1枚しかラベルデータがなくても学習できるFixMatch

※有料設定してますが、投げ銭用なので全部無料でみれます。
この論文は2020/1/21に投稿された半教師あり学習手法FixMatch[1]に関する解説です。この論文を短くまとめると下記のようになります。
ラベルなし画像に弱い変換を与えた画像のone-hot擬似ラベルと強い変換を与えた画像の予測ラベルにクロスエントロピーをかける半教師あり学習手法FixMatchを提案。ラベルありデータがかなり少量でも学習可能で、1データしかなくてもある程度精度が出る。
半教師あり学習と問題設定
半教師あり学習とは、少数のラベルありデータと多数のラベルなしデータで学習を行う学習方法です。教師あり学習とは異なり、全てのデータでラベルを用意しなくてよい点が最大の利点です。

FixMatch等の半教師あり学習の論文では、CIFAR-10など全てのデータにラベルがついているデータセットを使って半教師あり学習用のデータセットを作って評価することが一般的のようです。学習データの一部をそのまま使い、残りの学習データはラベルなしデータとして扱うことで半教師ありの枠組みで評価できるようにします。
例えば、CIFAR-10では全ての画像にラベルがついていますが、ある数だけ(画像,ラベル)両方を使用し、それ以外の(画像,ラベル)のペアデータに関してはラベルを捨ててラベルなしデータとして扱います。その際、テストデータではラベルを削除しないことに注意してください。
擬似ラベルとconsistency regularization
半教師あり学習では、ラベルなしデータからどう教師信号を得るかがポイントです。モデルを使って、予測値を仮のラベルとすることが一般的なようで、予測値を分布を保ったまま少し分布を極端にする”Sharpening”手法と、一番予測の確信度が高いラベルのみ信じてone-hotにする”擬似ラベル(pseudo label)”手法の2つがあります。

しかし、そのまま学習中の予測値を使うと元々ラベルがないデータであるので、信頼して良いかわかりません。そこで、データに変換を加えても、予測値が変化しないように制約をかけることによって、仮ラベルの精度をより高めるconsistency regularizationという方法があります。下の図はconsistency regularizationの例です。元の画像に別の変換をかけたものの予測値の差分を目的関数に組み込むことによって、ラベルなしデータの仮ラベルの予測値に信頼性を持たせています。

Key Insightと手法
FixMatchでは、以下の2つがポイントです。
1. 弱い変換を加えた画像と、強い変換を与えた画像で
consistency regularizationを使う
2. 確信度によって学習させるラベルなしデータを選別する
FixMatchでは、まず左右反転等の弱い変換を与えたラベルなし画像を学習中のモデルで予測値を算出します。そして、一番確信度が高いラベルの予測値がある閾値τを超えたもののみを、そのラベルを1,そのラベル以外を0にするone-hot形式のラベルにし、それを擬似ラベル(pseudo-label)として扱います。
次に同じ画像に対してコントラスト変換等を複数組み合わせる等の強い変換をかけた画像を、同じモデルで予測値を出します。最後にその予測値と、先ほどの擬似ラベルを正解としてCross Entropy(図中のH)をかけることで、consistency regularizationの制約をかけます。

強い変換をかける際には、RandAugment[2]とCTAugment[3]の2つのうちどちらかを用いています。両者とも最適なデータ拡張手法を探索するAutoAugment[4]の後継研究です。
RandAugmentは、ランダムに変換方法を選ぶ手法で変換の大きさ(回転なら角度)をグリッドサーチで最適なポイントを探索する手法でAutoAugmentのようにデータ変換のpolicyを必要としません。
CTAugmentは、ランダムに選ばれた2つの変換手法を使います。AutoAugmentのように変換の大きさを確率的にサンプリングしますが、こちらはオンラインで学習できる手法です。
そして、擬似ラベルのconsistency regularizationの項と、通常の分類問題と同様の教師ありデータcross entropyの2つを目的関数に組み込んで目的関数とし、それを最適化します。全体のアルゴリズムは以下の通りです。ミニバッチ中のラベルありデータとラベルなしデータの比率はパラメーターμ、擬似ラベルの閾値はτによってそれぞれ制御されています。
Image for post

結果
既存手法との比較
まず、既存手法との比較結果をみてみます。データセット名の下に記載がある教師ラベル数は全クラスの合計を表しています。よって,CIFAR10で40 labelsは、10クラスで各4データしか教師データを使っていないという水準になります。各データセットの1番左の水準は各クラス4データでの比較ですが、それを実施して他の手法比較したのもこの論文の貢献のようです。
FixMatchは全ての水準で既存手法と同等かそれ以上の成果を上げています。CTAと書いてあるのが強い変換にCTAugmentを使用したもの、RAと書いてあるのがRandomAugmentを使用したものです。

1枚の画像だけで学習させる
半教師あり学習の極限として、1ラベル当たり1枚しかラベルありデータを使わない状態を考えてみます。
著者たちはCIFAR-10を使ってそのようなデータセットを4つ作り、4回学習して検証しています。結果、精度が48.58~85.32% の範囲でばらつき、中央値が64.28%という結果になりました。データセット間の精度差をみてみると、1つ目のデータセットでは精度が61~67%, 2つ目のデータセットで68〜75%とばらついていました。
何故このようなばらつきが出てくるかの仮説として、データセットとして使う1枚の画像の質が大きく関係してくるのではないかと著者たちは仮説を立てています。仮説を検証するために、距離学習の枠組み[6]を使い、そのクラスを最も代表するデータから最も代表しないデータの順に8グループに分け、そのグループ内でデータセットを作ったときの精度を検証しています。
結果、最も代表するグループでは中央値78%(最高84%), 中位のものでは65%, 外れ値では10%となり、データセットの質が大きく影響することがわかります。 下の図を見てもらうと、確かに一番下の行のデータしかラベルデータとして与えられないと、全体の傾向を捉えれることができずに学習が失敗する、というのもわかる気がします。

ハイパーパラメータ変動に対する精度変化
ここでは、ハイパーパラメータを変えた際の精度変化を見てみます。
まず、目的関数のラベルなしデータ項の係数μ(ミニバッチ中のラベルなしデータとラベルありデータの比)を変化させた時の精度変化を見てみます。基本的にμが大きいほど(ラベルなしデータの比率が大きいほど)デフォルトのハイパーパラメータをつかったFixMatchの精度(赤いライン)に近づいていることがわかります。また、バッチサイズの増大と共に学習率を線形に増加させていく手法をとると、特にラベルなしデータの比が少ないときに効果を発揮していることがわかります。


次に、ラベルなしデータを擬似ラベルとして使うかどうかを決める閾値τと精度変化です。基本的に大きな閾値を使った方がよいことがわかります。確信度が低い擬似ラベルまで使うと教師データのノイズが大きくなってしまうため、確信度が高い擬似ラベルのみ学習した方が良いということが、直感的にも理解できます。

最後に温度項を使って予測値を先鋭化したものをラベルとして扱ってconsistency regularizationを取る手法(Sharpening)をone-hot形式の擬似ラベルの代替として使用した場合の検証結果です。Sharpeningは先行研究のMixMatch[5]等で用いられている手法です、温度項Tが0だと通常のSoftmax分布になり、T→0の極限で擬似ラベルのようなone-hotになります。Tを調整することで、softmaxの分布を”鋭く”する効果があります。
FixMatchにおいて、閾値τを使わない(τ=0)の時は、温度項が小さい、つまり分布が鋭い方が精度が出ていますが、τ=0.8,0.95のときは傾向がはっきりしません。著者たちはSharpeningを使って精度を上げるためには、さらなるハイパーパラメーターチューニングが必要そうだと述べています。
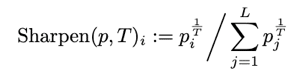

まとめ
この記事では、1ラベルでも学習が可能な半教師あり学習手法FixMatchを紹介しました。半教師あり学習は、高コストなラベリングを始める前に使える手法であるため、プロジェクトがうまくいきそうかを確かめるPoC(Proof of Concept)で使う手法として最適です。1ラベルでPoCを始めるというのは中々ないとは思いますが、数十ラベル程度で始めることは十分に考えられるので、プロジェクトの難度を確かめるためにこのような手法を活用するのは、機械学習の社会実装において、良い一歩かと思っています。
Twitter , 一言論文紹介とかしてます。
https://twitter.com/AkiraTOSEI
Reference
1. Kihyuk Sohn, David Berthelot, Chun-Liang Li, Zizhao Zhang, Nicholas Carlini, Ekin D. Cubuk, Alex Kurakin, Han Zhang, Colin Raffel. FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence. arXiv : 2001.07685
2. Ekin D. Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V. Le. Randaugment: Practical automated data augmen- tation with a reduced search space. arXiv preprint arXiv:1909.13719, 2019
3. DavidBerthelot,NicholasCarlini,EkinD.Cubuk,AlexKu- rakin, Kihyuk Sohn, Han Zhang, and Colin Raffel. Remix- match: Semi-supervised learning with distribution matching and augmentation anchoring.
4. Ekin D. Cubuk, Barret Zoph, Dandelion Mane, Vijay Va- sudevan, and Quoc V. Le. Autoaugment: Learning augmen- tation strategies from data. In The IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR)
5. David Berthelot, Nicholas Carlini, Ian Goodfellow, Nicolas Papernot, Avital
Oliver, and Colin A Raffel. Mixmatch: A holistic approach to semi-supervised learning. In Advances in Neural Information Processing Systems 32. 2019
6. Nicholas Carlini, Ulfar Erlingsson, and Nicolas Papernot. Distribution density, tails, and outliers in machine learning: Metrics and applications. arXiv preprint arXiv:1910.13427, 201
記事は以上です。ここから下は有料設定になっていますが、特に何もありません。調査や論文読みには労力がかかっていますので、この記事が気に入って投げ銭しても良いという方がいましたら、投げ銭をして頂けると嬉しいです。
ここから先は

Akira's ML news & 論文解説
※有料設定してますが投げ銭用です。無料で全て読めます。 機械学習系の情報を週刊で投稿するAkira's ML newsの他に、その中で特に…
記事を書くために、多くの調査や論文の読み込みを行っております。情報発信を継続していくためにも、サポートをいただけると非常に嬉しいです。