
ログ分析における異常検知の新手法「LogClass」をご紹介 (後編)

Airitech株式会社 DX2 AI・機械学習グループの青山です。
ログ分析における異常検知の新しい手法である「LogClass」について、「前編」では、「異常ログの識別と分類」について解説しました。
今回は「後編」として、「LogClassの設計」「LogClass異常検知の精度」について、解説していきます。
ログ分析における異常検知の新手法「LogClass」をご紹介 (前編)
6. LogClassの設計
前述の通り、ログはネットワークやサービスによって出力された半構造のテキストです。実世界のログを調査することにより以下のことがわかっています。
6-1. 異常ログの共通パターン
同じ異常カテゴリの異常ログには、共通のパターンがあります。具体的には、「重要」な単語の組み合わせが共通しています。この組み合わせを正確に得ることができれば、あるログがある異常カテゴリに属しているかどうかを簡単に判断することができます。異常カテゴリーに属していなければ、そのログは健全なログです。
6-2. 重要な単語を特定
上記のような「重要」な単語の組み合わせを得るためには、ログ中のどの単語が「重要」なのかを特定し、これらの単語に高い重みを割り当てる必要があります。ある単語がログに頻繁に現れる場合、それは「重要」な単語である可能性が高いです。
しかし、「場所」が異なるログに出現する場合は、冠詞(たとえば、「a」、「the」)、前置詞(たとえば、「in」、「on」)、接続詞(たとえば、「and」、「but」)である可能性が高く、「重要」な単語ではないと考えられます。
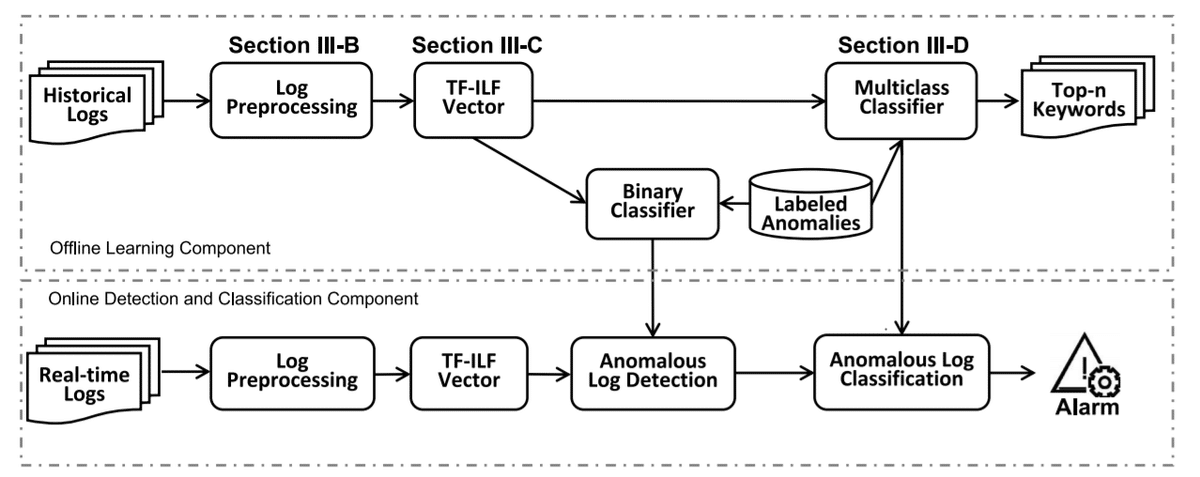
以上のことを念頭に、Fig.3のようにLogClassを設計します。
LogClassは、オフライン学習部位とオンライン識別・分類部位の2つの主要コンポーネントから構成されています。オフライン学習部位では、LogClassはまずログを前処理し、パラメータを設定します。(6-2-1) (6-2-2)
次に、LogClassはBag-of-Wordsモデルを使用して特徴量を作成し、TF-ILF法で重み付けを行います。(6-2-3)
最後に、LogClassは、PU学習ベースの二値分類とSVMベースの多クラス分類を学習します。同様に、オンライン識別・分類部位では、LogClassがリアルタイム・ログを前処理して特徴を抽出した後、LogClassは訓練された二値分類を使用してログが異常であるかどうかを判断し、異常である場合は多クラス分類を使用して異常カテゴリに分類します。(6-2-4) (6-2-5)
6-2-1.ログの前処理
一般的に、IPアドレスの削除などのドメイン知識を用いた単純なログの前処理は、ログ解析のパフォーマンスを向上させ、異常なログの識別や分類を向上させることができます。
6-2-2.単語のテキストワード、パラメータワードへの分類
テキストワードとは、ネットワークやサービス上で発生した事象を表す単語です。一方、パラメータワードとは、ログごとに異なる変数(IPアドレス、インターフェースID、デバイスIDなど)のことです。ログベースの異常検知・識別・分類の手法では、これらのパラメータワードからパターンを捉えることは非常に困難です。本手法ではこれらのパラメータワードを無視しています。

6-2-3.TF-ILF
LogClass において、ログはその単語のベクトルとして表現され、ベクトルの各要素の値は、単語の推定された重要度(重み)を表す。古典的な重み付け手法であるTF-IDFではく、ドメイン知識に基づいてログの単語を適切に重み付けする新しい手法であるTF-ILFをご紹介いたします。
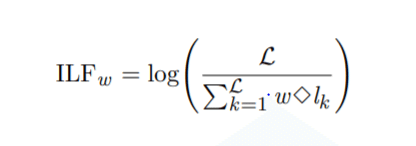
TF-IDFは、シンプルで効果的な重みモデルであり、単語の表現に最も広く使用されている重み付けスキームです。TFは用語の頻度を意味します。
IDF(inverse document frequency)は単語がどれだけの情報を提供しているか、すなわち、その単語がすべての文書で多く含まれているか、または稀であるかを示す指標です。
このモデルは、ある単語がより多くの文書(ここではログ)に現れるほど、その単語の重要性は低くなることを表します。

なぜ、TF-ILFはTF-IDFより優れているのでしょうか?
ある単語について、IDFはその単語が現れる異なるログの数を表し、ILFはその単語がログの中で現れる異なる場所の数を表します。学習過程において重要な単語とは、それを含む新しいログが追加されるとIDF値が小さくなり、ILF値は変化しない場合が多いです。
たとえば、 上の図のL1とL4はどちらも同じイベントで、新しいログが追加されたときに、重要なテキスト・ワードのIDFとILFの値がどのように変化するかを示しています。最初の段階では、すべてのログの最長の長さはL = 7であり(ログの前処理とパラメータ・ワードの絞り込み後)「Interface」という単語はL 1の最初の位置にしか現れません。
そのため、「Interface」のIDF値はlog( 3/1 )、ILF値はlog( 7/1 )となります。L 4が追加されると、最初の位置に「Interface」が現れることで、「Interface」という単語のIDF値は、log( 3/1 )よりも小さいIDF = log( 4/2)となりますが、ILF値は変化しません。L 1 と L 4 の同じフォーマットのログが増えれば、IDF の値はどんどん小さくなっていきます。
最終的に、TF-IDFは 「Interface」という重要な単語に非常に小さな重みを割り当ててしまいます。これは、この単語が(オペレータのドメイン知識に基づいた)異常なログの識別/分類において重要であるという事実と矛盾します。
逆に、「Interface」という単語のILF値は、(L1とL4の同じフォーマットの)新しいログが追加されても変化しません。したがって、TF-ILF は、常にこの単語に重要な重みを与えます。
6-2-4. 二値分類、多クラス分類
オフライン学習においては、特徴ベクトルを取得した後、PU学習モデルを適用し、部分的なラベル(すなわち、ラベルのない異常ログと健全なログ、およびラベルのある異常ログ)に基づいて、二値分類を学習します。
その後、異常なログを解釈可能な方法で異なるカテゴリに分類するために、多クラス分類を学習します。同様に、オンライン分類では、訓練された二値分類を用いて、リアルタイムでログが異常であるかどうかを判断します。
異常であれば、訓練された多クラス分類モデルを適用して、そのカテゴリを推測します。
6-2-5.PU学習
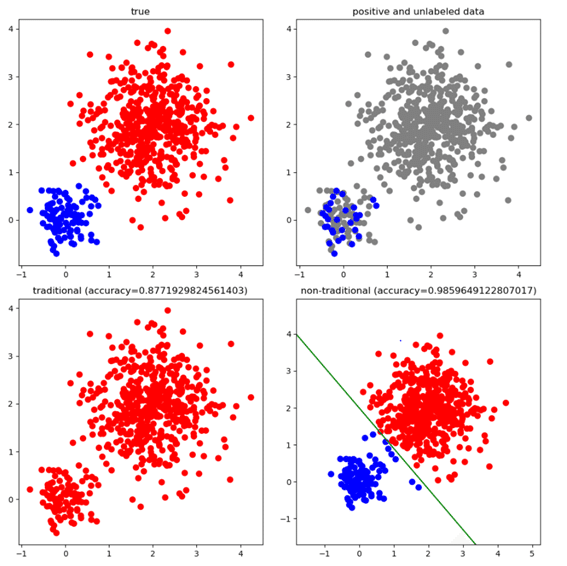
PU学習は、ラベル付きの例が正例からランダムに選択されるという仮定のもと、正例とラベルなしの例で学習し、正である確率を予測します。PU学習の有用性はラベル付けされている正例が一部あるだけで、全体の二値分類モデルをかなりの精度で表現できることです。
7. LogClass異常検知実験結果と精度
dataset F1-micro(accurancy)
hpc 0.99325
proxifier 0.99993
zookeeper 0.98951
bgl 0.97751
hdfs 0.99925
Apache 0.99999
hadoop 0.96223
kfold : 3
features: ['tfilf']
binary_classifier: pu_learning
multi_classifier: svm
dataset https://github.com/logpai/loghubこれらのデータセットを用いて、実際にLogClassで異常ログと正常ログの分類を行いました。F1-microスコアとは全体の予測に対してどの程度の精度で異常ログと正常ログが分類されているか示しています。上の結果からかなりの精度で分類できていることがわかります。
各ログデータは2,000行であるため、より多くのデータを用いればより正確な予測が可能となります。またこれらのデータセットは正確なラベル付けが行われているため、一般のログデータと比べて精度が高いと予想できます。
8. 複合モデルにおける分類精度
dataset F1-micro(accurancy)
| apach only | 1 |
| -------------------------------------- | -------- |
| apach + hadoop | 0.998501 |
| apach + hadoop + proxifier | 0.998498 |
| apach + hadoop + proxifier + zookeeper | 0.991004 |
| apach + hadoop + proxifier + zookeeper + hpc | 0.992492 |上の表はそれぞれのデータセット(各2000行)をすべて学習した複合モデルによる、Apacheデータの異常分類精度です。これにより、ほかのデータセットを取り込み、すべてのログの特徴を学習してもなお、Apache内の異常ログを認識する潜在概念を維持できていることが確認できました。
すなわち、新しいタイプのログが追加されても、与えられたログとラベル付けされた異常なログとの間の単語の組み合わせの類似性を自動的かつロバストに測定し、新しいタイプのログの課題に効率的に対応できることがわかります。
9. LogClassの特徴と有用性についてのまとめ
以上のことから、LogClassの特徴と有用性をまとめます。
9-1. PU学習フレームワークを用いて、一部の正例のみのログデータにも対処できる。
9-2. 与えられたログとラベル付けされた異常なログとの間の単語の組み合わせの類似性を自動的かつロバストに測定し、新しいタイプのログの課題に効率的に対応できる。
9-3. TF-ILFを用いることによって特徴ベクトル構築においてログの単語を適切に重み付けする。
参照
LogClass: Anomalous Log Identification and Classification With Partial Labels
Airitech(エアリテック)
Airitech株式会社は、最高のチームワークで、お客様の課題に最高の解決策をご提供いたします。
DXと業務改善に欠かせない「Celonis(セロニス)」の無料ウェビナーを開催しています。お申し込みはこちら