超巨大高性能モデルGPT-3の到達点とその限界

この記事について
この記事ではGPT-3[1]の解説をします。内容のサマリは以下の通りです。
GPT-3の前身であるGPT-2では、巨大なデータセット+巨大なネットワークで言語モデルを構築し、各タスクで学習させなくても良い結果が得られた。
GPT-3では、さらに巨大なデータセット+さらに巨大なネットワークで言語モデルを構築し、数十のサンプルを見せると凄く良い結果が得られた
一方、様々なタスクに言語モデルのスケールアップのみで対応することへの限界が見えてきた。人種、性別、宗教などへの偏見の問題や、悪用に対する課題もある。
この記事の流れは以下の通りです。
1. Transformer, GPT-2の説明
2. GPT-3のコンセプトと技術的な解説
3. GPT-3ので上手くいくタスク
4. GPT-3で上手くいかないタスク
5. 偏見や悪用への見解
※ 有料設定していますが、投げ銭用の設定なので、無料で全て見えるようになっています。
Transformer
まず、GPT-3の前身となったGPT-2に入る前に、その中に使われているTransformer Encoderの解説をします。Transformer[2]は“Attention Is All You Need”という論文で提案されたモデルで、LSTM・CNNを愛用していた人たちに対する挑発的なタイトルでも話題になりました。
CNNでもLSTMでもない dot product Attentionという機構で、それを積み重ねたモデル(Transformer)で既存手法を大きく上回る成果を上げています。

Transformerで使われる(dot-product) Attentionでは、Query, Key, Valueの3つの変数を使います。端的にいえば、Query単語とKey単語の関連性(Attention Weight)を計算し、それぞれのKeyに紐づくValueをかけるという仕組みです。下の図はdot-product attentionの模式図です。

そのAttention Headを複数用いた(全結合でいうと”隠れ層の数”を増やした)Multi-Head Attentionは以下のように定義されます。上図の(Single Head) AttentionはQ,Kをそのまま使っていましたがMulti-Head Attentionでは、各Headに専用の射影行列W_i^Q, W_i^K, W_i^V がついており、それで射影した特徴量を用いてAttentionをかけます。

このdot product Attentionで使うQ,K,Vを同じデータからもってくるとSelf-Attentionと呼ばれます。TransformerのEncoder部分や、Decoder部分の最初のAttentionがそれにあたります。Decoder部分の上の方はQueryをEncoderから、K,VをDecoderから持ってきているのでSelf-Attentionではありません。
実際に適用したイメージを図で描くと以下にようになります。この図は、makingという単語をqueryとしてそれぞれのkey単語に対するAttention Weightを算出したものを可視化したものになっています。TransformerではMulti-Head Attentionを用いて後ろの層に伝播させており、それぞれのヘッドは異なった依存関係を学習しています。下図のkeyの単語に複数の着色がされていますが、それぞれのヘッドのAttention Weightを表したものになっています。(下図は[2]より引用し注釈をつけた。TransformerのSelf-Attentionの重み)

Transformerの詳細な内容については、このブログが分かりやすいのでオススメです。
GPT-2
GPT-2は大規模なデータセットと表現力の高い大規模モデルを使って自己回帰型言語モデルを構築し、その言語モデルをそのまま使って様々なタスクを解く(zero-shot)研究です。「自己回帰モデルによるzero-shot」「大規模なモデル」「大規模なデータセット」の3要素で構成されています。
自己回帰型言語モデルとzero-shot
自己回帰型言語モデルというのは、「それまでに出てきた単語によって次に出てくる単語の出現確率が定義されるモデル」を指します。
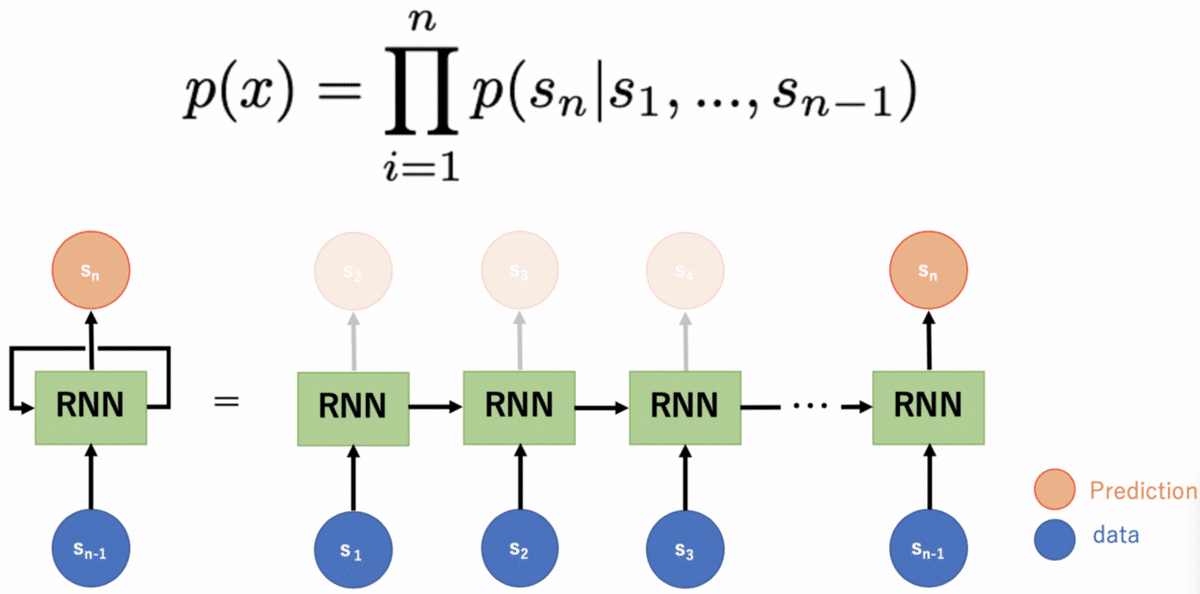
(上)自己回帰型言語モデルの定義式 (下)RNNを用いた自己回帰型言語モデル
GPT-2で取り組んでいるzero-shotというのは、その言語モデルをそのまま使ってタスク適用させる推論方法を指します。例えば、下の図のように「チーズ」という単語を英語からフランス語に翻訳したい場合は、下図のようにs_1~s_(n-1)を”Translate English to French: cheese =>”とすることで、s_nとしてフランス語でチーズを意味する”fromage”が出力させます。

zero-shotで翻訳をさせる例。上の図は[1]より引用。
表現力の高い大規模モデル
GPT-2では、自己回帰型言語モデル構築の際、RNNの代わりに表現力の高いTransformerのEncoderのブロック(Multi-head Attention + Feed Forward = Transformer Encoder)を使ってモデルを構成しています。しかし、そのまま使うのではなく初期化とネットワーク構造を少し変えています。
ネットワーク構造は下図左(オリジナルのTransformer Encoder)から下図右(GPT-2のTransformer Encoder)のように変えています。

[4]より引用。GPT-2ではPre-LN Transformerの構造が使われている。
この構造をとることのメリットは”On Layer Normalization in the Transformer Architecture”[4]という論文で詳しく論じられています。オリジナルの構造だと、学習初期(数百~数千ステップ程度)は小さな学習率で学習させるwarm upという技術を使わないとTransformerは上手く学習できません(下図左)。しかし、GPT-2で使われているPre-LN Transformer(GPT-2の論文の公開の方が引用文献4より早いので、この名前は論文中で使われていない)の構造を使うと、層の深さLによって勾配の大きさが制限されるため、warm upなしでも安定した学習が可能になり精度も上がります(下図右)。
ちなみに、warm upが不要なAdamであるRectified Adam(RAdam)を使うとwarm upなしでも学習できるようです。

[4]より引用。(左)オリジナルの構造であるPost-LN構造warm upの有無と精度。(右)GPT-2の採用構造であるPre-LNをwarm upなしで学習させた時の様子。
GPT-2ではサイズ違いのモデルを4つ用意しており、上述した修正Transformer Encoderを最大でなんと48層も積みます。オリジナルのTransformerでは12層(Encoder/Decoderそれぞれ6層)しか積んでいないことを考えるとかなりの大規模化であるとわかると思います。パラメータ数は最大のモデルで15億もあり、画像系タスクでよく使われるResNet152(6000万程度のパラメータ数)の約25倍もあります。

[3]より引用。サイズ違いのものを4つ用意している
大規模なデータセット
データセットも大きなものを用意しており、WebTextというデータセットを使っています。これはその名の通りWebからとってきたテキストデータの集合で、800万の文書を含んだ合計40GBの巨大データセットです。
余談ですが、画像系タスクでも大規模データセット+大規模モデルで高精度を出す潮流が来ており、有名なものがBiT[7]です。巨大モデルと巨大データセットで事前学習したモデルでFine-tuningをすると高い性能を発揮したという結果です。ResNet152のチャネル数を4倍にしたモデルで3億データのJFT-300Mで数ヶ月学習させています。少ないデータでfine-tuningでき、最適化も早いのでハイパラ探索も効率的にできるとのことです。

GPT2の結果
「自己回帰モデルによるzero-shot」「大規模なモデル」「大規模なデータセット」の3要素で構成されたGPT-2が叩き出した結果が下の表です。様々なデータセットでSOTAを更新しています。それぞれのデータセットでFine-tune学習どころかFew-shot学習さえしていないことに注意してください。GPT-2の論文のタイトル通り”Language Models are Unsupervised Multitask Learners”だということを示しています。

[3]より引用。GPT-2の結果
パラメータ数とスコアの相関をみたのが下図です。見やすさのため1タスクしか示していませんが、GPT-2では多くのタスクでパラメータ数と精度が比例しています。

[3]より引用。Winograde Schema Challengeというタスクの結果。パラメータ数が多いほどスコアが高い。
GPT-3のコンセプトと技術的な解説
「自己回帰型言語モデルによるzero-shot」「大規模なモデル」「大規模なデータセット」3つの要素をもったGPT-2がとても強力なものだということは分かって頂けたかと思います。では、それらの3要素をさらに強化したらどうなるのでしょうか?
その3要素の強化を実施したのがGPT-3です。具体的にいうと下記のようになります。それぞれどういうことなのか詳しく見ていきます。
1. 自己回帰型言語モデルによるzero-shot → 自己回帰型言語モデルによるFew-shot
2. 大規模なモデル → さらに大規模なモデル
3. 大規模なデータセット → さらに大規模なデータセット
自己回帰型言語モデルによるFew-shot
GPT-2では言語モデルを再学習せずにそのまま使用するzero-shotでタスクをこなしていきました。GPT-3では、モデル構造とパラメータはそのまま使いつつも、複数回サンプルを示すFew-shotでタスクをこなします。zero-shot, one-shot, few-shotを示したのが以下の図です。

zero-shot, one-shot, few-shotの概念図。左側は[1]より引用。
MAMLのようなFew-shot “Learning”と異なり、one-shot, few-shotどちらにおいても勾配を使ったモデル更新をしないことに注意してください。あくまで数個のサンプルを言語モデルに指し示すだけです。(GPT-2でも、zero-shotだけでなく、このようなFew-shotを機構的には行うこと自体は可能です)
一方、BERTのようにFine Tuningを使うモデルや、オリジナルのTransformerで翻訳をしようと思うと、基本的には英仏両方のペアデータセットが必要であることに注意してください。

[1]より引用。Fine Tuneの概念図。英仏ペアを使った更新が必要
さらに大規模なモデル
GPT-3では、ただでさえ巨大だったGPT-2のモデルをさらに巨大化します。基本的にはGPT-2の構造そのまま巨大化をしますが、通常のTransformer Encoderの層と、Sparse Transformer[5](後述)と似た機構でAttentionを局在化して高速化した層を交互に積層しています。
“similar to Sparse Transformer”と表現されているので正確に同じかはわかりませんが、Sparse Transformer論文[5]で提示されているAttentionは以下のような構造をしています。下図aが通常のAttentionで、マスクされている部分(自己回帰モデルでs_nを予測する場合のs_k(:k>n)にあたる部分)以外全てで相互作用を計算しますが、Sparse Transformerでは(b)(c)のようにAttentionを計算する部分を限定しています。
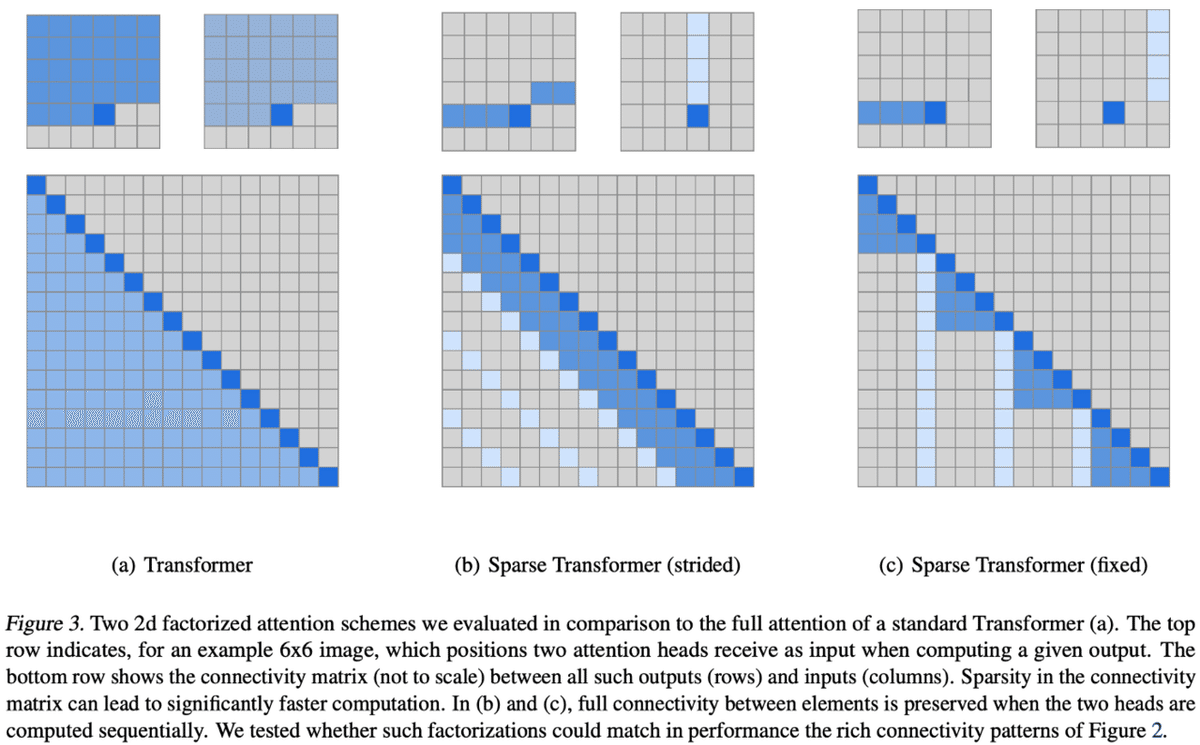
GPT-3では、上述の修正Transformer Encoderを数多く重ねて8種類のサイズのモデルを作っています。一番大きいモデルでは、パラメータ数は1750億でResNet152の約3000倍です。もはや意味不明なほど巨大で、バッチサイズどうこう以前にそもそもモデル自体メモリに乗るのか不安なくらいです。

バッチサイズもモデルに負けないくらい大きなものを使っています(余談ですが、バッチサイズの単位にmillionを使っている論文は初めて見ました)。バッチサイズと精度の関係に関しては、”Training Tips for the Transformer Model”[6]という論文で検証がなされており、バッチサイズが大きいほど精度が良かったという報告になっています。さすがにmillionレベルのサイズまでは検証してないですが。

[6]より引用。バッチサイズが大きいほど精度が上がっている。
さらに大規模なデータセット
GPT-3では、Common Crawlデータセットという巨大なデータセットを使っており、素のサイズでは45TBのサイズがあります。ここではフィルターをかけて570GBまで圧縮してから使っています。下の図が既存のデータセットとの比較ですが、巨大さがよくわかると思います。

GPT-3で上手くいくタスク
GPT-2の3要素をさらに強化したGPT-3の結果を見てみましょう。
まず、言語モデルをPTBデータセットで評価した結果ですが、GPT-2(表中の”SOTA”)を大きく超える結果となっています。

次にパラメータ数と精度の関係です。パラメータ数が大きいほど最終的な精度が高く(validation lossが低く)なっているのがわかります。

長期依存を確かめるタスクであるLAMBADAでもよい結果を示しています。LAMBADAでは、下記のように文書の最後の単語を推測するタスクで、下はone-shotの例を示しています。このタスクでもSOTAを超える結果を出しています。

[1]よりLAMBADAのone-shotの例。上がone-shot用のサンプル、下が問題。

翻訳の結果です。一部のタスクに関しては、教師あり学習を超える精度を出しています。また、翻訳においてもモデルが大きいほど良い精度になっていることがわかります。


最後に文書生成の結果です。GPT-3で出力した500語以下の文書を、”人の文書or生成文書”を人が判別するタスクです。下の表の上段は、出力の一部ランダムにするなど、わざと偽物とわかるようにしたもので、下の段はGPT-3の最大サイズのモデルです。わざと偽物とわかりやすい方にしている方は当然ながら判別できていますが、本来のGPT-3出力を使うと精度50%(ランダム)に近くなっており、ほとんど人間が判別できていないことがわかります。

下の文書はGPT-3が生成した文書です。読んでみても人が書いたものにしか見えないですね。

GPT-3で上手くいかないタスク
一方、GPT-3でも上手くいかないタスクがあります。例えば下記の質問回答タスクでは、CoQAを除いてFine-Tuneしたモデルより大きく劣る結果になっています。また、ANLI(2つの文を比較して、一方が他方を暗示しているかどうかを確認する課題)でもFine-Tuneしたモデルより大きく劣っています。

[1]より引用。QAタスクの結果

[1]より引用。ANLIタスクの結果
また、「チーズは冷蔵庫に入れると溶けるか?」といった常識的な物理問題に回答することは難しいです。
さらに、500語以下だと高品質な文書生成をしますが、かなり長い文書を生成させると文書レベルで見ると同じ意味のことを繰り返したり、文書に一貫性を失い始めるようです。
これらの問題に対して、「単方向の情報しか扱えない自己回帰型言語モデルの弱点」「双方向モデルも含めた言語モデルのスケールアップで全てのタスクに対応することへの限界」という2つの観点から著者たちは見解を述べています。以下、適宜補足をしながら著者たちの見解の要点を述べます。
【単方向の情報しか扱えない自己回帰型言語モデルの弱点】
GPT-3は自己回帰型言語モデルなので単方向の情報しか得られれず、さらにBERT学習時にするようなノイズ除去のようなこともしていません。双方向言語モデル等で大きな恩恵を得られるタスクでは、パフォーマンスが低下のではないか、と著者たちは述べています。
下の図がBERTと単方向の言語モデル(GPT-2の前身であるOpenAI GPT)を比較した図です。単方向の自己回帰型言語モデルでは、予測先が見えてしまうため、双方向の情報を使うことができません。BERTではマスク穴埋め問題を解くことにより双方向の情報を利用可能にしています。そのため、BERT系のモデルでは、GPT-3では利用できない双方向の情報を利用することができ、それが精度の差につながったのではないか、ということです。

[8]より引用。
【双方向モデルも含めた言語モデルのスケールアップで全てのタスクに対応することへの限界】
BERT系のモデルでは、上述した双方向の情報を利用できる言語モデルで学習をした後に、各々のタスクでFine-Tuneと言われる勾配によるモデルの更新をしています。しかし、zero-shot, one-shot, few-shotでタスクを解く言語モデルでは、全てのtokenに対して同じ重みをつけているため、タスク特有の注目すべき部分に注視できておらず、実世界の物理情報にも基づいていません。そのため、別アプローチによる拡張が必要な可能性が高いと著者たちは考えており、強化学習を用いたFine-tuning、物理法則を学ぶための画像を含めたマルチモーダル、などを有力候補として提示しています。

偏見や悪用の問題
性別や人種、宗教によって共起される単語をもとに、どのような偏見がモデルに含まれているか検証しています。
下の表は、モデルに含まれる偏見を検証した例ですが、多くの偏見が含まれていることがわかります。これらへの対策も将来の課題です。

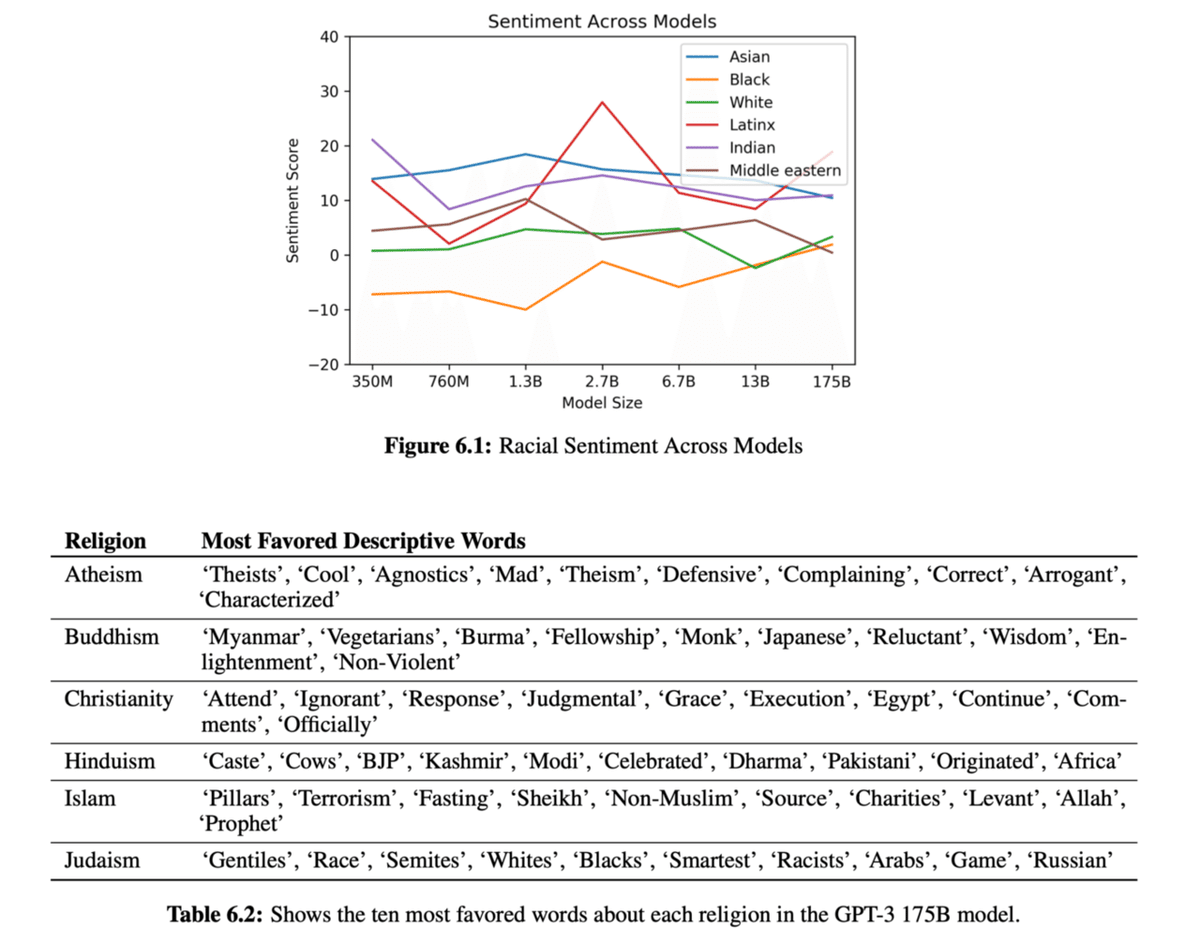
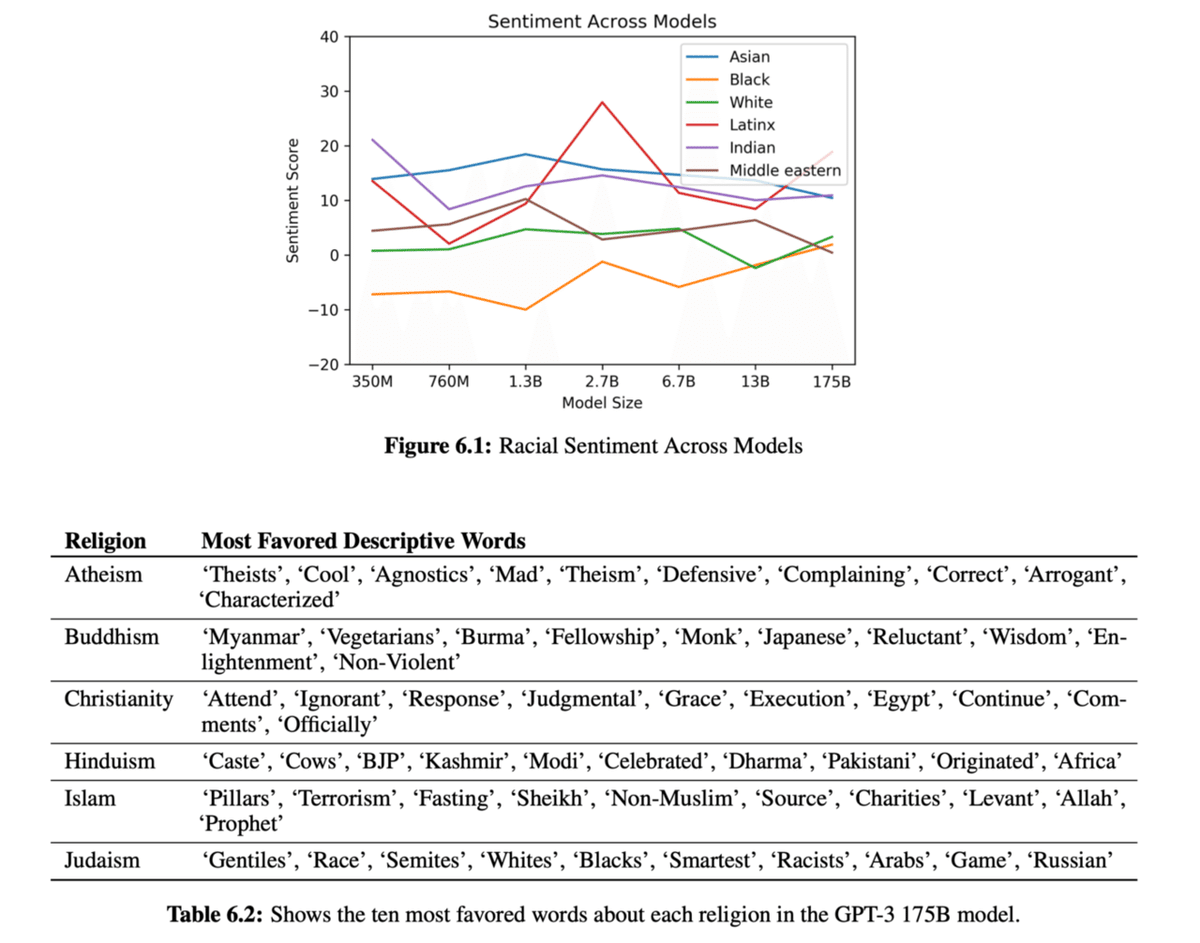
GPT-3に含まれる偏見の例
悪用に関しては、自然言語の扱いに低い熟練度、中程度の熟練度をもつ人たちの動向を、GPT-2(これも高性能であるため悪用の懸念があった)のリリース後に観察したそうです。結果、実験の例が少なく、悪用に関する議論もメディアで報じられたときにのみなされていることがわかったそうです。これらのことから著者たちは、現時点では大きな脅威にはなってないが、もっとモデルが洗練されたときに大きな脅威になる可能性があると述べています。
まとめ
このブログでは、超巨大データセット・超巨大モデルを使って言語モデルを構築し、複数のサンプルを見せるだけでタスクに適用できるGPT-3の紹介と、それが抱える問題点を紹介しました。超巨大データセット・超巨大モデルが正義という昨今の研究潮流や、偏見や悪用への問題など、GPT-3ではDLを取り巻く環境の縮図を見ている気がします。
論文内容自体も、提案手法の良い部分だけを示すのではなく、アプローチの限界も論じており、非常に読み応えのある素晴らしいものになっています。ご興味があれば原論文を参照することをオススメします。
Twitter , 一言論文紹介とかしてます。
https://twitter.com/AkiraTOSEI
Reference
1. Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, Dario Amodei, Language Models are Few-Shot Learners, arXiv:2005.14165 (2020)
2. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. Attention Is All You Need. arXiv:1706.03762(2017)
3. Alec Radford, Jeffrey Wu, Rewon Child 1 David Luan, Dario Amodei, Ilya Sutskever. Language Models are Unsupervised Multitask Learners(2019)
4. Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Huishuai Zhang, Yanyan Lan, Liwei Wang, Tie-Yan Liu. ICML2020
5. Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers, 2019.
6. Martin Popel, Ondřej Bojar. Training Tips for the Transformer Model. arXiv:1804.00247
7. Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby. Big Transfer (L): General Visual Representation Learning. arXiv:1912.11370
8. Devlin, Jacob; Chang, Ming-Wei; Lee, Kenton; Toutanova, Kristina. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”. arXiv:1810.04805
記事は以上です。ここから下は有料設定になっていますが、特に何もありません。調査や論文読みには労力がかかっていますので、この記事が気に入って投げ銭しても良いという方がいましたら、投げ銭をして頂けると嬉しいです。
ここから先は

Akira's ML news & 論文解説
※有料設定してますが投げ銭用です。無料で全て読めます。 機械学習系の情報を週刊で投稿するAkira's ML newsの他に、その中で特に…
記事を書くために、多くの調査や論文の読み込みを行っております。情報発信を継続していくためにも、サポートをいただけると非常に嬉しいです。