この 5 番目もさまざまな段階にいくつも分けることができますが、ここはソフトウェア工学の範疇であり、本ブログでは立ち入りません。本記事ではプロジェクトの大まかな流れを示すにとどめ、次の記事で仮想プロジェクトを使って詳細に解説します。
プロジェクトの不確定要素とPoC
従来のソフトウェア開発と比較すると、機械学習を使ったプロジェクトでは「果たして本当に機械学習で課題を解決できるか」という不確定要素が存在します。他のソフトウェア開発がうまくいっても、肝心の機械学習モデルが目標精度に到達しないと、全てが水の泡になってしまいます。
そのため、機械学習プロジェクトでは "Proof of Concept: PoC" と呼ばれる短い検証プロジェクトを繰り返して不確定要素を先に検証するプロジェクト形態をとることが多いです。
また、Google Brain の共同設立者でありスタンフォード大の教授でもあるAndrew Ng 先生は「従来のソフトウェア開発と比較すると、機械学習システムを構築する作業のほとんどは開発よりもむしろデバッグである」と指摘しています。これは、機械学習モデルがもつ不確実性から、素早くプロトタイプを作って問題を特定し、改善を進めることが有効だということであり、最初に小さなプロジェクトである PoC を進めることの有効性を示しています。
この精神的枠組みを内面化することで、私はより効率的な機械学習エンジニアになった: 機械学習システムを構築する作業のほとんどは、開発よりもむしろデバッグだ。(中略) 従来のソフトウェア・システムを構築する場合、製品仕様を書き、その仕様に沿ってコードを書き、最後にコードのデバッグと不具合の修正に時間をかけるのが一般的だった。しかし、機械学習システムを構築する場合は、最初のプロトタイプを素早く構築し、それを使って問題を特定し修正する方が良い場合が多い。

PoC プロジェクトとは?
"Proof of Concept: PoC" とは、その名の通り、コンセプトとなる技術や要素が実現できるかを検証する小規模プロジェクトです。通常数週間から数ヶ月程度の短いプロジェクトになることが多く、連続して複数の PoC を行うこともあります。機械学習プロジェクトの場合、高リスク要素である「課題が本当に機械学習で解決できるかを検証すること」を主目的とします。先ほど示した5つの段階のうち、最初の 4 つが主な検討対象です(下図)。

そのため、機械学習技術以外の要素はかなり簡略化します。例えば、本番ではデータのパイプラインを含めたシステムをキチンと作るところを手持ちのデータと.py ファイルで検証する、などです。この簡略化により、機械学習関連の不確定要素を素早く検証することができます(下図)。

なぜPoCプロジェクトをするのか?
PoCを実施する大きな理由は、失敗した時の損失を最小化することが大きな理由です。上で述べたように、機械学習プロジェクトの最大級の不確定要素は「課題が本当に機械学習で解決できるか」です。
仮に機械学習以外のソフトウェア開発を完了した上で機械学習で課題が解決できないことがわかると、先行開発したソフトウェアは使えないので、そこへの投資はそのまま損失になります。しかし、不確定要素である機械学習部分を先に検証することにより、仮に機械学習で課題が解決できないことが分かったとしても損失は最小限で済みます(下図)。

このような小さく始めるスモールスタートは、決して筆者独自の考えではありません。Andrew Ng 先生も小さなプロジェクトから始めることを推奨しています(例えばこの記事など)。
実は、Andrew Ng 先生も述べているように、小さなプロジェクトを実用化のために大規模化するには決して低くないハードルがあります。しかし、まずは小規模でもプロジェクトを成功させないと実用化はできませんので、プロジェクト規模にこだわらず成功させることを目指していきましょう。
プロジェクト成功のため留意すべきこと
プロジェクトの概観を何となく把握した上で、次にプロジェクト成功のために大切なことを見ていきます。筆者の考えでは、プロジェクトで成功するための考え方は以下の5つに集約されます。それぞれ本記事の後半で詳しく説明します。
大規模な検証よりも小さな検証を繰り返す
「機械学習を使うこと」ではなく「課題を解決すること」を考える
ドメイン知識を駆使して解くべき問題を簡単にする
よく知られた問題に帰着させる
完璧な精度に到達するのは無理という前提にたって運用を考える
1. 大規模な検証よりも小さな検証を繰り返す
PoC プロジェクトはスモールスタートですが、その中でも実施すべきことを見極め、効果的で小規模な検証を繰り返すことが有利な場合が多いです。
理由は「最終到達精度が早期に見えやすい」「関係者から多くのフィードバックを得やすい」「デバッグがしやすい」の 3 点です。例として、小さな検証を6回繰り返した例(青)と大規模な検証を 1 度だけ行う例(赤)を下に示します。

上の例では、講じた施策数は一緒なので最終到達精度は同じです。また、小刻み検証の青プロジェクトでは、当然ながら各施策策は優先度が高い、つまり効果が高いと思われる施策から実施しています。もちろん見込み違いで効果がない施策も含まれています。
小刻み検証の青プロジェクトでは、効果が高いと重される順に施策を実施しているので、最優先施策のいくつかを実施した段階で、最終的にどのあたりまで精度が上がるのかが早期( PoC1 と PoC2 の間くらい)で見えています。一方、大規模検証の赤プロジェクトでは、実装が全て終わるまで最終到達精度が見えません。
早期に最終到達精度が見えるというのは戦略的に非常に重要です。最終(見込み)到達精度が目標精度にまったく及ばないようであれば、PoC1 が終わった段階でプロジェクトを中止すれば損害は最小限で済みますし、目標精度に到達しそうであれば、このプロジェクトのように PoC2 を追加投資して始めることもできます。
小刻み検証の青プロジェクトでは、各施策の実施後に振り返りをする時間を設けています。振り返りの時間があるぶんだけ、大規模検証の赤プロジェクトよりもプロジェクト期間は長くなりますが、施策の振り返り時間を設けられることは大きな利点です。
施策の効果の有無を検証することで、扱っているデータの知見が深まりますし、関係者からフィードバックを得ることができます。この振り返りにより効果的な施策を新たに考案することが出来るかもしれません。また、少し政治的要素が入りますが小さくとも結果が出ていることを見せられるので、「プロジェクトが進んでいる」という印象を周囲に与えられ、余計な詮索・介入を受けにくくなることも無視できない利点です。
一方、大規模な赤プロジェクトの場合、全て実装するまで全く結果が出ないので、小刻み検証の青プロジェクトで得られたようなデータに関する知見やフィードバックが得られません。また、見える結果が出るのに時間がかかるため、周囲との関係も悪化しがちです。
最後にデバッグに関してです。大規模な赤プロジェクトの場合、一気に色々なコードを動かすことになるため、精度が出なかった場合に「全施策が効果なかった」「バグがあって精度が出ない」どちらなのか検証しにくいです。小刻み検証の青プロジェクトの場合は、小刻みに精度(動的テスト)の結果が出ているので、バグがあれば比較的気付きやすいでしょう。

2.「機械学習を使うこと」ではなく「課題を解決すること」を考える
機械学習を学んだ人なら、最新の論文の技術を組み合わせて SOTA モデルで一挙に課題を解決してやろう、と思ったことがあるかもしれません。しかし、我々エンジニアの仕事は、「カッコよく最新技術を使う」ことではなく「課題を解決すること」であることに立ち返らねばなりません。そのためには、機械学習を使うことすら捨てて構いません。
機械学習関連の事例ではありませんが、「課題を解決すること」を最優先した例を以下に紹介します。
動画用カメラと配信用パソコンを使っただけのお手製デジタルトランスフォーメーション(DX)が首都圏で広がっている。役所の窓口で順番待ちしている人数や施設の混雑状況を表示したモニター画面を撮影してライブ配信している。手間も費用もほとんどかけずに利便性を向上させる実のあるDXは利用者からも好評だ。(一部抜粋)
上の記事の事例では、「役所の顧客が自分の順番をウェブ上で見られるようにする」という課題に取り組んでいます。正攻法であれば、ソフトウェア開発をして役所のウェブサイトに待ち人数を表示する…という取り組みになるというところを、「役所のモニターをカメラで映して YouTube Live で配信する」という単純かつ低コストな方法で解決しています。初期費用は 0 円、ランニングコストは月 3000 円程度だそうです。
「トラフィックが無駄」とか「これは DX ではない」など色々言われて
いるのですが、私はかなり好きです。課題をキチンと解決している上に開発費・運用費ともにかなり低額に抑えることに成功しています。ソフトウェア開発という正攻法を使った場合、開発費・運用費ともに比べ物にならないくらい高額になっていたでしょう。
上記の例は少々極端かもしれませんが、機械学習プロジェクトに関しても同じことが言えます。機械学習の問題に落とし込む前に「機械学習じゃないと本当に課題を解決できないのか」を問いかけるべきです。非機械学習手法の代表として、ルールベースの手法(人間が決めた単純なルールで動くアルゴリズム、e.g. 気温が 30℃ 以上ならエアコンの設定温度を26℃にする、そうでないならば 28℃ に設定する)と機械学習を比較してみます(下表)。

ここでは簡単に述べるにとどめますが、機械学習の方は人間がルール化できない複雑な事象へ適用することができる一方、計算資源が多く必要であったり、説明性や偏見の問題があります。機械学習は非常に強力ですが、何でも解決してしまう銀の弾丸ではありません。ルールベース手法との比較の詳細は、拙著「現場で活用するための機械学習エンジニアリング」に記載していますので、興味ある方はご覧ください。
ここで述べた「機械学習を使わない解決策をまず考える」という哲学は数年前は盛んに言われていましたが、ChatGPT をはじめとする高性能な基盤モデル (foundation model) の登場により機械学習で解決できる裾野が広がった今は、少し影が薄くなったかもしれません。しかし、この哲学を実施する過程ででてくる「機械学習が必須な部分とルールで解決できる部分に課題を分割する」という副産物は、下で解説する「問題を簡単にする」ことに繋がります。これは依然として課題解決に非常に有効であり、筆者としてはこの哲学は依然として重要だと考えています。
3.ドメイン知識などを駆使して解くべき問題を簡単にする
機械学習は非常に強力ですが、問題を分解して簡単化して機械学習に解かせやすい形にすることは非常に重要です。人間と同じように、機械学習も解くべき問題が簡単であればそれだけ精度が高くなります。
問題を簡単にするにはどうすれば良いでしょうか?それには扱っているデータに関する知識、すなわちドメイン知識を活用することが近道です。ドメイン知識を使って問題を簡単にするイメージを下に示します。
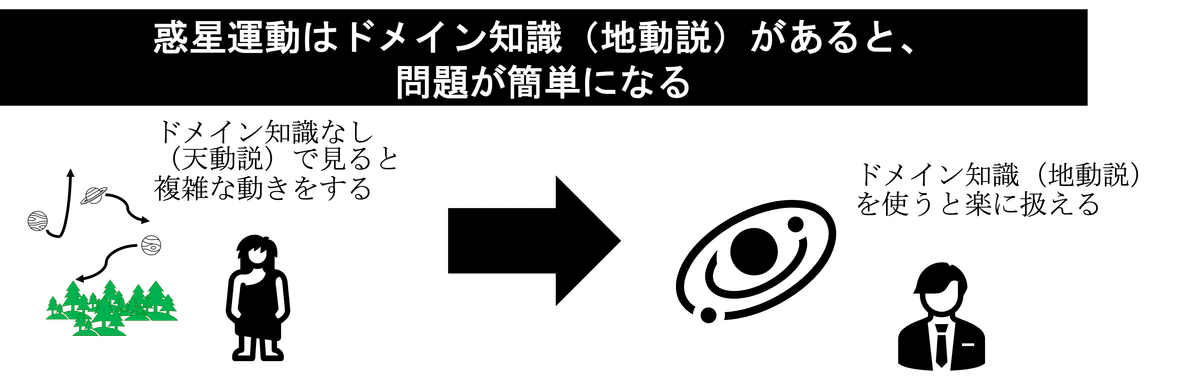
上の図は、惑星の運動をドメイン知識(地動説)の有無で解釈したときの違いを示しています。予備知識なしに惑星の動きだけに着目していると、「惑」星はその名の通り人を惑わす複雑怪奇な動き方をします。しかし、我々現代人は地動説を知っているので、それに基づいて惑星の動きを見ることで、(かなり大雑把な近似をすると)太陽と各惑星の二体問題に帰着できます。このように、ドメイン知識を使うことで問題を単純化し、解きやすくすることができます。
機械学習の問題に関しても同じことが言えます。例えば、画像分類の問題でも、ドメイン知識として画像の撮影場所が一部のカテゴリに決定的な影響を与えることを知っていたとします。この場合は分類モデル適用前に、撮影場所の情報を使ってルールベースのフィルタリングをかければ、分類すべきカテゴリ数を減らして問題を簡単にすることができます。
4.よく知られた問題に帰着させる
ドメイン知識の活用以外でも、強力な事前学習モデルが活用できる問題に帰着することで、問題を解きやすくすることができます。すなわち、問題を読み替えて強力な事前学習モデルが使える形に問題を帰着させます。
もう少し具体的に言えば、解いている問題を分解して「画像分類」「物体検知」などよく知られた問題設定に帰着できれば、その分野の事前学習モデルを利用できます。最近は強力な事前学習モデルが比較的簡単に活用できるので、それを使えば業界最高レベルの精度で問題を解くことができます。
例として、「防犯カメラの映像から異常を検知する」という問題を考えます。ひとくちに「異常」といってもさまざまですので、それを具体化しながらよく知られた問題に落とし込みます(下図)。

上のように、よく知られた問題に帰着できれば、ウェブ上で活用できる強力な事前学習モデルを利用できます。これを利用できれば業界最高峰レベルの精度で問題を解くことが可能です。
5. 完璧な精度に到達するのは無理という前提にたって運用を考える
機械学習を使ったプロジェクトでは、目標精度を決めなければなりません。もちろん精度は高ければ高いほど良いので、プロジェクト担当者の方々は「目標精度は 95% 以上で…」「最低 90% はないと…」と異口同音に言います。果たして、この目標精度は現実的なのでしょうか?例として、コンピュータビジョン分野の代表的データセット ImageNet(画像の 1000 値分類タスク)の最高到達精度の時系列推移を見てみましょう(下図)。

上図で示したように、ImageNet という超有名タスクで数多くのトップ研究者が競いながら 10 年以上かけて到達した精度が 90.2% です。この事実から、「精度 90% 以上」という目標がいかに重いものであるか分かると思います。他のタスクの精度を下表に示しますが、精度 90% に達しているタスクは決して多くはありません。しかも数万・数十万規模のデータが必要なため簡単に実現できるものではなく、たった数ヶ月の低予算 PoC で到達可能と簡単に結論づけられるものではありません。

一方で、高い精度のモデルの方が運用しやすいのは事実です。では、低い精度しか出ないタスクでは機械学習の適用を諦めるべきでしょうか?
決してそうではありません。推論ミスをした時のリスクを天秤にかけたり、運用方法を工夫することで、精度が高くない機械学習モデルでも十分に利活用が可能です。
まず、推論をミスしたときのリスクを考えてみます。タスク別に必要な精度と推論をミスしたときのリスクを下表に示します。

まず、医療機器と自動運転に適用する機械学習モデルですが、非常に高い精度が要求されます。なぜならば推論のミスが人の死に直結するからです。人命に関わらなくとも工業製品の検品では推論ミスが発生すれば、リコールなど大きな損害にも繋がりかねません。
一方で、広告の表示に使う機械学習モデルでは、推論ミスは機会損失につながるものの、人は死なず賠償金も発生しないので比較的低リスクと言えるでしょう。この場合は、精度向上による収益増とコストを天秤にかけて、完璧な精度でなくても運用することが可能です。
医療や工業製品など高い精度が必要な分野で、低い精度のモデルを運用するにはどうすれば良いでしょうか。その解決策の例として、例えば判定の閾値を安全側に寄せてスクリーニングを行う、といった方針が考えられます(下図)。

上図では、異常検知の閾値を調整して、異常品見逃し防止を重視した予測をしています。通常、予測の閾値は中間値である0.5を使うこと多いですが、閾値を下げることで「異常品」と判定する率を増やし最終判断を人間に委ねる戦略です。これにより、「良品」を「異常品」として判定する確率は増えますが、その分「異常品」を「良品」として処理するリスクも減ります。人間による最終判断が必要ですが、機械学習による施策を全く行わない時よりも大幅に工数を減らせます。
終わりに
第1回目では、プロジェクトの流れとプロジェクト成功のため留意すべきことについて書きました。機械学習プロジェクトはPoCという形態をとることが多いこと、小さな検証を繰り返すプロジェクト形態が有利であること、カッコいい解決策ではなく問題の解決を主軸に置くこと、問題を簡単にするためドメイン知識を活用すること、完璧な精度ではないモデルを前提に運用方策を決めること、を説明しました。
次回の記事では、仮想プロジェクトでこれらの考え方をどのように使うかを見ていこうと思います。
このブログのように、「いかにして機械学習を使って現実世界の問題を解決するか」を解説した本を書いています。ここで書いたことより詳しく書いていますので、気になった方はぜひ手に取ってみてください。
記事を書くために、多くの調査や論文の読み込みを行っております。情報発信を継続していくためにも、サポートをいただけると非常に嬉しいです。