
2020年機械学習総まとめ 興味深い論文/記事85選

この記事では、2020年に発表された論文や記事のうち、特に興味深かったものを合計85紹介します。下記12のトピックに分けて紹介していますが、あくまで便宜上の分類です。私の個人的な2020年総括は以下の通りです。
--------------------- 個人的2020年総まとめと所感 ---------------------
2020年はTransformerが大躍進しました。自然言語処理では大規模なTransformerモデルであるGPT-3が高い精度を多くのタスクで叩き出しています。大量のデータと大量のパラメータを使って画像分類でも最高精度であったBig Transferを超えるものが出てきています。
差別的要素や著作権の問題のないフラクタル画像データセットはAIの倫理がさらに重視されるであろう今後は、非常に重要なものになってくるかもしれません。ImageNetにアクセスできない産業界の人間にも嬉しいデータセットです。
ラベルを使わない自己教師あり学習では、教師あり学習の精度に匹敵するものが多く発表されています。
Deep Fakeは社会問題になっていますが、生体信号を利用した検知方法が提案されています。また、被害者のプライバシー保護という良い意味での使い方も出てきています。
数値シミュレーションに機械学習を組みわせたものが出てきています。入出力パターンを学習させることでシミュレーションの超高速化ができ、企業の利活用が進むようになるかもしれません。
----------------------------------------------------------------------
Topics
1. 画像/動画系の分類タスク
2.教師なし学習/自己教師あり学習
3. 自然言語処理
4. 疎なモデル/モデル圧縮/高速化
5. 学習時の工夫/損失関数/データ拡張
6. Deep Fake
7. 生成モデル
8. 機械学習の自然科学分野への応用
9. 深層学習の解析
10. その他の研究
11. 実社会への応用
12. 技術系の記事
-----------------------------------------------------
1. 画像/動画系の分類タスク
-----------------------------------------------------
画像分野でもついにTransformerモデルが躍進してきて、CNNをベースとするモデルを超えてImageNetで最高精度を叩き出しました。ただし、JFT-300Mレベル(300万画像)のデータセットが必要、かつ、6億以上のパラメータ数(EfficientNet-B7の10倍程度)を必要とするので、まだ気軽に使えるものではありません。2021年は軽量化TransformerでCNNベースモデルを超える研究が出てくるかもしれません。フラクタル画像を使ったデータセットでは、著作権や差別的な要素を気にする必要はありません。ImageNetに気軽にアクセスできない産業界の人たちにも嬉しいですね。
学習時と推論時の解像度のずれを修正することで精度向上

Fixing the train-test resolution discrepancy: FixEfficientNet
https://arxiv.org/abs/2003.08237
EfficientNetは解像度を上げることで精度を向上させるが、学習時と推論時の解像度のずれにがある。学習後に浅い層を所定の解像度でFine-Tuningを行うことで、この差分を埋め、ImageNetにおいて外部データを使わずにNoisyStudentを超える結果を達成した(SotA)。
良い精度を出すネットワークの構造空間を探索する

Explore the structural space of the network, which gives good accuracy
Designing Network Design Spaces
https://arxiv.org/abs/2003.13678
ネットワークのパラメータ集合を考え、実験によって良い集合を見つけるネットワーク構造最適化手法を提案。NASのような完全自動化ではなく、むしろ熟練者の手動デザインに近いが具体的な評価方法と結果を示している。探索結果のRegNetはEfficientNet以上の精度で5倍高速。
U-Net in U-Net

U2-Net: Going Deeper with Nested U-Structure for Salient Object Detection
https://arxiv.org/abs/2005.09007
顕著物体検出において、様々な解像度の情報を有効に使うため、U-netをブロック化してU-netにするような構造を提案。事前学習なしで先行研究より効率的/高精度な結果を出した。
物体毎にカラー化することで精度向上

Instance-aware Image Colorization
https://arxiv.org/abs/2005.10825
白黒写真のカラー化において、画像全体を直接カラー化するより個々の物体をカラー化する方が簡単なタスクであるという見地から、物体を学習済みモデルで切り出したあとに処理することでカラー化する。背景に引きずれられずに物体毎に塗り分けができる。
学習済みモデルを用いた異常検知

Modeling the Distribution of Normal Data in Pre-Trained Deep Features for Anomaly Detection
https://arxiv.org/abs/2005.14140
学習済みモデルを用いて異常検知をする研究。複数の隠れ層の特徴量に多変量ガウス分布をフィットさせ、マハラビラス距離を使って異常を検出する。わりと実応用環境に近いMVTeデータセットでSOTA。
データ数毎のグループに”その他”を作ることでマイナーカテゴリに対応

Overcoming Classifier Imbalance for Long-tail Object Detection with Balanced Group Softmax
https://arxiv.org/abs/2006.10408
物体検知において、少数サンプルしかないカテゴリでは性能が悪くなる。そのようなデータセットに対する分類タスク用手法は、物体検知と相入れず精度がそこまで上がらなかった。そこでカテゴリの数毎にグループを設け、各グループ内に”その他”クラスを作る手法を提案。それによりマイナーカテゴリの分類精度を向上させることができる。
機械学習モデルは左右反転を検知できる

Visual Chirality
https://arxiv.org/abs/2006.09512
データ拡張で用いられる左右反転は、反転によってデータ分布が変わらないことを前提している。しかし、実はデータ分布が少し異なっており(時計は左手につける人がおおいが、反転すると右手につけるように見え、左手に時計がついている元データと異なる分布になる。)、DLを使うと反転した画像かどうか判断できた。このように反転させて分布が変わるものを抽出することで、新たなツールになるのではないかと期待がある。
画像サイズを変えると精度が向上する

MIND THE PAD – CNNS CAN DEVELOP BLIND SPOTS
https://arxiv.org/abs/2010.02178
paddingが精度の依存性を生んでいるという研究。ResNetのようにstride=2でダウンサンプルするネットワークは画像サイズによってはpadding画素が均等に使用されず、特徴量マップに不均一性を産む。(左端のpaddingは畳み込まれるが右端のpaddingは畳み込まれない)。これを均等になるように画像サイズを変えるだけで、精度が向上した。
多くのカテゴリを含むデータで事前学習するとone-shotに強くなる

Closing the Generalization Gap in One-Shot Object Detection
https://arxiv.org/abs/2011.04267
物体検知において、新たなカテゴリでfew-shot学習をする際は良い多くのカテゴリで学習させたモデルが良かった、という研究。データセットを作る際は、個々のカテゴリの数を集めるより多くのカテゴリを作る方に注力するのが良いという提言をしている。
EfficientNetより高速/高精度なLAMBDANETWORKS

LAMBDANETWORKS: MODELING LONG-RANGE INTERACTIONS WITHOUT ATTENTION
https://openreview.net/forum?id=xTJEN-ggl1b
画像に自己注意を適用する場合は画素毎AttentionとQueryの行列積で潜在表現を得るが、場所によらず固定されたkeyとvalueでの行列積で抽象化されたマップとQueryを掛け合わせることによって潜在表現を得るLambda Layerを提案。EfficientNetより高速/高精度な結果。
TransformerでCNNベースのモデルを超える
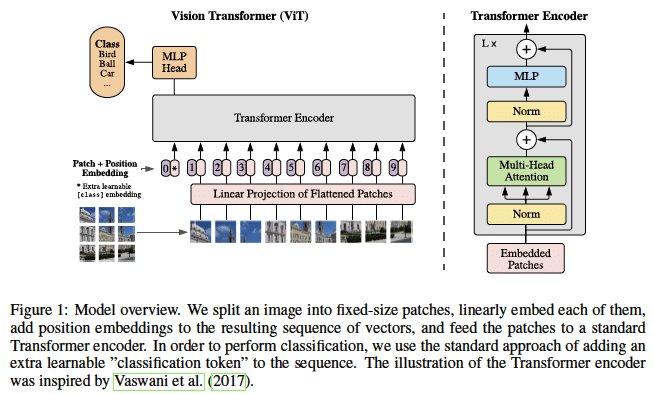
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
https://openreview.net/forum?id=YicbFdNTTy
Transformerは帰納バイアスがCNNと比較して少ないためImageNetなどの中規模なデータセットで学習すると上手くいかないので、大規模なJET-300Mデータセットで事前学習する戦略をとる。画像をパッチ分割し、それぞれのパッチを文書だと思って処理する。BiT-LやNoisy Studentを超える、または匹敵する結果。
著作権や差別の心配がないデータセットで事前学習をする

Pre-training without Natural Images
http://hirokatsukataoka.net/pdf/accv20_kataoka_fractaldb.pdf
フラクタル画像を用いて事前学習を行う研究。自然画像と違い関数を用いた合成画像なので著作権や差別の心配がないデータセットになっている。一部でImageNet pre-trainedモデルを超える精度を達成
EfficientDet-D7よりも高精度で高速な物体検知モデル

Scaled-YOLOv4: Scaling Cross Stage Partial Network
https://arxiv.org/abs/2011.08036
この研究では、Cross-Stage-Partial, Spatial-Pyramid-Pooling, Path-Aggregation NetworksなどでYOLOv3を最新手法で大幅に変更し、EfficientDetより高速かつ高精度にしたYOLOv4をベースに改良している。解像度、幅、深さのトレードオフを探索しEfficietntDet-D7を超える精度と速度を達成
-----------------------------------------------------
2.教師なし学習/自己教師あり学習
-----------------------------------------------------
ラベル情報を使わない自己教師あり学習では、SimCLRを皮切りに2つのネットワークを使った自己教師あり学習手法が多数提案されました。教師あり学習に匹敵する精度を出せるものが多くあります。大量のデータを持っているであろうGoogleやFacebookの研究が圧倒的な存在感を放っています。
1枚しかラベルデータがなくても学習できる

FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
https://arxiv.org/abs/2001.07685
ラベルなし画像に弱い変換を与えた画像のone-hot擬似ラベルと強い変換を与えた画像の予測ラベルにクロスエントロピーをかける半教師あり学習手法FixMatchを提案。ラベルありデータがかなり少量でも学習可能で、1データしかなくてもある程度精度が出る。パイパラに対する頑健性も調査しており、非常に良い論文。
以前書いた解説記事はこちら
単純な機構で高精度な表現学習手法SimCLR

A Simple Framework for Contrastive Learning of Visual Representations
https://arxiv.org/abs/2002.05709
教師なし表現学習SimCLRを提案。教師なし表現学習において、'強めのデータ拡張', 'より巨大なネットワーク構造', '追加の非線形変換後にロスをとる'の3つの戦略で複雑な機構を用いなくても、獲得表現を用いた分類で教師ありに匹敵する表現が獲得できることを示した。
マルチタスク、マルチモーダルで動画の表現学習を行う

Evolving Losses for Unsupervised Video Representation Learning
https://arxiv.org/abs/2002.12177
マルチタスク・マルチモーダルで教師なし学習をさせつつ、進化アルゴによるタスクバランスの調整と蒸留を使ってRBG動画を入力とするネットワークに情報を集約する機構を提案。200万動画を利用することで行動検知タスクにおいて非常に高い精度を達成した。
教師あり学習と同等以上の自己教師あり学習手法

Big Self-Supervised Models are Strong Semi-Supervised Learners
https://arxiv.org/abs/2006.10029
少数のラベルのみを使用して、教師あり学習と同等以上の性能を出すSimCLRv2を提案。教師なし学習→FineTune→ラベルなしデータを使った自己蒸留の3段階で構成される。基本的には大きいモデルが強い
行動の教師なし表現学習

Aligning Videos in Space and Time
arxiv.org/abs/2007.04515
ビデオにおける行動の対応部分を教師なしで検出する研究。教師なしで学習したトラッカーからで検出されたパッチ同士の距離を測ることによって、パッチレベルの対応関係を学習する。既存の特徴量抽出機より良い精度で検出できる。
敵対的摂動で対照学習を改善

VIEWMAKER NETWORKS: LEARNING VIEWS FOR UNSUPERVISED REPRESENTATION LEARNING
https://arxiv.org/abs/2010.07432
対照学習ではデータ拡張に対して不変になるように表現を学習するが、データ拡張手法は専門家が選んでいた。それの代わりに敵対的摂動を画像に載せるveiw makerを提案。ドメインに関係なく適用でき、音声やウェアラブルデバイスの時系列データで大きな改善。
因果グラフの考えをとりいれた自己教師あり学習

REPRESENTATION LEARNING VIA INVARIANT CAUSAL MECHANISMS
https://arxiv.org/abs/2010.07922
画像がコンテンツ(動物種)とスタイル(背景など)の因果グラフで画像が構築されると考え、スタイルに対して不変にするように学習させる自己教師あり学習RELICを提案。具体的にはデータ拡張によるスタイル変換に不変になるように、個々の画像の分類と分布の一致を行わせる。先行研究を匹敵するだけでなく強化学習でも効果があった。
半教師あり学習と対照学習の組み合わせ

FROST: Faster and more Robust One-shot Semi-supervised Training
https://arxiv.org/abs/2011.09471
半教師あり学習に対照学習のロスを組み込むことで、学習がより高速になるFROSTを提案。128エポックのみで教師あり学習の精度に匹敵し、ハイパーパラメータの選択にも頑健。
-----------------------------------------------------
3. 自然言語処理
-----------------------------------------------------
自然言語処理では、多くのTransformer改良系の研究が提案されました。多くは計算効率化に焦点をおいているので、画像系との進出も相まってさらに軽量化が進むかもしれません。1750億のパラメータをもつGPT-3は多くのタスクで素晴らしい成果を出しました。しかし、データに含まれる差別的な要素を再現してしまったり、「チーズは冷蔵庫だと溶けるか」というような物理的な解釈ができない、質疑応答タスクは不得意、などの問題点も見えてきました。
Self-Attentionの内積は必須か?

SYNTHESIZER: Rethinking Self-Attention in Transformer Models
https://arxiv.org/abs/2005.00743
TransformerのSelf-Attentionの機構を再検証した研究。
通常のSelf-Attentionではtoken間の相互作用を取るために内積をとるが、相互作用をとらずにAttention weightをtoken毎に独立に生成したり、Attention Weightを学習パラメータにしたりしても、そこそこ性能が出る。
超大規模言語モデルGPT-3

Language Models are Few-Shot Learners
https://arxiv.org/abs/2005.14165
1750億ものパラメータ数をもつ自己回帰型言語モデルGPT-3を提案。多くのタスクで非常に高い性能を発揮する。一方で、データに含まれる差別的な要素を再現したり、「チーズは冷蔵庫だと溶けるか」というような物理的な解釈ができない、質疑応答タスクは不得意、などの問題点も見えてきた。
Attentionをとる場所を限定することで効率化する

Big Bird: Transformers for Longer Sequences
https://arxiv.org/abs/2007.14062
Self-Attentionnの効率化をした研究。ランダム、周辺のみ、一部のtokenのみでフルAttention、の3要素を組み合わせる。多くのNLPタスクでSOTAで、理論的にもsequence-to-sequenceの近似になっており、チューリング完全性になっていることを示した。
Transformer改善系のサーベイ

Efficient Transformers: A Survey
https://arxiv.org/abs/2009.06732
自然言語処理を中心に近年広がってきたTransformerモデルの改善系のサーベイ論文。メモリ改善やattentionの使い方などの項目ごとにまとめられている。図表とDiscussionだけ見ても、なんとなく流れがつかめる。
Tokenと関連した画像を組み合わせて事前学習を行う

Vokenization: Improving Language Understanding with Contextualized, Visual-Grounded Supervision
https://arxiv.org/abs/2010.06775
人間は言語を学習する際に文字情報だけでなく視覚情報も使うことに着想を得てtokenと関連した画像vokenを出力させるvokenizerを用いた学習手法を提案。通常の言語モデル事前学習と同時にvokenizerによる関連画像も学習することによって、より良い表現を得られる。
多言語モデルバージョンのT5

mT5: A massively multilingual pre-trained text-to-text transformer
https://arxiv.org/abs/2010.11934
あらゆるタスクをtext2textの形式に統一し、事前学習→Fine-tuneの戦略をとるT5を多言語で実施したmT5と大規模で101言語を含む多言語データセットmC4を提案。最大で130億のパラメータを持ち、色々なタスクで最高性能を達成。
日々の医療業務で得られるデータを使った事前学習

CONTRASTIVE LEARNING OF MEDICAL VISUAL REPRESENTATIONS FROM PAIRED IMAGES AND TEXT
https://arxiv.org/abs/2010.00747
医療業務で日常的に作られる医療画像とテキストのペアデータにおいて対照学習で表現学習を行う研究。ペアのテキストと画像の距離を近づけるように表現学習を行う。ImageNet学習済みモデルより有用な表現を得ることができ、画像検索等で大きく精度を上げることができた。
-----------------------------------------------------
4. 疎なモデル/モデル圧縮/高速化
-----------------------------------------------------
近年はBig Transfer, GPT-3の登場で大規模化の流れがすすんでいるので、実応用上高速化とモデルの軽量化は大きなトピックです。既存の手法を上手く組み合わせてモデルサイズを1/47に圧縮したものや、Wavelet変換を使った圧縮方法も登場しています。
計算資源が少ないときこそ大きなモデルを使うべき

Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers
https://arxiv.org/abs/2002.11794
計算資源が限られている場合は、小さなモデルで学習/推論させるよりも、大きなモデルで学習させて圧縮させる方がよいという提案。大きなモデルの方が収束が早く、圧縮しても精度の落ち込みが少ないとのこと。
GANの既存モデルをを1/47にまで圧縮

GAN Slimming: All-in-One GAN Compression by A Unified Optimization Framework
https://arxiv.org/abs/2008.11062
GANのGeneratorを小さくする研究。蒸留・量子化・枝刈を組み合わせる。量子化は通常微分不可だが擬似的な勾配を使うことでE2Eの学習を可能にしている。既存のモデルを1/47にまで圧縮することに成功した。
Wavelet変換を用いてGANを圧縮する

not-so-BigGAN: Generating High-Fidelity Images on a Small Compute Budget
https://arxiv.org/abs/2009.04433
Wavelet変換(WT)を用いて低周波情報のみから画像を再現することで、少ない計算資源で高精細画像をGANで生成する研究。具体的には失われた高周波情報をNNで再現し、逆Wavelet変換(iWT)をかける。生成画像の質は少し下がるがTPUx256からGPUx4にまで計算資源を落とすことに成功。
各層をブロックに分けた枝刈パターンで高精度/低レイテンシを実現

YOLObile: Real-Time Object Detection on Mobile Devices via Compression-Compilation Co-Design
https://arxiv.org/abs/2009.05697
モバイル用物体検知において、高精度と低レイテンシを両立するために、各層をブロックに分け、各ブロックでそれぞれ異なる枝刈パターンを学習させるBlock-puhched pruningを提案。精度を保ったまま高速化させることに成功した。さらに畳み込み層をGPUで計算、それ以外をCPUで計算させることにより更なる高速化を実現した
重みを圧縮しやすいように並び替えることで量子化をする

Permute, Quantize, and Fine-tune: Efficient Compression of Neural Networks
https://arxiv.org/abs/2010.15703
重みを圧縮しやすいように並び替えることで量子化をする研究。並び替えた重みをブロックに分割し、それらを直接使わずに予め保持していたベクトルの組みから最近傍のもので代替させる。精度を保ったままResNet50を1/31に圧縮できる。
-----------------------------------------------------
5. 学習時の工夫/損失関数/データ拡張
-----------------------------------------------------
活性化関数では、学習可能パラメータを組み込んだものがいくつか発表されています。適応的に活性するかどうかを判断できる、という意図があるようです。間違いラベルの問題も実応用上は大きなトピックであり、学習速度の差を利用したり、損失関数を滑らかにすることで対応する研究もあります。
隠れ層で行うデータ拡張手法

PatchUp: A Regularization Technique for Convolutional Neural Networks
https://arxiv.org/abs/2006.07794
正則化手法PatchUpを提案。Cutmix(https://arxiv.org/abs/1905.04899)を隠れ層で実施するようなイメージ。ManifoldMixupの発想のように中間層の方が特徴量ベクトルが整理されているから、そこでやるのがよかった的な感じだろうか。
正しいラベルと間違ったラベルの学習速度の差を利用する

Early-Learning Regularization Prevents Memorization of Noisy Labels
https://arxiv.org/abs/2007.00151
ラベルノイズがある状況において、正しいラベルのものは正常に学習する一方間違ったラベルのデータは最初は正しいラベルを予測するが、その後に間違ったラベルに引っ張られてデータをまる覚えする現象があることを発見。その現象を利用し、モデルの出力の移動平均を使った正則化手法ESRを提案。ラベルノイズがある場合に非常に有効な結果。
1フィルター1カテゴリの制約をかけることで可視化性能を向上させる

Training Interpretable Convolutional Neural Networks by Dierentiating Class-specic Filters
https://arxiv.org/abs/2007.08194
CNNのフィルターを1フィルターが1つのカテゴリを担当するような制約をかけることで、解釈性能を向上させる研究。最終層のフィルターに[0,1]の学習可能な行列をかけることにより、各フィルターが1つのカテゴリしか使わないようにする。分類性能も損なわず、CAMによる可視化がより良くなる。
活性するかを判断する活性化関数

Activate or Not: Learning Customized Activation
https://arxiv.org/abs/2009.04759
ReLUとSwishを統一的に扱い、その一般的な形としての活性化関数ACtivationOrNot(ACON)を提案。活性化関数の中に複数の学習可パラメータが入ることで、活性するか否かを自由に変えられる。物体検知、画像検索で精度が向上することを確認した。
損失関数が sharp minimaに陥いることを防ぐ

Sharpness-Aware Minimization for Efficiently Improving Generalization
https://arxiv.org/abs/2010.01412
損失関数が sharp minimaに陥いることを防ぐように、モデルのパラメータに損失が最も上昇するような摂動を加えた上で最適化を行うSAMを提案。汎化性能が向上し、ラベルノイズにも頑健であることを確認した。
-----------------------------------------------------
6. Deep Fake
-----------------------------------------------------
Deep Fakeを使った政治的発言をするSNSアカウントが発見されたり、Deep Fakeは大きな社会問題になりそうです。KaggleにもDeep Fake検知のコンペが出てきたことからも関心が高まっていることがわかります。検知の方法も進化しており、心拍数を利用したり、生体信号を使ったり、生物的な見地を活かした検知手法が提案されています。また、反社会的な目的ではなく、被害者のプライバシーを守りつつ映像にリアリティーを持たせるような使い方も提案されています。
心拍を利用してDeep Fakeを検知
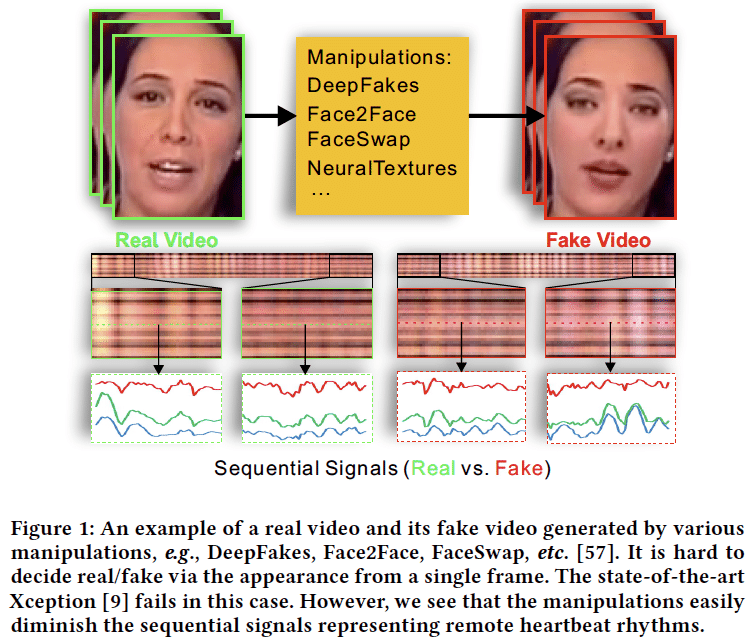
DeepRhythm: Exposing DeepFakes with Attentional Visual Heartbeat Rhythms
https://arxiv.org/abs/2006.07634
心拍による皮膚の色変化を検知することでDeep Fakeを検知する研究。現状の生成モデルはリアルな動画を作れるが、血液による肌の色の微妙な変化のリズムを再現できないことを利用する。
Deepfake検出コンペで活躍した手法

Detecting Deepfake Videos: An Analysis of Three Techniques
https://arxiv.org/abs/2007.08517
KaggleのDeepfake検出コンペで使用した手法の紹介。
「まばたきの回数」「ヒストグラムの違い」をモデルに取り込むことで精度が上がった
生物学的な信号を利用することでDeep Fakeを検知

How Do the Hearts of Deep Fakes Beat? Deep Fake Source Detection via Interpreting Residuals with Biological Signals
https://arxiv.org/abs/2008.11363
深層生成モデルを使ったDeepFake(偽ビデオ)は社会問題になっている。PPGという生物学的な信号の情報を使うことで、DeepFake検知の精度97.29%を達成した。また、生成モデル毎に特有な偽のPPG信号っぽいものを生成することがわかり、生成モデルの特定も93.39%でできた。
Deep fakeで被害者を守る
迫害されて逃げてきた人たちのドキュメンタリーにおいて、Deepfake技術を使って顔を合成することで被害者を守る。単に顔をぼかしたり合成音声を使うと、リアルさが失われ親近感が湧かないが、deepfakeを使うことでリアルさを保ったまま被害者のプライバシーを保護することができる。
-----------------------------------------------------
7. 生成モデル
-----------------------------------------------------
生成モデルでは、GANを使った高解像度や生成画像の質に焦点を当てた研究より、潜在空間の解釈性や少ないデータを使った生成、動画編集アプリケーションに焦点を当てた研究が多く見られました。また、FLOW系を使った手法も多く提案されています。FLOW系は画像→潜在空間への逆変換が出来るため、潜在空間を使って色々なことが出来るかもしれません。
画像の品質と潜在空間の整然さを両立

High-Fidelity Synthesis with Disentangled Representation
https://arxiv.org/abs/2001.04296
β-VAEなどでdisentangleな表現を得るEncoderを学習した後、それを使ってGANで画像生成をすることで、画像の品質と潜在空間の整然さを両立させID-GANを提案。1024^2の高品質画像を生成しながらも画像を自由に操作できる。
潜在空間を利用することで高解像度化を行う

PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models
https://arxiv.org/abs/2003.03808
超解像において、低解像度画像を高解像にしてロスをとるのではなく、低解像度画像を学習済みモデルで高解像度化した画像を低解像度に戻したときに同じ画像になるような潜在空間を探す、という戦略をとる。大規模なネットワークを学習する必要もなく、ネットワークの選択に縛られない手法。
2つの画像間で見た目をそのままに構造を転移させる

Structural-analogy from a Single Image Pair
https://arxiv.org/abs/2004.02222
2つの画像間で見た目をそのままに構造を転移できるGAN。SinGANと同じようにUpSamplingした画像をGeneratorで補完するが、それをスタイル変換にも用いることが肝。動画への応用もでき、その結果が素晴らしい。
GANとAutoEncoderを組み合わせて整理された潜在空間と高品質画像両方を得る

Adversarial Latent Autoencoder
https://arxiv.org/abs/2004.04467
EncoderとDecoderを2つに分割し、その中間表現の分布をGANのように敵対的学習をさせることにより、Sota GANレベルの表現力と整理された潜在空間両方を達成できるAutoEncoderを提案。非常に高品質な画像が生成できている。
データ拡張の適用確率を適応的に変えることで少ないデータで高品質な生成画像を得る

Training Generative Adversarial Networks with Limited Data
https://arxiv.org/abs/2006.06676
データ拡張(とDにおける拡張データ間のcycle consistency活用)は過適合を防ぐが、データ拡張適用確率pが大きすぎると生成データにも拡張の影響が出る。そこでpを適応的に調整すること生成への影響を防ぎつつ過適合を防ぐGANを提案。数千のデータのみで高品質な画像を作ることに成功。
マルコフ過程と変分推論を組み合わせてCIFAR10でFID3.1を達成

Denoising Diffusion Probabilistic Models
https://arxiv.org/abs/2006.11239
The model that combines Markov processes and variational inference achieves FID3.17(SOTA) at unconditional CIFAR10. It is an AutoEncoder-like model, but with each layer considered as a stochastic process and parameterize the noise to be applied there.
正規化流を使った高解像度画像生成

SRFlow: Learning the Super-Resolution Space with Normalizing Flow
https://arxiv.org/abs/2006.14200
正規化流を使った高解像度画像生成。複数の損失項の調整が必要なGANと異なり対数尤度のみを最適化することで学習する。また、可逆変換を使っているため潜在表現との一対一対応させることが可能なので、高解像度の潜在変数を使ってスタイル変換もできる。
階層的なVAEで高解像度画像

https://arxiv.org/abs/2007.03898
階層的なVAEで高解像度画像を生成する研究。
各階層で直接分散・平均を計算させるのではなく、前の層の相対平均等を加味した分布を設計している。また、swish活性化やSEモジュールを導入したセル、spectral norm、カーネルサイズを広げてdepth-wise convを用いて計算量を削減しつつ視野を広げるなど様々な工夫がある。
Hessianを使った正則化でdisentangleな表現を得る

The Hessian Penalty:A Weak Prior for Unsupervised Disentanglement
https://arxiv.org/abs/2008.10599
GANの潜在空間においてdisentangleな表現を得る研究。ある方向iに変化させることで他の要素j(≠i)に変化を与えないようにHessianを使った正則化項を提案。学習済みモデルに対してもFine-tuningが可能になっている。
動画から人を消去する

Flow-edge Guided Video Completion
https://arxiv.org/abs/2009.01835
Flowを用いたビデオの欠損補完の研究。ポイントは①欠損部エッジ検出して繋げる(補完する)ことでFlowの補完③少し時間的に遠いフレームを使ったFlow計算で見えない部分を取得③勾配を用いた再構成で継ぎ目を防ぐ。先行研究より定量的に優れており、ビデオから人を消すこともできる。
動画中の人物の動きのタイミング(動作の開始、速度)を変更

Layered Neural Rendering for Retiming People in Video
https://arxiv.org/abs/2009.07833
動画中の人物の動きのタイミング(動作の開始、速度)を変更できるモデル。まず、影になっている人も含めてそれぞれの人の動きと背景を分離する。そして、背景とそれぞれの人の情報を組み合わせて特徴量化し、それらを組み合わせることで合成する。人の動きに付随する水しぶきなどのタイミングも変更できている。
常微分方程式ソルバでGANを安定させる

Training Generative Adversarial Networks by Solving Ordinary Differential Equations
https://arxiv.org/abs/2010.15040
GANの訓練における不安定性が連続時間ダイナミクスを離散化する際の積分誤差に起因していると考え、ODEソルバー(Runge-Kutta等)と積分誤差を制御する正則化器と組み合わせることでGAN学習を安定化させた。SpectralNorm等がなくても学習が安定し、優れた結果を出した。
少数データかつ小計算量で高解像度をゼロから学習/生成

TOWARDS FASTER AND STABILIZED GAN TRAINING FOR HIGH-FIDELITY FEW-SHOT IMAGE SYNTHESIS
Image
https://openreview.net/forum?id=1Fqg133qRaI
少数データ(100~1000)かつ小計算量(1GPUx十数時間程度)で高解像度(256^2~1024^2)をゼロから学習/生成できるGAN。各解像度の情報を組み合わせるSLEモジュールと、Discriminatorの中間特徴量マップから再構成を行わせる制約で強化することが技術的な肝。
確率微分方程式の逆過程を利用して画像を生成

SCORE-BASED GENERATIVE MODELING THROUGH STOCHASTIC DIFFERENTIAL EQUATIONS
https://openreview.net/pdf?id=PxTIG12RRHS
ノイズを摂動させて画像を生成する通常の生成モデルと異なり、確率微分方程式を用いてノイズが時間的に発展する連続体を考える。それの過程を逆にすることでノイズから画像を生成する。CIFAR10においてIS 9.9, FID 2.2を達成し、さらに1024x1024サイズの画像も生成可能。
-----------------------------------------------------
8. 機械学習の自然科学分野への応用
-----------------------------------------------------
自然科学と機械学習を組み合わせた研究が多く発表されています。数値シミュレーションを機械学習を使って高速化したり精度を上げたりする研究が多くあり、物理の密度汎関数理論、流体シミュレーションで成果を上げています。
自然科学研究者のためにDL活用の手引き

A Survey of Deep Learning for Scientific Discovery
https://arxiv.org/abs/2003.11755
自然科学研究者のためにDL活用の手引きを記した論文。DLでどのような分野があり、どう活用できるのかをチュートリアル付きで詳しく解説している。GAN、Transformer, Seqmentationなど幅広いトピックで解説しているので、自然科学界隈に限らず初学者が読んで全体像を把握するのに良いかもしれない。
Kohn-Sham方程式を微分可能なモデルとして扱うことで物理制約を課す

Kohn-Sham equations as regularizer : building prior knowledge into machine-learned physics
https://arxiv.org/abs/2009.08551
密度汎関数理論を用いた物理シミュレーションをニューラルネットワークで近似する問題において、Kohn-Sham方程式を微分可能なモデルとして扱うことにより、物理的な制約をMLモデルに課すことができる。それにより交換相互作用項計算の精度を大きく向上させることができた。
流体シミュレーションを1000倍以上高速化する

Fourier Neural Operator for Parametric Partial Differential Equations
https://arxiv.org/abs/2010.08895
フーリエ空間における積分カーネルの計算をニューラルネットワークで代替させる研究。Navier-Stokes方程式等の流体シミュレーションに適用した結果、数値シミュレーション(FEM)に比較して最大1000倍以上の高速化を実現した。
デカルト座標を用いることでモデルを単純化する

Simplifying Hamiltonian and Lagrangian Neural Networks via Explicit Constraints
https://arxiv.org/abs/2010.13581
一般化座標を用いると制約条件が含まれる代わりにハミルトニアンが複雑になってしまうが、デカルト座標に埋め込んだ制約付きハミルトニアンを使うことで数式を単純化でき学習を容易にする。複雑な系であるN重振り子、ジャイロスコープで精度/データ効率が劇的に向上した。
珍しい現象を監視する機械学習モデルの構築
太陽風が地球の磁気圏に衝突することで起こる"magnetic eruptions"は珍しいため、高度な技術を持った科学者を動員して専任で監視していた。この記事では、その手助けをする機械学習モデルを構築する際の試行錯誤を述べている。難しい作業なので、学習ループに科学者を巻き込む「Scientist in the Loop”」を使うことで精度を高めた。
-----------------------------------------------------
9. 深層学習の解析
-----------------------------------------------------
深層学習がどのような挙動するかという研究も多く発表されています。同じような構造をもつブロックが出てくることがわかったり、それぞれのユニットの役割を特定して生成画像を操作したり、という研究があります。敵対的サンプルで学習させたモデルは人間と似た解釈をする、という研究は個人的には非常に示唆的かと思います。敵対的学習は主に高周波を載せるので、低周波情報、つまり物体の形状で判断根拠を求めるから、人間に近い判断になるのかもしれません。
Batch Normを使うと学習初期は実質的に浅いネットワークで訓練している

Batch Normalization Biases Deep Residual Networks Towards Shallow Paths
https://arxiv.org/abs/2002.10444
ResNetは2^dのパスに分解できるが、BatchNorm(BN)は各Blocksの出力の分散を抑えるため実質的に浅いパスの貢献が初期化時に大きくなる。各ブロックで分散を抑えるために係数αを導入するSkipInitで同様の効果を得ることができることを示した。
Layer Normalizationやpre-normのTransformerも同様の効果が得られているため、効果的に学習できる。オリジナルのTransformerのような形でskip側もnorm入れるとこの効果は得られない。
敵対的ノイズで学習したモデルは人間に近い判断をする

Adversarially-Trained Deep Nets Transfer Better
https://arxiv.org/abs/2007.05869
普通に学習したモデルと比較して敵対的ノイズを乗せながら学習したモデルは、転移学習において高い性能を示した。可視化した結果、より人間に近い感覚で分類をしていることがわかり、それが影響しているのでは、とのこと。
白色化は相関を消去するので精度に悪影響を与えることがある

Whitening and second order optimization both destroy information about the dataset, and can make generalization impossible
https://arxiv.org/abs/2008.07545
白色化はカテゴリ毎のデータ相関を消去し、ノイズと信号の区別ができなくなる。2次の最適化も白色化と同様の効果が見込め、両者とも汎化性能に悪影響を与える。しかし学習自体は高速になり、適切な正則化をかければ2次の最適化では汎化性能が出るので、計算リソースがボトルネックになる場面では良いかもしれないとのこと。
DNNの各々のユニットの役割を解釈する

Understanding the Role of Individual Units in a Deep Neural Network
https://arxiv.org/abs/2009.05041
DNNの各々のユニットの役割を解釈する研究。明示的に”木”などの概念を与えなくても、それらを学習しているユニットが存在していることを発見。GANにおいて、各々の概念を司るユニットを操作することで画像から木を減らしたり、建物にドアをつけることに成功した。
様々なデータドメインにおけるスケール則

Scaling Laws for Autoregressive Generative Modeling
https://arxiv.org/abs/2010.14701
様々なドメインにおいて計算資源、データ量、モデルサイズのスケール則を調査した研究。調査したドメイン全てで3つの量に対するべき乗の関係が存在し、ドメインに最適なモデルサイズはドメインによらず普遍的な傾向を示した。
表現力の高いネットワークは複数の層において似た表現を学習していることを発見

DO WIDE AND DEEP NETWORKS LEARN THE SAME THINGS? UNCOVERING HOW NEURAL NETWORK REPRESENTATIONS VARY WITH WIDTH AND DEPTH
https://arxiv.org/abs/2010.15327
深いまたは幅広いネットワークは、複数の層において似た表現を学習している(block構造と呼ぶ)ことを発見。これは層表現の主成分に対応しており、ネットワーク固有の表現となっている。これらを使って精度への影響を極力抑えた枝刈りが可能である。また、幅広いモデルはシーン判別に強く、深いモデルは消費財判別に強いという傾向があった。
同じ予測性能を示すモデルパラメータが複数存在することが原因で汎化性能が低下する

Underspecification Presents Challenges for Credibility in Modern Machine Learninghttps://arxiv.org/abs/2011.03395
MLモデルを実運用すると性能が劣化する問題において、同じ予測性能を示すモデルパラメータが複数存在するUnderspecificationが関わっていることを示した。このUnderspecificationはNLP、医療画像、コンピュータビジョンなどあらゆる分野に現れており、これらを考慮したテストを実施する必要がある。
-----------------------------------------------------
10. その他の研究
-----------------------------------------------------
必要とされる計算量が急激に肥大化しており何らかの手を打たないといけないという研究が発表されています。2019年末のBig Transfer、GPT-3、ViTに代表されるように近年モデルが大規模かする傾向があり、「AIの民主化」の観点でも手を打たなければならないかもしれません。
学習データとテストデータの分布の違いに対処する

https://arxiv.org/abs/2004.03045
Trainとtestのデータ分布が異なるタスクに対して、train/testを見分ける分類器を訓練しスコアがランダムになるまで分類器の重要な特徴量を削除することで、分布を一致させるAdversarial Feature Selectionで対応した。validationをtestに近いデータを使うものや、trainをtest分布に従って重み付けするものより良かったとのこと。
AlphaZeroでゲームバランスを評価する

Assessing Game Balance with AlphaZero: Exploring Alternative Rule Sets in Chess
https://arxiv.org/abs/2009.04374
囲碁や将棋で人間以上のパフォーマンスを発揮するAlphaZeroを用いて、ゲームバランス評価をする試み。キャスリング不可など微量のルール変化を与えたチェスもどきをAlphaZeroで学習させることで、熟練プレーヤーがゲームにおいてどのような見方をしているのかを見ることができる。
必要とされる計算力が加速的に肥大化している

The Computational Limits of Deep Learning
https://arxiv.org/abs/2007.05558
Deep Learningは膨大な計算力を使うことで多くのタスクの性能を向上させたが、必要とされる計算力がどんどん大きくなっているので、ハードウェアの発展次第では失速していくかもしれないことを示唆した論文。金銭的・環境的な負荷も法外なものになっていくので、抜本的な改善が必要ではないかと提言している。
PCAを分散化可能なアルゴリズムにする
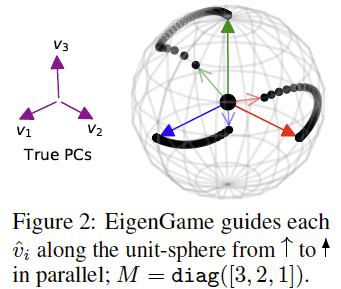
EigenGame: PCA as a Nash Equilibrium
https://arxiv.org/abs/2010.00554
PCAを各固有ベクトルが自身の効用関数を最大化するゲームをしていると解釈し、ナッシュ均衡状態でPCAが成立することを示した。これは分散化可能なアルゴとして実装することができるため、大規模なニューラルネットワークの解析を実施することができた。Auto Encoderでも同じようなことはできるが、主成分を回復することと等価でもないし、disentangleもできないため、重要な結果。
-----------------------------------------------------
11. 実社会への応用
-----------------------------------------------------
実社会の応用に関しては、簡単なタスクを機械学習に任せるという事例が、法律分野と建築分野で出てきています。このように機械学習と人間が協業することは、機械学習が簡単な問題を解くことで機械学習モデルの開発コストを下げられ、人間がより複雑なタスクに集中して生産性を向上させられるため、個人的には非常に現実的な機械学習活用路線だと思っています。
優秀な弁護士がAIに敗北
秘密保持契約の欠陥を見つけるタスクでトップの弁護士を上回り、通常の弁護士が92分かかる秘密保持契約の審査をAIは26秒で審査できる。弁護士からの反応は肯定的で、より複雑なプロジェクトに弁護士が集中できるなどのメリットを上げている。
農業の機械学習プロジェクト
農業に機械学習を適用した事例。 農業の雑草除去をDeep Learningを使って選別して行ったプロジェクトのことが書いてある。Kaggleにあるデータセットを使い、雑草の専門家と連携しながらモデルの改善を行ったようだ。
機械学習を農業に応用した事例。ディープラーニングを使って農業の雑草を選択的に除去したプロジェクトについて書かれており、どうやらKaggleのデータセットを使い、雑草の専門家と協力してモデルを改善してもよう。
AIの力を借りて植林する
ヒートアイランド現象は公衆衛生上の懸念になるが、都市に植林をすることでそれを防ぐことができる。GoogleのTreeCanopy Labでは、空撮画像と機械学習で都市の樹木被覆密度を示すマップを作ることができ、これにより人手による樹木調査をする必要がなくなる。Tree Canopy Labは、2021年までに90,000本の植樹と維持を行い、503平方マイル以上の都市に年間20,000本の植樹を続けるという短期的な目標を掲げており、すでに市内の人々がこの目標を達成できるよう支援している。
機械学習を用いて密猟から動物を保護する
Googleと国際的な保護慈善団体であるZSLは、機械学習を用いて銃声を特定する機械学習モデルを構築した。音響センサーにより最大1km離れた銃声を検知でき、それにより野生動物保護活動家の活動を補助することができる。
建築現場の細かな進捗をAIで管理する
英国-イスラエルのスタートアップ企業であるBuildots(https://buildots.com/)は、頭に取り付けた360°カメラから約150,000個の部品がどの状態にあるのか(取付済みなど3〜4段階)を監視できる。すでに小規模な建築現場で導入されており、人間の管理者が確認作業など単調な仕事ではなく、より重要な仕事に注力できるようになると期待されてる。
AIを使って情報戦を解析する
大量のニュースや発信される情報を自然言語処理で解析することで、情報戦に対応したという記事。最近のアルメニアとアゼルバイジャンの紛争の数ヶ月前から、ある一方の国を侵略者と描くような意図を持って情報が発信されていると解析するなどしている。
強化学習を使った税制のシミュレーション
レーションを行った研究。ボードゲームCatanのような環境で税制を改善するRLとその税制の中で最適行動する労働者(エージェント)を交互に学習させ、経済を発展させる。既存の税制より強化学習で得られた税制の方が最終的に大きな経済規模になった。
-----------------------------------------------------
12. 技術系の記事
-----------------------------------------------------
stateof.aiのまとめ資料はトピックが多岐に渡っており、非常に読み応えがあるためオススメです。研究の動向や人材の所在、倫理への問題、軍事利用への拡大、来年の動向予測など幅広いテーマでまとめられている。研究に関しては巨大データセット/巨大モデルが精度を牽引、ということが書かれています。
2020年の人工知能発展のレポート
177ページにわたる大規模な報告資料。研究の動向や人材の所在、倫理への問題、軍事利用への拡大、来年の動向予測など幅広いテーマでまとめられている。研究に関しては巨大データセット/巨大モデルが精度を牽引、生物学でAIを用いた論文が増加、PytorchがTensorflowに追いつきつつある、など
画像データセットに潜む偏見を特定
画像データセットに潜む偏見を特定するツールが公開。既存の画像注釈と、オブジェクト数、オブジェクトと人の共起、画像の原産国などの測定値を使用して、測定する。人とオルガンに関しては、男性は演奏している、女性は演奏していないけど同じ空間にいる、などの違いがあった。
強化学習の分野別重要論文リスト
OpenAIがまとめた強化学習の分野別重要論文リスト。Model Free, Model-based, Meta-RLなどの各分野で3~10個ほど重要論文が挙げられている。
データサイエンティスト面接の120以上の想定質問
データサイエンティスト面接の120以上の想定質問とその回答。統計/機械学習の基礎知識や実務での活用を問う内容になっている。統計/機械学習の基礎が習得できているかをテストする意味でもおすすめ。
物体検知の推論速度を9→650FPSまで高速化
物体検知の推論速度を9→650FPSまで高速化させた記事。CPU/GPU間の転送回避/重い計算をGPUにさせる/バッチ処理すること/半精度の使用/などが挙げられている。Nsight SystemsでCPU/GPUの使用状況がを逐一見ながら適応手法の根拠を示してくれるので非常に納得感がある
説明性の解説記事
説明性とはそもそも何か、から始まって具体的な説明性の例の原理や弱点を豊富な図説で解説していて非常にわかりやすい。産業界でMLに関わるならば是非一読すべき資料。
決定木系の手法は、何故ニューラルネットより強いことが多いのか?
ニューラルネットワーク(NN)は確率的にモデルのフィッティングを行うが、決定木系は決定論的にフィッティングを行う。画像のように0/1で表現できないものや自然言語のように曖昧で例外が多いものはNNが強いが、多くの事象はYes/Noで処理できるため決定木系が強い、と提議
---------------------------------------------------------------------
☆☆ 宣伝 ☆☆
2021/1/16(土)にNeurIPS2020の読み会をやります!
招待講演として早稲田外学の森島先生と、同じく早稲田大学の尾形先生にご登壇いただきますので、是非ご参加ください!発表者も大募集中です!
(URLが1/12になってますが1/16開催です)
---------------------------------------------------------------------
過去の記事
Week 50の記事 , Week 51の記事
2020年9月のまとめ
2020年10月のまとめ
2020年11月のまとめ
---------------------------------------------------------------------
TwitterでMLの論文や記事の紹介しております。
https://twitter.com/AkiraTOSEI
記事は以上です。ここから下は有料設定になっていますが、特に何もありません。この記事が気に入って投げ銭しても良いという方がいましたら、投げ銭をして頂けると嬉しいです。
投げ銭ありがとうございます。毎週高品質の投稿ができるように精進いたします。

記事を書くために、多くの調査や論文の読み込みを行っております。情報発信を継続していくためにも、サポートをいただけると非常に嬉しいです。