
Computer Vision x Trasformerの最近の動向と見解

この記事について
この記事では、Vision Transformer[1]登場以降のTransformer x Computer Visionの研究で、興味深い研究や洞察について述べていきます。この記事のテーマは以下の4つです。
• Transformerの急速な拡大と、その理由
• TransformerとCNNの視野や挙動の違い
• TransformerにSelf-Attentionは必須なのか?
• Vision Transformerの弱点と改善の方向性
また、この記事のまとめとしての私の見解は、以下の通りです。
1. Vison Transformer以来、Transformerはその適用範囲を急速に拡大した。その理由として、色々なデータに適用できること、異なるモーダル間で相関を取りやすいことがあると個人的に考えている。
2. TransformerとCNNの大きな違いとして視野の広さが挙げられる。それに起因してか、TransformerはAdversaial PatchのパターンがCNNと異なったり、テクスチャの変化に対してCNNより頑健であるという性質がある。
3. 最近の研究によると、TransformerにおいてSelf-Attentionは必須ではないかもしれない。個人的な見解だが、エンコーダーブロック内に大域情報を扱う部分と局所的に伝播させる部分2つがあることが重要に思える。
4. Vision Transformerはメモリが多く必要であること、データが大量に必要であることが弱点だが、急速に改善が進みつつある。
TransformerとVision Transformer
Transformer
まず、Vision Transformerに使われているTransformer Encoderの解説をします。Transformer[2]は“Attention Is All You Need”という論文で提案されたモデルで、LSTM・CNNを愛用していた人たちに対する挑発的なタイトルでも話題になりました。CNNでもLSTMでもない dot product Attentionという機構で、それを積み重ねたモデル(Transformer)で既存手法を大きく上回る成果を上げています。

[2]より引用。Transformerモデルの概観
Transformerで使われる(dot-product) Attentionでは、Query, Key, Valueの3つの変数を使います。端的にいえば、Query単語とKey単語を関連性(Attention Weight)を計算し、それぞれのKeyに紐づくValueをかけるという仕組みです。

Self Attentionの概念図
それをAttention Headを複数用いた(全結合でいうと”隠れ層の数”を増やした)Multi-Head Attentionは以下のように定義されます。上図の(Sigle Head) AttentionはQ,Kをそのまま使っていましたがMulti-Head Attentionでは、各Headに専用の射影行列W_i^Q, W_i^K, W_i^V がついており、それで射影した特徴量を用いてAttentionをかけます。

Multi-Head Self-Attentionの概念図
このdot product Attentionで使うQ,K,Vを同じデータからもってくるとSelf-Attentionと呼ばれます。TransformerのEncoder部分や、Decoder部分の最初のAttentionがそれにあたります。Decoder部分の上の方はQueryをEncoderから、K,VをDecoderから持ってきているのでSelf-Attentionではありません。
実際に適用したイメージを図で描くと以下の図にようになります。この図は、makingという単語をqueryとしてそれぞれのkey単語に対するAttention Weightを算出したものを可視化したものになっています。TransformerではMulti-Head Attentionを用いて後ろの層に伝播させており、それぞれのヘッドは異なった依存関係を学習しています。下図のkeyの単語に複数の着色がされていうますが、それぞれのヘッドのAttention Weightを表したものになっています。
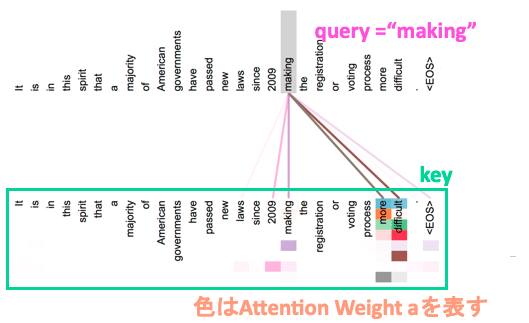
[2]より引用。TransformerのSelf-Attentionの重み
Vision Transformer
Vision Transformer[1]は、Transformerを画像分類タスクに適用したモデルで、2020年10月に提案されました。中身はオリジナルのトランスフォーマーとほとんど同じですが、自然言語処理と同じように画像を扱えるようにする工夫をしています。

まず、Vision Transformerでは、画像を16x16サイズのN個のパッチにわけます。パッチ自体は三次元のデータなので、言語(2次元)を扱うTransformerでは直接扱えません。そこで、Flattenした後に線形射影し、2次元のデータに変換します。そうすることで、各パッチをtoken(単語のようなもの)として扱え、Transformerに入力することができます。
また、Vision Transformerでは事前学習→Fine-tuneの戦略をとります。Vision TransformerはJFT-300Mという3億もの画像データを含むデータセットで事前学習をさせ、ImageNetなどの下流タスクでfine-tuningをさせています。Vision Transformerは、純粋なTransformer系のモデルとして初めてImageNetでSotA性能を獲得しました。これをきっかけに、Transformer x Computer Visionの研究が大きく増えました。
Vision Transformerはなぜ高精度なのか
Transformer x Computer Visionの研究は以前からあったのですが、ImageNetでSotA性能を獲得できませんでした。著者等はこの理由を、モデルのもつ帰納バイアスとデータ数の観点から解釈しています。帰納バイアスとは、モデルがもっているデータの仮定のことです。例えば、CNNは3x3のカーネルなどでデータを処理していきますが、これは「データの情報は局所的に集約されている」というデータの仮定を前提にした処理です。RNNでは、現在の時刻のデータと前の時刻のデータは大きく相関がありますが、前の前の時刻のデータとは、前の時刻のデータを介した相関しか持っていません。これも、「データは直前の時刻と大きく相関をもっている」というデータの仮定を前提にした処理です。一方、Self-Attentionは各データの相関をとっているだけなので、CNNやRNNと比較すると比較的相関は低いといえます。

(左)CNN。局所的に情報が集約されているという強い帰納バイアスが存在。(中央)RNN。1つ前の時刻と強い相関があるという強い帰納バイアスが存在(右)Self-Attention。全特徴量同士で相関をとっているだけなので比較的帰納バイアスが弱い
著者等は、「データが少ない状況においては、強い帰納バイアスをもつモデルはデータの仮定をもっているため、弱い帰納バイアスをもつモデルより強い。一方、データが多いと逆にその仮定が邪魔になるため、データが多い状況では帰納バイアスが弱いモデルの方が強くなる」という解釈をしています。
その解釈を補強する結果が以下の図に示されています。Vision TransformerとCNNを事前学習のデータセットのサイズ別に比較していますが、Transformer(弱い帰納バイアス)は、データが少ない状況では精度が低いですが、データが多くなるにつれ精度が上がり、JFT-300Mで事前学習させた場合では、CNN(強い帰納バイアスのモデル)を凌駕する結果となっています。

データ数とCNN, Transformerの精度
Transformer x Computer Visionの動向
ここからは、Transformer x Computer Visionの研究動向や、最近の研究でわかってきたVision Transformer系の興味深い挙動などを紹介していきます。テーマは下記4つです。私の個人的な見解を含んでいることに注意してください。
1. Transformerの適用分野の拡大とその理由
2. TransformerとCNNの視野や挙動の違い
3. TransformerにSelf-Attentionは必須なのか?
4. Vision Transformerの弱点と改善の方向性
1. Transformerの適用分野の急速な拡大とその理由
Vision Transformer登場以降、Computer Visionを中心に、さまざまなデータやタスクにTransformerを適用したという研究が急速に増えてきました。Vision Transformerは画像分類タスクでしたが、Semantic Segmentationや物体検知に適用したSwin Transformer[13]、深度推定に適用したDPT[17]などがあります。違うデータ形式としては、点群データに適用したPoint Transformer[18]、画像の他に音声・動画・点群に適用できるPerceiver[19]などがあります。もともと使われていた自然言語分野とComputer Visionタスクを組み合わせたVision & Languages分野でも適用が盛んで、Computer Visionなどの複数のタスクを同時に実行できるUniTなどがあります。
このように、さまざまな分野で広くTransformerが使われてきています。
なぜ、このようにTransformerがつかわれているんでしょうか。ここからは私見を含みますが、以下の理由があると思われます。
①自然言語処理だけなく画像系に適用できることがわかったので、大きく広がった
②データによってネットワークを変える必要がなく、便利。
③異なるデータ間で相関をとりやすい
①自然言語処理だけなく画像系に適用できることがわかったので、大きく広がった
元々自然言語処理分野で使われ、音声でもTransformer Transducer[20]が成果を上げるなど、自然言語処理と音声では効果が効果が確認されていましたが、Vision Transformerのおかげで画像分野でもCNN以上の性能があることがわかりました。音声、自然言語処理だけでも研究分野が広いです。そこに同じく研究分野が広いComputer Visioが加わったうえ、音声+画像、Vision & Languagesのような複合分野に使えるようになったので、急速に適用範囲が広がったと考えられます。
②データによってネットワークを変える必要がなく、便利。
従来は画像→CNN、自然言語→Tranformerのようにネットワークを分ける必要がありました。しかし、全てTransformerで処理できるようになったので、活用しやすいということも挙げられるかもしれません。Perceiver[19]などが代表例です。

10万以上の特徴量数をもつ高次元入力に対応でき、動画+音声、画像、点群など多くのデータ形式に対応できるTransformerモデルであるPrecieverを提案。潜在空間からQを取ってくることで、計算量を削減する。画像、点群で高い性能を発揮しただけでなく動画+音声ではSotA性能を獲得。[19]から画像を引用した。
③異なるデータ間で相関をとりやすい
画像や言語など全てをTokenとして処理できるので、画像のブランチネットワーク、自然言語のブランチネットワークをそれぞれ持つ必要がないことも理由になるかもしれません。低い抽象度のまま、Self-Attentionで異なるモーダルの相関をとることができます。代表例はViLT[21], VATT[22], VL-T5[23]などです。

異なるモーダルのデータをtokenとして扱うことにより、異なるデータ間で相関が撮りやすい。(上)VL-T5[23], (下)VLiT[21]
2.TransformerとCNNの視野や挙動の違い
Computer VisionにおいてCNNと同等以上の性能を発揮するようになったTransformerですが、両者はどのような違いがあるのでしょうか。
まずは、視野の違いが挙げられます。CNNは、3x3や7x7サイズのカーネルが用いられるため、各層ではそれに応じた視野しか得られません。また、層を伝播するにしたがって視野や広がっていきますが、その広がり方は深さに対して線形増加です。
一方、Transformerは、Self-Attentionを使っているため、初期層から全体を見られる構造になっています。各パッチをtokenとして扱い、それら全ての相関をとって計算させるので、最初から大域的な特徴を学習させることが可能です。

画像サイズが32x32のデータに、CNN(kernel_size=3)とSelf-Attentionを適用した際の視野の大きさの違い。CNNは線形に視野が増加するのに対して、Self-Attention(Vision Transformer)は最初から全域の視野をもっている。
実際に、Vision Transformerで学習させたときの視野の広がりを示したのが以下の図です。大部分は線形的に視野を広げていく方向ですが、一部では初期層から大域的な情報を取得していることがわかります。

学習済みVision Transfomerの視野。[1]より画像を引用した
また、その視野の大きさに起因してか、TransformerはCNNより形状をベースに物体を判断しているという研究結果が発表されています。
CNNは形状よりもテクスチャを重視しているという研究結果[3]があり、そこでは従来の定説と異なり、CNNが形状よりもテクスチャを重視した分類を行なっているという主張しています。例えば、下記の図(c)において、人間は形状をもとに判断する傾向が強いため「猫」と判定しがちですが、CNNベースのモデルではテクスチャをベースに判断するため「インド象」と判断しています。

CNNは形状よりテクスチャで判断している。画像は[3]より引用。
それを定量的に表したのが下の図です。この図は形状を保持しつつテクスチャに対して摂動を加えた画像の分類精度を表しています。赤色が人間で、青系の点はCNNベースのモデルです。人間の判定はテクスチャの摂動に対して頑健であるのに対し、CNNでは大きく精度が落ちています。つまり、CNNの判定基準は、形状ではなくテクスチャに対して大きく依存しているということです。

CNNは形状よりテクスチャで判断しているという定量評価。形状を保持しつつテクスチャに対して摂動を加えた画像の、人間(赤)とCNNベースのモデル(青)の分類精度の比較。画像は[3]より引用。
では、それに関してTransformerはどうでしょうか?Transfomerのテクスチャ依存を上記と同様の実験で比較したのが下の図です。CNN系のモデルと比べると、Transformer系のモデル(ViT)は、比較的テクスチャの摂動に対して頑健であることがわかります[4]。これは、Transformerの視野が広いことと関係があるかもしれません。

TransformerはCNNよりテクスチャ依存が少ない。画像は[4]より引用。
他にも、視野の広さに起因しているかもしれない面白い性質があります。意図的に作り出したノイズを使ってモデルの判定を誤らせるAdversarial exampleという手法[5]がありますが、そのノイズにCNN系のモデルとTransformerに違いがあることがわかっています[6]。
犬の画像を誤判定させるノイズでは、CNN(ResNet)のノイズは高周波成分が多く、局所的な構造をもっています。それに多指定、Transformer(ViT)のノイズは比較的低周波成分が多く、大きな構造をもっています。これも視野の広さに起因しているかもしれません。(16x16サイズのパッチではっきり境界が見えているのが非常に面白いですね。)

Adversarial Exampleの例。意図的に作り出したノイズを加えることで、モデルにパンダの画像をgibbonと誤判定させている。画像は[5]より引用。

敵対的ノイズの比較。ViTのノイズは、比較的低周波成分が多く大きな構造をもっているのに対して、ResNetは高周波成分で構成されている。画像は[6]より引用。
3. TransformerにSelf-Attentionは必須なのか?
ViTはComputer Visionにおいて大きな成功を収めましたが、Self-Attentionよりも良い構造がないかを探索する研究も盛んです。例えば、MLP-Mixer[7]では、Self-Attentionを使わず、最も基本的な深層学習手法であるMulti-Layer Perceptron (MLP)を使って、Vision Transformerと同等程度の成果をあげています。Vision Transformerと同様、JFT-300Mのような巨大データセットでの事前学習は必要ですが、Self-Attentionのような複雑な機構を使わずに高い成果をあげることができます。
基本的な構造としては、パッチ横断で情報を処理するMLP1と、パッチごとに情報を処理するMLP2を含むブロックをMixer Layerとし、それをTransformer Encoderの代わりに積み重ねる構造をとっています。ViTと同様に画像をパッチ分割し、それを2次元データ射影したデータを扱います。ViTのTranformerをMLPに入れ替えたような手法です。

MLP-Mixerの構造。パッチ横断で情報を処理するMLP1と、パッチごとに情報を処理するMLP2を含むブロックをMixer Layerとし、それを積み重ねる。画像は[7]より引用。

MLP-Mixer、ViT, Big Transfer(BiT, CNNベース)の比較。ViTと同様、データが少ない状態ではCNNに劣るが、データが多いとCNNを超える。画像は[7]より引用。
それに影響をうけて、Self-Attentionは必須な要素ではないと主張する論文[8]も登場しました。その論文で提案されているgMLPでも、MLP-Mixerと同様にMLPのみを用いた構造を提案しています。Squeeze-and-Excitationのような構造をもっており、こちらもパッチ方向の情報を処理する部分と空間方向に情報を処理する部分両方をもっています。
JFT-300Mのような超巨大データセットを使わずとも、ImageNetだけの学習でEfficientNet程度の精度を出しています。また、computer vision系タスクだけでなく、自然言語処理分野でもBERTと同等程度の精度を出していることもポイントです。

gMLPの構造。channel方向の情報を処理する機構と空間方向に情報を処理する機構にわかれています。画像は[8]より引用。


gMLPの結果。画像に関しては、ViTはJFT-300MがないとCNNを越えられなかったが、gMLPはImageNetだけでEfficientNetと同等の結果を出している。また、自然言語処理分野でもBERTと同等程度の結果を出している。画像は[8]より引用。
全域の情報をとれるならば、学習パラメーターを全くもたない機構でSelf-Attentionを代替してもよいというさらに過激な主張をしている研究もあります。自然言語処理の分野の研究ですが、FNet[9]では、Self-Attentionをフーリエ変換で代替しています。フーリエ変換は、基底を変えているだけなので学習も何もしておらず、また、フーリエ変換前後の特徴量を足し合わせるという物理的には解釈が難しい構造をしているのですが、そのような構造でもそこそこの結果を出しています。この論文では、Token同士の情報をMixできればよいという主張をしており、フーリエ変換の他にもランダムな行列(パラメーターは固定)をSelf-Attentionの代わりに使ったネットワークで実験も行なっています。

FNetの構造。TransformerのSelfAttentionの部分をフーリエ変換で代替している。画像は[9]より引用
以上みてきた、MLP-Mixer, gMLP, FNetのようにSelf-Attentionを使わずとも成果を上げるネットワークが近年研究されています。これらの3つの機構は大域的な情報を処理する機構(ViTのSelf-Attention, MLP-MixerのMLP1、FNetのフーリエ変換)と局所的に伝播させる機構(ViTやFNetのFeed Foward、MLP-MixerのMLP2 )をもっています。
個人的な見解も混じりますが、FNetの主張のようにtoken(画像でいうとパッチ)間の情報を混ぜることだけでなく、大局的な情報を考慮した上で局所的に伝播させる、というブロック構造をもつことが、大事なのかもしれません。
4.Vision Transformerの弱点と改善の方向性
Vision Transformerでは、CNNを超えるという素晴らしい成果をあげましたが、大きく2つの弱点があります。しかし、改善が急速に進んでおり、これらの弱点を克服しつつあります。
1. 帰納バイアスが弱いため、良い精度を得るためにImageNet(130万データセット)より大きなJFT-300M(3億データセット)を必要とする
2. Self-Attentionの性質上、画像の辺の長さの4乗のメモリサイズを必要とする
1.帰納バイアスが弱いため、良い精度を得るためにImageNet(130万データセット)より大きなJFT-300M(3億データセット)を必要とする
Vision Transformerは帰納バイアスが弱いからこそCNNを超えることができましたが、裏を返せば帰納バイアスの弱さを活かせる程度のデータ量がないと精度が落ちます。具体的には、3億のデータセットがないとCNNベースのモデルを超えることができていません。これを克服するために色々な改善手法が提案されています。
CNNを利用することで、必要データ量を削減する試みがあります。DeiT[10]では、知識蒸留の枠組みを用いて、CNNを教師モデルとし、Transformerモデルに知識を与えています。これにより、ImageNetだけを用いても、ViTだけでなくEffcientNetを超える結果を出しています。また、蒸留によって判断の傾向が大きくCNNに寄ってきたとも報告されています。

DeiTで行っている知識蒸留の概念図(左)とCNNを教師モデルとした知識蒸留を行なったViTであるDeiTの結果(右)。画像は[10]より引用
また、Vision Transformerは16x16サイズのパッチを線形射影するという非常に単純な方法で局所情報を扱っているため、より局所情報に強いCNNをそこに使うという研究もあります。

(左)ViTはパッチ化したものを埋め込み表現としてTransformerに入れるが、CNNによる畳み込みを使って抽象化した埋め込み表現を使う。(右)CNNをTransformerの内部に入れ込むことで、局所特徴量取得に強くさせる。画像は[11],[12]より引用し、注釈をつけた
2. Self-Attentionの性質上、画像の辺の長さの4乗のメモリサイズを必要とする
Self-Attentionは全パッチ同士の相関を計算させるため、辺の長さの4乗に比例するメモリサイズを必要とします。そのため、高解像度画像を扱いずらいです。しかし、CNNのように、初期層では高解像度画像を扱い、深くなるにつれて徐々に解像度を下げていく階層的構造をとることで、この問題に対処した研究があります。例えば、PVT[14]ではCNNのような高解像度→低解像度の階層構造をとっています。Swin[13]では、階層構造をとるだけでなく、Self-Attentionの視野を狭めることによって、パッチサイズを小さくし、よりきめ細かい情報を取得することを可能にしています。
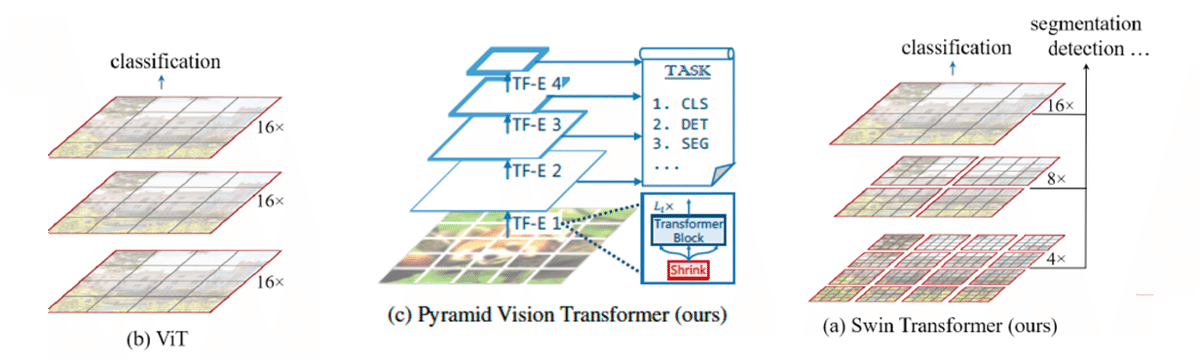
(左)ViT。解像度が固定、かつ、小さい。(中央)PVT。解像度を徐々に下げることで、最初は高解像度情報を扱える。(右)Swin Tranformer。全域のAttentionを使わず、CNNのように徐々に視野を広げることで、高解像度を扱う。画像は[13], [14]より引用した。
その他の改善
CNNと関連した改善だけでなく、Transformer独自の改善も色々と提案されています。例えば、T2Tモジュール[15]では、画像の埋め込みを、重複を許して周りのパッチ(token)と混ぜ合わせることを提案しています。これは、ViTがただ単に画素をパッチ化しているのに対し、周辺の情報を考慮した埋め込みをする工夫です。Swin Transformer[13]では、全域的なAttentionをとるViTと異なり局所的なAttentionを用いていますが、そのAttentionをとるグループを層ごとに変化させながら伝播させ、より周辺の情報を取得させるような工夫をしています。
また、ViTでは深くなるに従い、同じようなAttention Mapが生成されてしまうという問題があります[16]。"Towards Deeper Vision Transformer"では、Head 間でのAttentionは多様性が保たれているという観点に着目し、異なるヘッドのAttentionマップを混ぜるパラメーターを導入することにより、深層化してもAttention Mapの多様性を保つことに成功しています。

(左)ViTにおける画像のtoken化(埋め込み)が単純すぎると考え、重複を許して周りのtokenを混ぜ合わせて再token化するT2Tモジュールを提案(右上)全域Attentionを使うViTと異なり、赤枠内で局所Attentionをとるが、層毎にAttentionをとるグループを変えながら伝播させる(右下)異なるHeadのAttentionを混ぜる学習パラメータの導入により、Attentionの多様性を向上させる。似たAttentionの生成を防いで深層化で精度を向上させる
Vision Transformerでは、「データが多く必要」「必要メモリサイズが大きい」などの問題を抱えていましたが、ここ数ヶ月で多くの改善提案がされています。まだ実用面ではCNNが主流ですが、実用面でもCNNにとって代わる日もそう遠くはないかもしれません。
まとめ
この記事では、Vision Transformer登場以降のTransformer x Computer Visionの研究で、興味深い研究や洞察について述べてました。
この記事のまとめとしては、以下の通りです。これからもTransformerは発展していくと思われているので、将来どのような研究が行われるか非常に楽しみです。
1. Vison Transformer以来、Transformerはその適用範囲を急速に拡大した。その理由として、色々なデータに適用できること、異なるモーダル間で相関を取りやすいことがあると個人的に考えている。
2. TransformerとCNNの大きな違いとして視野の広さが挙げられる。それに起因してか、TransformerはAdversaial PatchのパターンがCNNと異なったり、テクスチャの変化に対してCNNより頑健であるという性質がある。
3. 最近の研究によると、TransformerにおいてSelf-Attentionは必須ではないかもしれない。個人的な見解だが、エンコーダーブロック内に大域情報を扱う部分と局所的に伝播させる部分2つがあることが重要に思える。
4. Vision Transformerはメモリが多く必要であること、データが大量に必要であることが弱点だが、急速に改善が進みつつある。
宣伝
日々Twitterで最新の論文の一言紹介を行っています。また、週次で機械学習の情報をお届けするニュースレターを始めました。是非、フォローや登録をお願いします。
ニュースレター
https://t.co/sdCxJeHv45
— akira (@AkiraTOSEI) July 6, 2021
クラス間にデータ数の偏りがあるLong-tailedデータにおけるマルチラベル学習において、データのバランスをとった/とらないデータをそれぞれ入力する2つのネットワークで一貫性を保たせるように学習する手法を提案。従来手法を大きく凌駕する結果。 pic.twitter.com/egUCDBAcuB
Reference
1. Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale Alexey. arXiv(2019)
2. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. Attention Is All You Need. arXiv(2017)
3. Robert Geirhos, Patricia Rubisch, Claudio Michaelis, Matthias Bethge, Felix A. Wichmann, Wieland Brendel. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. arXiv(2018)
4. Shikhar Tuli, Ishita Dasgupta, Erin Grant, Thomas L. Griffiths. Are Convolutional Neural Networks or Transformers more like human vision? arXiv(2021)
5. Ian J. Goodfellow, Jonathon Shlens, Christian Szegedy. Explaining and Harnessing Adversarial Examples. arXiv(2021)
6. Srinadh Bhojanapalli, Ayan Chakrabarti, Daniel Glasner, Daliang Li, Thomas Unterthiner, Andreas Veit. Understanding Robustness of Transformers for Image Classification. arXiv(2021)
7. Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, Alexey Dosovitskiy. MLP-Mixer: An all-MLP Architecture for Vision. arXiv(2021)
8. Hanxiao Liu, Zihang Dai, David R. So, Quoc V. Le. Pay Attention to MLPs. arXiv(2021)
9. James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon. FNet: Mixing Tokens with Fourier Transforms. arXiv(2021)
10. Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou. Training data-efficient image transformers & distillation through attention. arXiv(2020)
11. Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang. CvT: Introducing Convolutions to Vision Transformers. arXiv(2021)
12. Kun Yuan, Shaopeng Guo, Ziwei Liu, Aojun Zhou, Fengwei Yu, Wei Wu. Incorporating Convolution Designs into Visual Transformers. arXiv(2021)
13. Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv(2021)
14. Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. arXiv(2021)
15. Li Yuan, Yunpeng Chen, Tao Wang, Weihao Yu, Yujun Shi, Zihang Jiang, Francis EH Tay, Jiashi Feng, Shuicheng Yan. Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet. arXiv(2021).
16. Daquan Zhou, Bingyi Kang, Xiaojie Jin, Linjie Yang, Xiaochen Lian, Zihang Jiang, Qibin Hou, Jiashi Feng. DeepViT: Towards Deeper Vision Transformer. arXiv(2021)
17. René Ranftl, Alexey Bochkovskiy, Vladlen Koltun. Vision Transformers for Dense Prediction. arXiv(2021)
18. Hengshuang Zhao, Li Jiang, Jiaya Jia, Philip Torr, Vladlen Koltun. Point Transformer. arXiv(2020)
19. Andrew Jaegle, Felix Gimeno, Andrew Brock, Andrew Zisserman, Oriol Vinyals, Joao Carreira. Perceiver: General Perception with Iterative Attention. arXiv(2021)
20. Qian Zhang, Han Lu, Hasim Sak, Anshuman Tripathi, Erik McDermott, Stephen Koo, Shankar Kumar. Transformer Transducer: A Streamable Speech Recognition Model with Transformer Encoders and RNN-T Loss. arXiv(2021)
21. Wonjae Kim, Bokyung Son, Ildoo Kim. ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision. arXiv(2021)
22. Hassan Akbari, Linagzhe Yuan, Rui Qian, Wei-Hong Chuang, Shih-Fu Chang, Yin Cui, Boqing Gong. VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text. arXiv(2021)
23. Jaemin Cho, Jie Lei, Hao Tan, Mohit Bansal. Unifying Vision-and-Language Tasks via Text Generation. arXiv(2021)
記事を書くために、多くの調査や論文の読み込みを行っております。情報発信を継続していくためにも、サポートをいただけると非常に嬉しいです。