
OpenAIクリスマスプレゼント企画動画:第二弾解説「オリジナル強化学習編」

昨日に引き続き、本日日本時間2時から行われた12 Days of OpenAI二日目のライブストリーミングの解説をしていきます。ライブストリーミングは下記のYoutube録画で視聴する事ができます。
動画紹介(参加者と、この動画の概要)
この動画は、OpenAIの研究リーダーであるマークをはじめ、エンジニアのジョン・アラード、研究者のジュリー・W、そしてバークレー研究所の計算生物学者ジャスティン・リーが出演しています。彼らは、新たにリリースされた01モデルの進化とその応用について説明し、特に「強化ファインチューニング(Reinforcement Fine-Tuning)」という新しい技術に焦点を当てています。

動画の冒頭では、マークが01モデルの概要を紹介します。01は、従来のモデルよりも高度な推論能力を持ち、回答を返す前に「じっくり考える」ことが可能な最新の改良版です。この新モデルがChatGPTに統合され、APIとしても近々リリースされる予定であることを明かしています。また、01モデルをユーザーが自分のデータセットを使ってカスタマイズ可能にする強化ファインチューニングのプレビューを提供し、これが科学研究、医療、法務などさまざまな分野での応用が期待されていることを強調しました。
この動画の中心テーマである強化ファインチューニングは、従来の教師付きファインチューニングとは異なり、モデルに新しい推論方法を学習させることを可能にします。この技術は、OpenAIが内部で使用している強化学習アルゴリズムを活用しており、ユーザーが自分のユースケースに適した専門的なAIモデルを作成できる点が大きな特徴です。
参加者たちは、それぞれの専門知識を活かして、01モデルと強化ファインチューニングがどのように実際の課題に役立つかを解説しています。特にジャスティンは、自身の研究分野である希少遺伝病の解明にこの技術がどのように貢献するかを具体例を交えて説明し、視聴者にその可能性を示しました。この動画全体を通じて、技術的な進歩とその実社会での応用可能性について深く掘り下げられています。
OpenAI内部と同等の技術で強化学習がサポート可能に
OpenAIは、内部で最先端のモデルを開発する際に使用している強化学習技術を、外部ユーザーにも提供することを可能にしました。今回プレビューされた「強化ファインチューニング(Reinforcement Fine-Tuning)」は、ユーザーが自分のデータセットを活用してモデルをカスタマイズし、特定のユースケースに適応させることを可能にする画期的な技術です。この技術の導入により、従来の教師付きファインチューニングでは実現できなかったレベルの高度な推論能力をモデルに学ばせることができます。
特に注目すべきは、OpenAIが自社でトレーニングしてきたフロンティアモデル(例: GPT-4.0や01シリーズ)と同じ強化学習アルゴリズムを使用している点です。この技術を外部で利用できるようにしたことで、企業や研究者が自分たちの課題に特化したAIソリューションを開発できるようになりました。
この動画では、特に医療分野における応用例として、希少疾患に関する研究が紹介されました。ジャスティン・リーと彼の研究チームは、ドイツのシャリテ病院やピーター・ロビンソン研究室、モナークイニシアチブとの協力のもと、希少疾患に関する科学論文を分析し、疾患情報を抽出しました。このデータには、患者に現れた症状や、見られなかった症状、診断された疾患、そして問題の原因となった遺伝子情報が含まれています。このような詳細なデータを使用することで、モデルは疾患の原因を特定する能力を向上させることができます。
このような取り組みは、バイオインフォマティクス分野にとどまらず、法務、AI安全性、ヘルスケアなど、他の多くの分野でも応用が期待されています。強化ファインチューニングは、モデルが単なるパターンの記憶ではなく、データに基づいた深い推論能力を獲得する手助けをします。この技術の公開により、学術界や産業界におけるAIの可能性がさらに広がることは間違いありません。
強化学習のデモンストレーション
強化ファインチューニングを活用する手順を、スクリーンショットを参考にしながら説明します。このデモでは、モデルの作成からトレーニングデータのアップロード、そしてデータセットの具体例まで、プロセス全体を順を追って解説します。
1. 開発プラットフォームへの移動と新しいモデルの作成
最初に、OpenAIの開発プラットフォームに移動し、「新しいモデルの作成」を開始します。これまで教師付きファインチューニングを使用してきたユーザーも、今回は「強化ファインチューニング」を選択します。選択するベースモデルとして「01 Mini」を設定します。
2. トレーニングデータの準備とアップロード
次に、トレーニングデータセットを準備します。トレーニングデータセットは、JSONL形式のファイルで、各行にトレーニング例が記述されています。このデモでは、約1100の例が含まれるデータセットが使用されました。
「アップロード」ボタンをクリックし、トレーニングデータを開発プラットフォームにアップロードします。

3. 検証データセットの設定
トレーニングデータとは別に、検証データセットをアップロードします。このデータセットは、モデルのトレーニング成果を評価するために使用されます。検証データとトレーニングデータの間には、正解遺伝子が重複しないよう設計されており、モデルが単にデータを記憶するのではなく、一般化能力を学習することを保証します。

4. トレーニングデータの具体例
トレーニングデータの一例を確認します。このデータポイントには以下の3つの重要な要素が含まれています。
ケースレポート: 患者とその症状の詳細(例: 51歳女性、症状は甲状腺機能亢進症など)。
欠損している症状: 患者に現れていない症状のリスト。
指示(プロンプト): モデルにタスクを指示するテキスト(例: 症状リストに基づいて、可能性のある遺伝子を順位付けしてリスト化する)。
これらの情報が、モデルに推論能力を学習させる基盤となります。

5. モデルの出力確認
モデルにタスクを与えると、辞書形式の結果が生成されます。この辞書には、遺伝子の順位付けリスト、選択理由の説明が含まれます。例えば、以下のような出力が得られます:
理由(Reasoning): 「亜表皮結節、けいれん、皮質結節が、特定の遺伝子群に関連する疾患を示唆している」
遺伝子リスト: FOXC3を含む複数の遺伝子候補が順番にリストアップされる。
このような出力は、モデルがどのように考えたかを確認するための貴重な情報を提供します。

6. グレーダーの設定
グレーダーはモデルの出力を評価する基準で、スコアを返します。例えば、正解遺伝子がリストの1番目にあればスコアは1、2番目なら0.7というように評価されます。
「トレーニングを開始」ボタンを押し、ジョブが進行します。このジョブでは、数時間から数日かけてモデルがトレーニングされます。

7. グレーダーによるスコアリングプロセス
モデルの出力を評価するグレーダーを設定します。このグレーダーは、モデルの予測リストと正解を比較し、スコアを生成します。例えば、正解遺伝子がリストの2番目に挙げられている場合、スコアは0.7になります。順位が下がるほどスコアは減少し、正解が1番目に挙げられていればスコアは1となります。これにより、モデルの出力の質を具体的に評価することができます。


8. トレーニング開始
グレーダーの設定が完了したら、トレーニングジョブを開始します。この際、バッチサイズや学習率、エポック数といったハイパーパラメータをカスタマイズすることも可能ですが、デフォルト設定でも十分に高品質なトレーニングを実行できます。ジョブを開始すると、OpenAIの分散型トレーニングインフラを活用し、強化学習を用いたファインチューニングが進行します。
9. トレーニング結果の検証
トレーニングが完了したら、モデルの改善度を確認します。この例では、「検証データセット上でのスコア」が使用されました。トレーニングの進行に伴いスコアが上昇する様子がグラフで示されており、モデルが一般化能力を向上させたことがわかります。

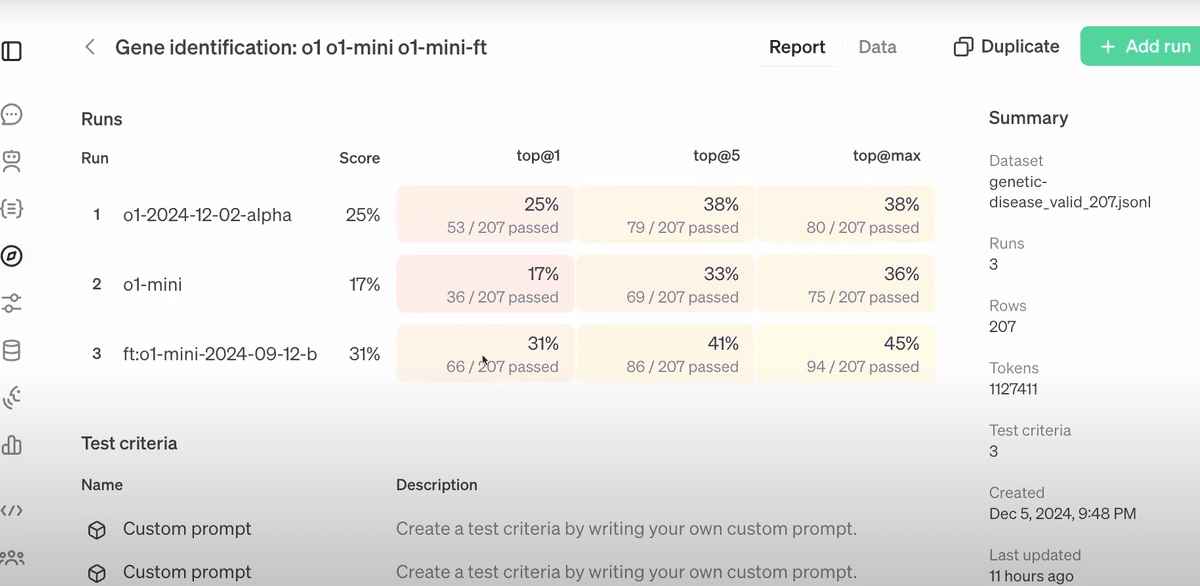
モデルの評価と比較
トレーニング済みのモデルを評価するために、「Top@1」「Top@5」「Top@Max」という3つの指標を用います。これらはそれぞれ、リストの最初、上位5つ、リスト全体の中に正解が含まれる割合を示しています。評価結果を他のモデルと比較したところ、ファインチューニングされた01 Miniモデルは、ベースラインのモデルよりも大幅に性能が向上していることが示されました。これにより、強化学習が有効であることが実証されました。
1: モデル評価結果の概要
この画像は、ファインチューニングしたモデル(ft:o1-mini)とベースラインモデル(o1、o1-mini)を比較した評価結果を示しています。表は「Top@1」「Top@5」「Top@Max」の3つの指標で性能を測定しています。ファインチューニングモデルが、各指標において他のモデルを上回っていることがわかります。この結果は、ファインチューニングによる性能向上の明確な証拠です。
2: モデル性能の視覚的比較
この折れ線グラフは、3つのモデルの各指標でのパフォーマンスを視覚的に比較しています。赤い線はベースラインのo1-miniモデルを示し、緑の線はo1モデル、点線の赤い線はファインチューニングされたo1-miniモデルを示します。ファインチューニングモデルが他のモデルよりも全体的に高いパフォーマンスを示していることが、視覚的に明確です。

3: 各モデルの応答データ詳細
この画像は、モデルが具体的なタスクに対して生成した出力データと、それに対する評価結果を表示しています。各行には、ユーザーからの指示(Prompt)、モデルの回答(Output)、およびその回答が正解だったかどうか(Passed)が記録されています。この詳細なデータは、ファインチューニングの効果をより深く理解するための貴重な情報を提供します。

余興:だじゃれ
昨日と同じように最後に、開発チームからのダジャレが披露されました:
「今日は何かジョークを用意していますか?」
「ええ、もちろんです。伝統になりつつありますが、今回はクリスマスをテーマにしたジョークをご用意しました。皆さんご存知の通り、ここサンフランシスコでは自動運転車が大人気です。実は、サンタもそれに挑戦しているんです。彼は自動運転のソリを作ろうとしているんですが、なぜかモデルが木を認識できなくて、ソリがあちこちで木に衝突しているそうなんです。」
「それはなぜでしょう?」
「Pine-tune(松=Pine を調整する)しなかったからです!」
今日のダジャレは昨日よりは簡単でした。Pineとfineを掛けていたのですね。