
ログ分析における異常検知の新手法「LogClass」をご紹介 (前編)

初めまして。Airitech株式会社 DX2 AI・機械学習グループの青山です。
今回は、ログ分析における異常検知の新しい手法である「LogClass」について、「前編」と「後編」の2回にわたりご紹介します。
1. はじめに
近年のインターネット、Webサービスの爆発的な増加に伴い、ネットワークやサービスの安定性はますます重要になっています。ネットワークやサービスの異常は、ユーザや企業の収益に重大な影響を与えるため、オペレータは継続的にログを監視する必要があります。
一般的に、オペレータはルールベースのアプローチを用いて個々のログの異常を識別・分類しており、通常は手作業で管理しています。しかし、ネットワークやサービスの大規模化・複雑化に伴い、ログの量は爆発的に増加しているため、ルールベースの手法は柔軟性に欠け、手間がかかるため効率的ではありません。
正確でタイムリーな異常の識別と分類は、オペレータが障害を迅速に認識し、その根本原因を突き止めるのに役立ちます。

2. 異常ログの識別と分類の課題
2-1. 手作業によるラベル付けが困難である
膨大な量のログを人の手でラベル付けを行うため、見逃しによる異常ログのラベル付け漏れや正常なはずのログに誤ってラベル付けしてしまうケースがたびたび発生します。
2-2. 新しいタイプのログの分類が困難
ネットワークやソフトウェア、ファームウェアはアップグレードを継続的に実施しており、これにより新しいタイプのログが生成されます。更新頻度が少ない正規表現では新しいタイプのログに対応しきれません。
2-3. 従来の単語ベクトルによる特徴量生成は不適切
文章から特徴ベクトルを構築する古典的な手法においてログ(文章)はその単語のベクトルとして表現されます。一般にベクトルの各要素は、単語の重要度(重み)の推定値を表します。
TF-IDFのような既存の単語重み付け手法は、頻繁に出現する単語は重要ではないと仮定していますが、この仮定はログでは常に正しいとは限りません。
上記の課題を解決するため、部分的なラベルに基づいて異常なログを識別し、分類するフレームワークであるLogClassが提案されました。
3. ログとはなにか
ログは、ネットワークやサービスの管理プロセスにおいて不可欠なものです。ログには、オペレータがネットワークやサービスの状態を監視するための詳細な実行時情報が記録されています。ログはネットワークおよびサービスによって「printf」された半構造化テキストです。
下図のTABLE1に、ログメッセージの4つの例を示します。表からわかるように、ログメッセージは通常、少なくとも4つのフィールドを含む構造を持っています。その中には、ログのSource、このメッセージがいつ生成されたかを示すTimestamp、大まかな特徴を表すMessage Type、このログが表現するイベントの詳細を表すDetailed Messageが含まれています。
Message Typeは、抽象的であるため、異常なログの識別・分類にあまり適していません。一方で、Detailed Messageは、ネットワークやサービスの実行時の状態を詳細に記述しているため、オペレータはこのフィールドに最も注意を払います。

4. ルールベースのアプローチ
一般的に、異常なログを自動的に識別・分類するためには、オペレータが異常なログのルールを手動で定義する必要があります。最も単純なルールは、"loss "や "lost "などを含むキーワードを照合することです。しかし、この方法では誤報が発生する可能性があります。
たとえば、あるネットワーク機器が他のネットワーク機器にPINGを送ろうとすると、「packet : sent = 5, received = 5, lost = 0 (0% loss)」といったログメッセージが生成されます。このログメッセージには「損失」という言葉が含まれていますが、異常ではありません。
このように分類におけるルール設定の一般的な方法は、ドメイン知識に基づいて異常なログとマッチする正規表現を手動で設定することですが、以下のような欠点があります。
4-1. 柔軟性に欠ける
正規表現は異常なログに対して厳密すぎます。つまり、ログが正確な形式ではない場合、たとえその違いが些細な単語、空白、記号であっても、異常なログにマッチしません。
また、同じ異常カテゴリに属する異常ログであっても、ネットワーク機器やサービスの種類が異なれば、多少の違いが生じる可能性があります。より具体的には、2つの異なるタイプのデバイスによって生成された異常ログは、意味においては非常に似ていますが、構文においては異なります。
しかし、正規表現ではこのようなパターンを捉えることはできません。そのため、ルールベースの手法は、異常ログの識別や分類に柔軟性や汎用性がありません。
4-2. 手間がかかる
すべての正規表現は、オペレータが手動で設定・更新しています。1日に数千件という大量の新しいタイプの異常ログが生成され、オペレータはこれらのログに対して正規表現を設定しなければならないため、正規表現を手動で設定するには膨大な作業が必要となります。
5. ログの識別と分類
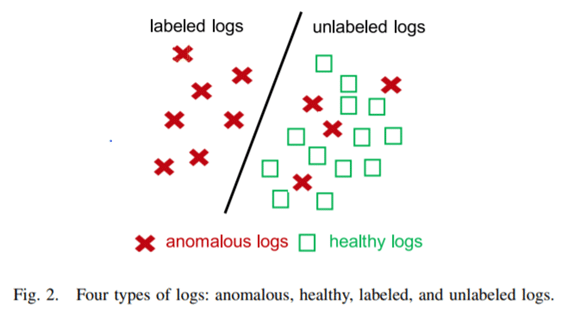
本文では異常なログ、健全なログ、ラベルのないログ、ラベルのついたログの4種類のログがあり、以下のように定義されます。
5-1. 異常ログ : ネットワークやサービスに異常が発生していることを示すログです。それぞれの異常ログは、特定の異常カテゴリに属します。
5-2. 健全なログ:異常が発生していないことを示します。つまり、健全なイベントや状態を記述しています。
5-3. ラベルのないログ : 前述のように、オペレータはすべての異常ログをラベル付け(識別)することができません。識別されずに残った異常ログは、健全なログと一緒にラベル付けされていないログの一部となります。
5-4. ラベル付けされたログ : 識別された異常なログは、ラベル付けされたログとなります。通常、オペレータはログにラベルを付けるための正規表現を手動で設定します。
通常、オペレータは正規表現を使用して異常なログをラベル付けします。しかし、正規表現は柔軟性に欠け、手間がかかるため、オペレータはすべての異常ログに対して正規表現を設定することができず、多くの異常ログがオペレータの目に留まらない状態になっています。
より具体的には、異常のログの一部だけがラベル付けされ、残りの異常のログも正常のログもラベル付けされません。PU学習は、正のサンプルの一部のみがラベル付けされ、残りの正のサンプルおよびすべての負のサンプルがラベル付けされないシナリオに対応して設計されています。
次回「後編」として、「LogClassの設計」「LogClass異常検知の精度」について、解説していきます。
参照
LogClass: Anomalous Log Identification and Classification With Partial Labels
Airitech(エアリテック)
Airitech株式会社は、最高のチームワークで、お客様の課題に最高の解決策をご提供いたします。
DXと業務改善に欠かせない「Celonis(セロニス)」の無料ウェビナーを開催しています。お申し込みはこちら