
Celonis Snapでプロセスマイニングをはじめよう「第2回 Celonisへのデータ取り込み」

こんにちは。Airitechプロセスマイニンググループのミャです。
本記事では、第2回目としてCelonis Snapの環境でEvent Collectionを使ってデータを取り込む方法をご紹介いたします。
第1回目は、プロセスマイニンググループ から無償のプロセスマイニング環境である「Celonis Snap」環境の準備方法をご紹介いたしました。まだご覧になっていない方は、こちらからご覧ください。
1. Celonis Event Collectionとは
Celonis Event Collectionは、プロセスマイニングの最初のステップになります。データの取込やデータモデル定義を行う機能になります。
データの取込はCSVやEXCELなどファイルから取り込みが可能です。
また、業務システムであるSAP、servicenow、Salesforce、Oracelなど様々な基盤となるソースシステムに接続できます。Celonisは、様々な方法で業務システムからタイムスタンプ付きのイベントログを収集して取り込みができます。
ここでは、CSVデータを用いてデータを取り込む方法をご紹介いたします。
2. CSVデータの用意
まずはじめに分析用のCSVデータを準備します。
ケースID・アクティビティ・タイムスタンプの3つのデータを決め、CSV形式で保存します。
IT部門に置けるチケット管理のデータでいうと、以下のようになります。
①ケースID → チケットID
②アクティビティ → 活動
③タイムスタンプ → 活動時刻
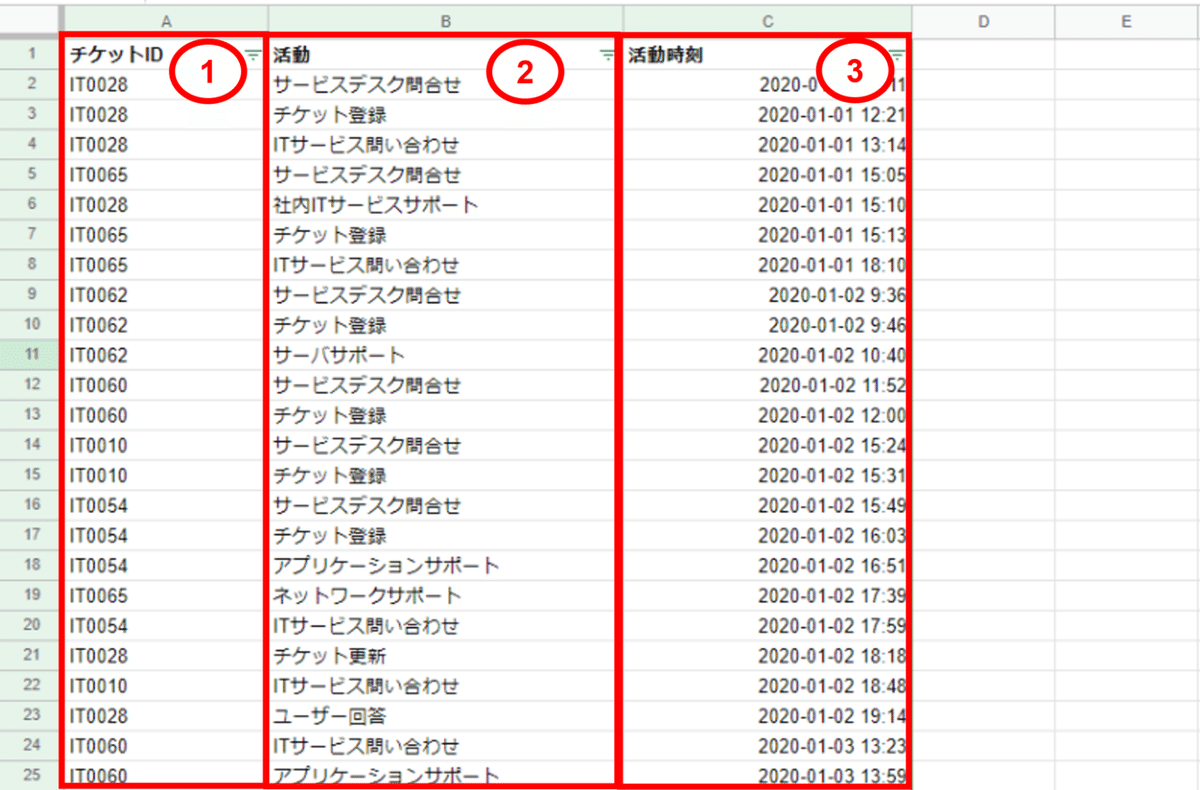
上記に加えて、チケット分類名など属性データとして一緒に取り込んでいくことでより深堀りした分析が可能となります。
今回の記事で取り込むデータの一覧です。

サンプルデータは、ここからダウンロードしてください。
3. データの取り込み
実際にCelonis Snapにデータを取り込んでいきます。
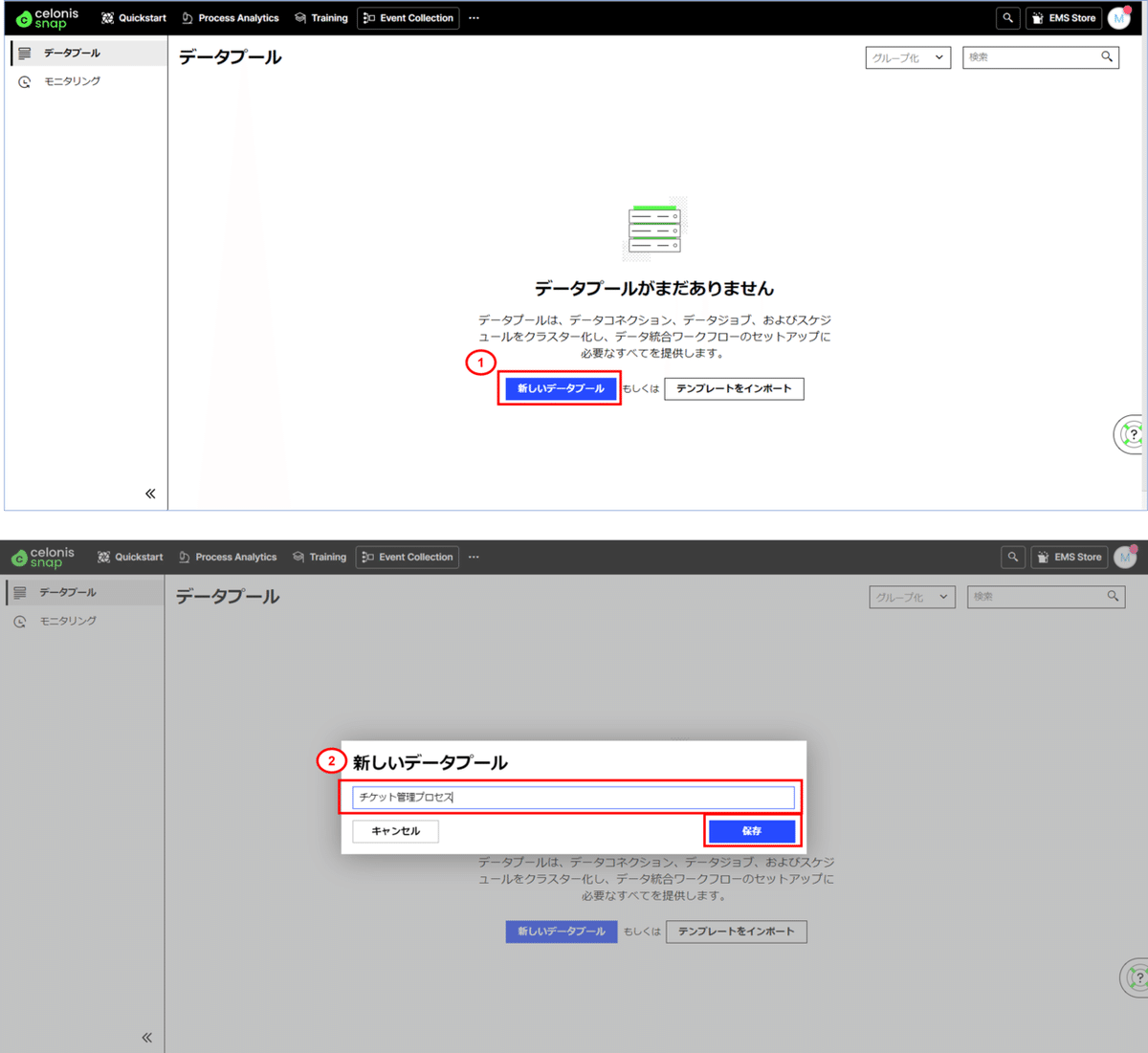
(1) データプールを作成します。
■作成手順
①「Event Collection」を選択します。
②「新しいデータプール」を押下し、「チケット管理プロセス」と名前をつけます。
(2) 作成したデータプールに、分析で使用するCSVデータを取り込みます。
■作成手順
①「ファイルアップロード」を選択します。
②CSVデータをドラッグアンドドロップする、もしくは、ファイルを選択ボタン押してアップロードする
③データが取り込まれたことを確認したら「次」を選択します。
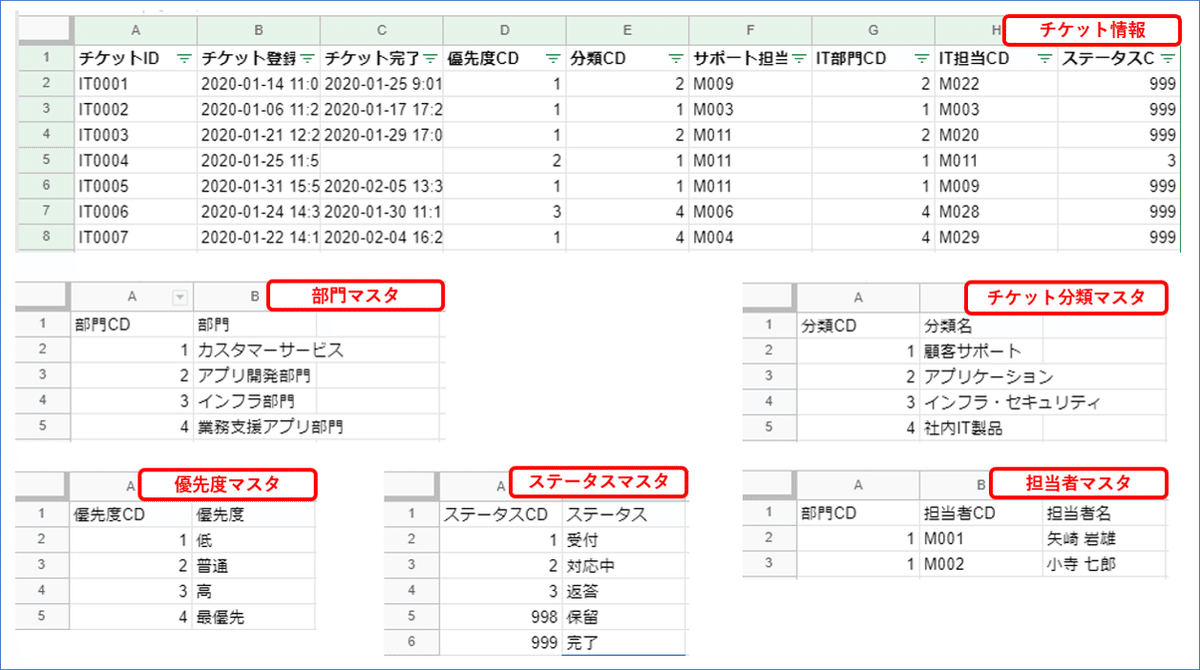
(順番は不問です。ここではチケット情報CSVを取り込みしました)

今度アップロードする属性情報です。チケット履歴CSVは、「2.CSVデータの用意」にて確認してください。
(3) データの桁数設定を行います。
■作成手順
①項目の桁数を設定します。
(今回はすべてデフォルト値)
②終了を押します。
続けて、同じ要領で他のCSVもアップロードします。
③データ取り込みが正常に完了しているかの確認として緑チェックとなっていることを確認します。

4. データモデルの作成
データ取り込みが完了したら、データモデルの作成を続けて実施します。
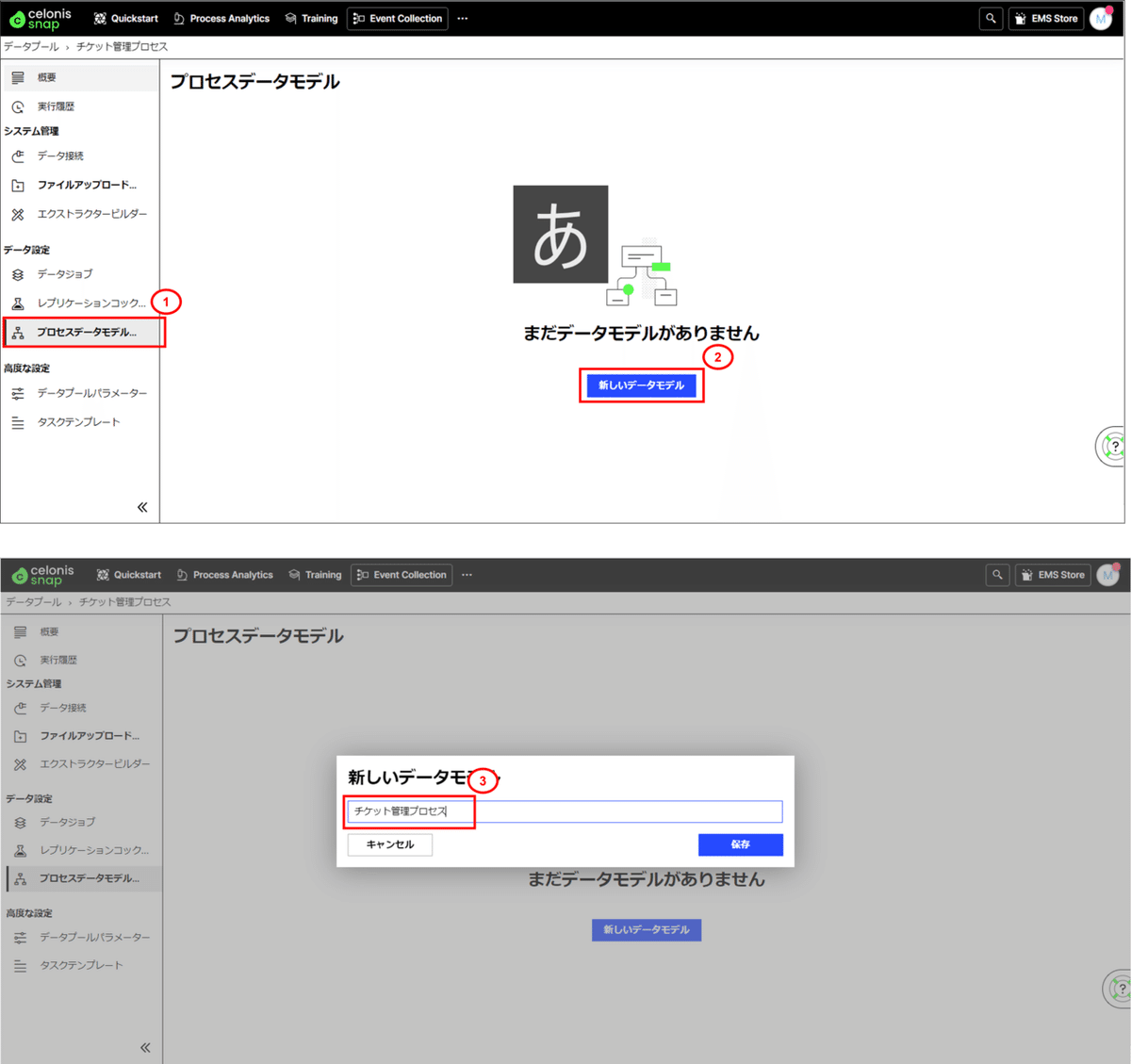
(1) データモデルの作成
■作成手順
①左メニューから、プロセスデータモデルを選択します。
②「新しいデータモデル」を押下します。
③「チケット管理プロセス」と名前をつけます。
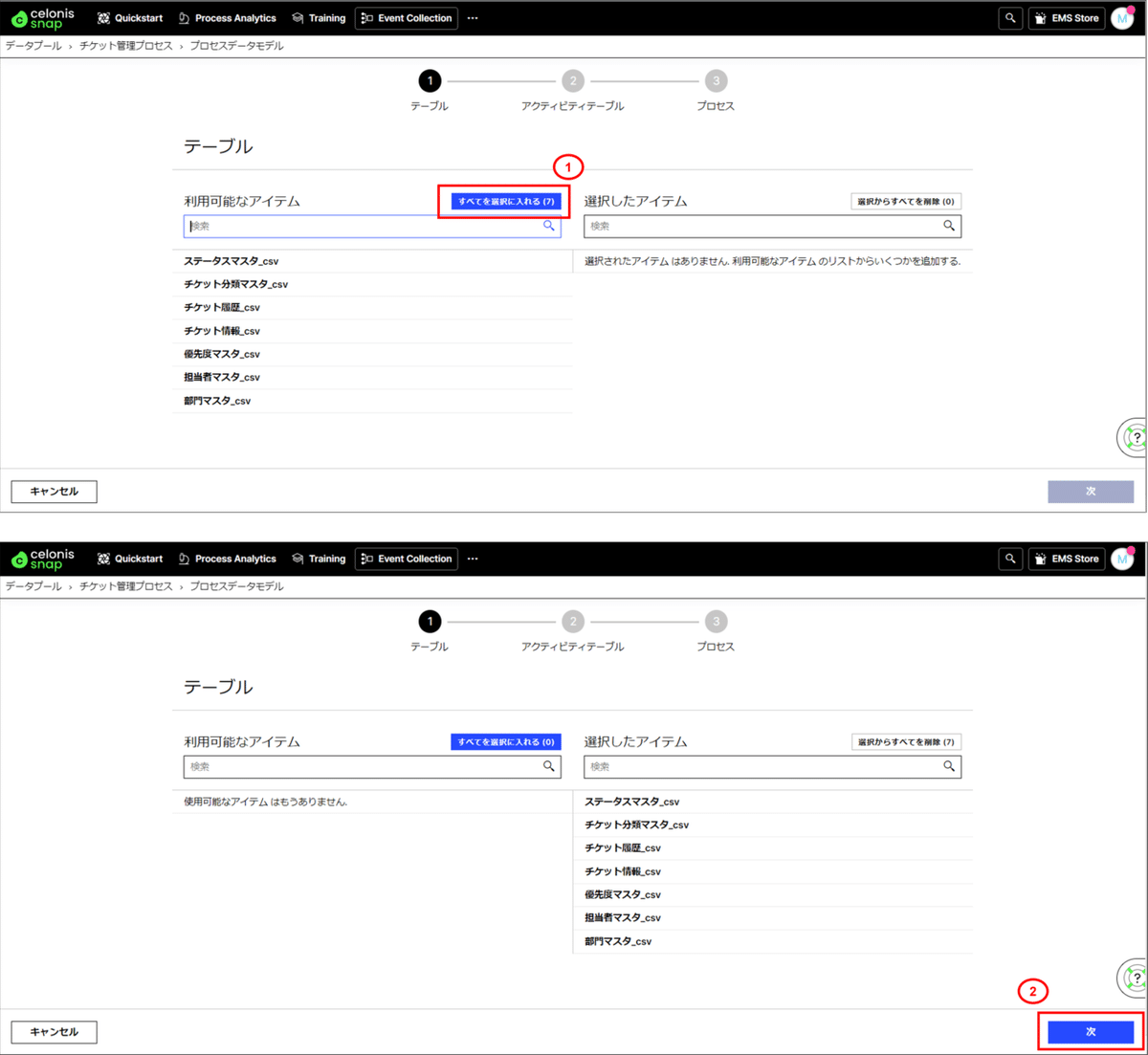
(2) 上記で取り込んだCSVデータを選択します。
■作成手順
①利用可能なアイテムの横にある「すべてを選択に入れる」を押下します。
押下すると取り込んだデータすべてが選択したアイテムの方に表示されます。
②次へを押下します。
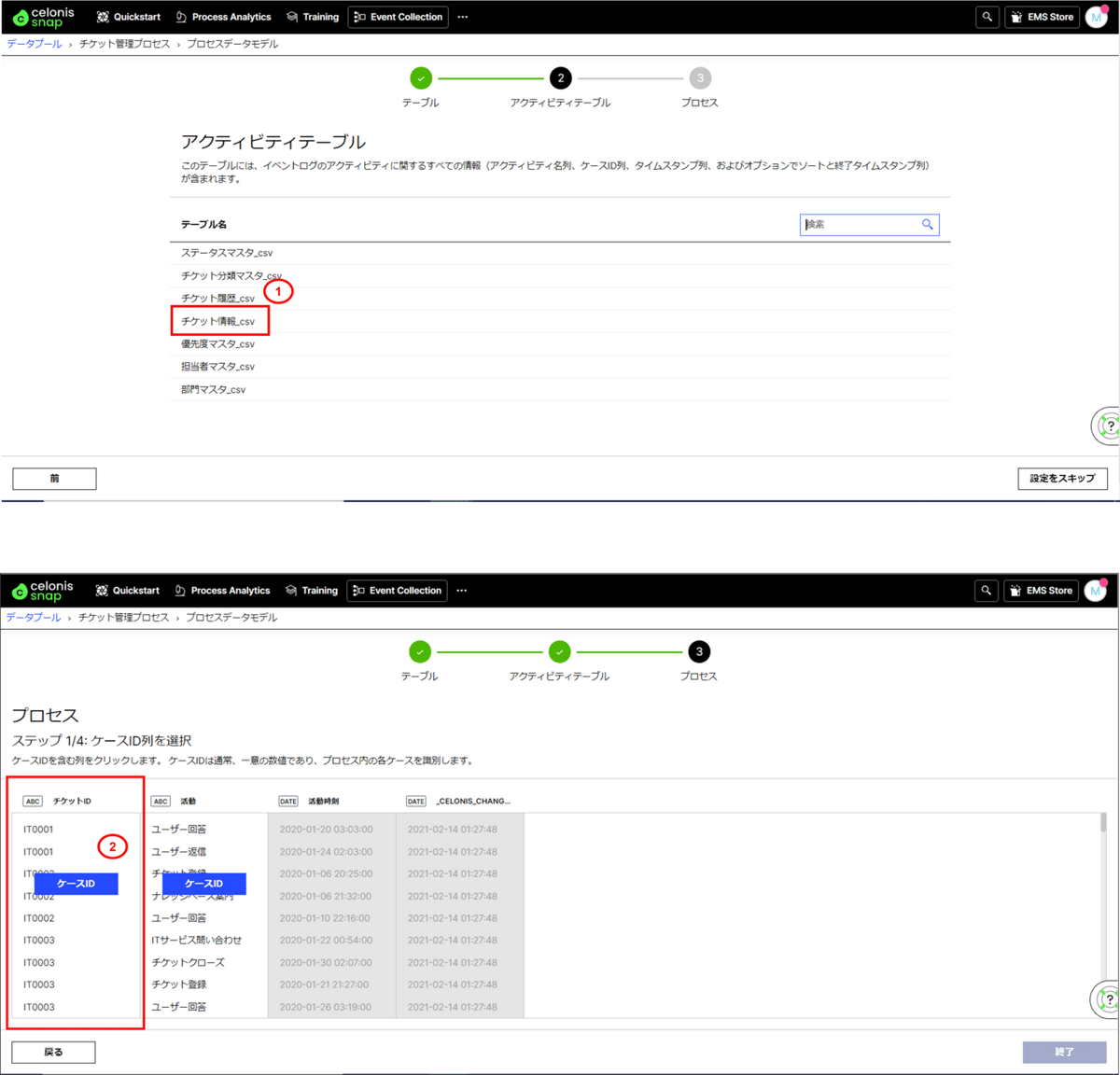
(3) アクティビティテーブルの設定後、どの項目がケースID、アクティビティ、タイムスタンプとなるか設定します。
■作成手順
①アクティビティテーブルに「チケット履歴_csv」を選択します。
②ケースIDに「チケットID」の項目を設定します。
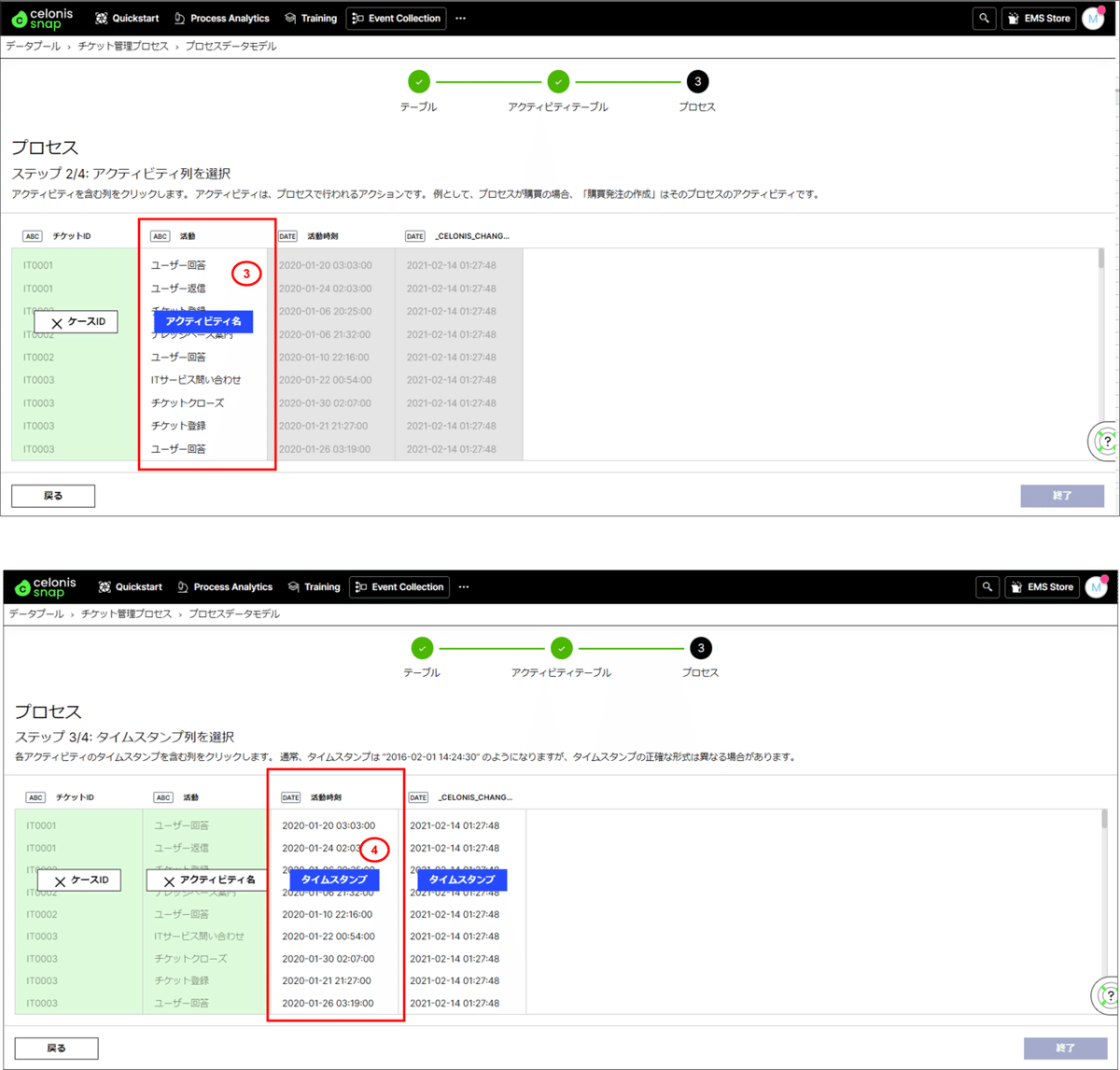
③アクティビティに「活動」の項目を設定します。
④タイムスタンプに「活動時刻」の項目を設定します。
⑤終了ボタンを押します。

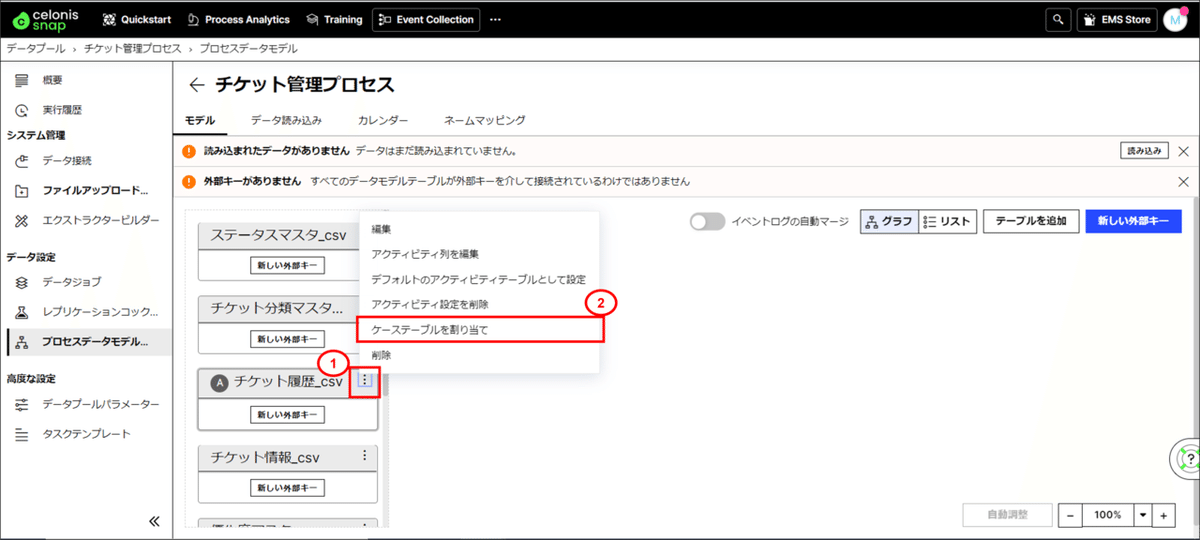
(4) ケーステーブルを設定します。
■作成手順
①アクティビティテーブル「チケット履歴データ」の右上3ポチを押下します。
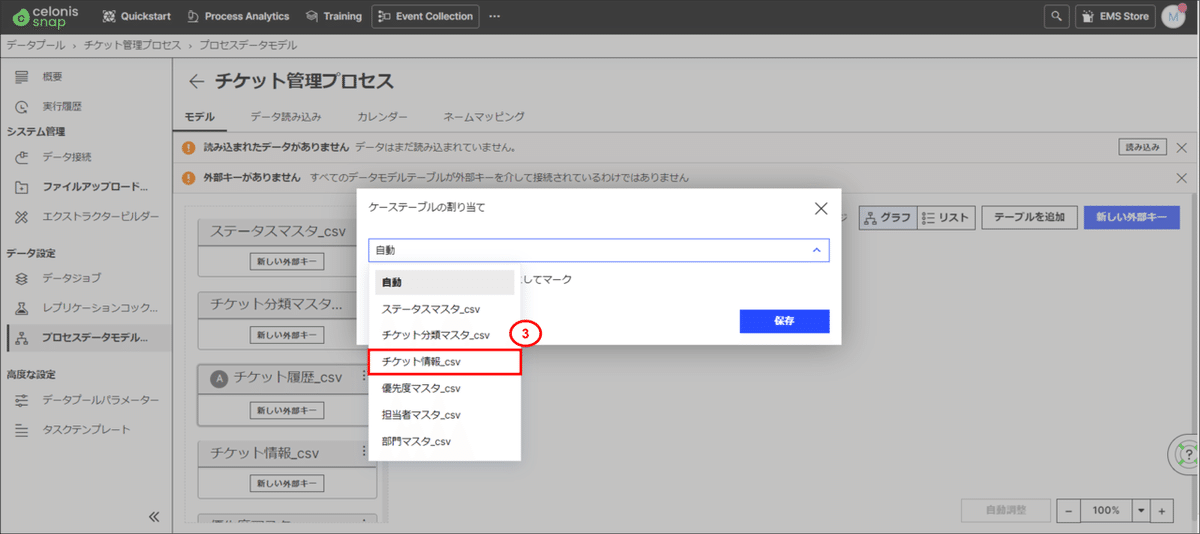
②「ケーステーブルを割り当て」を選択します。
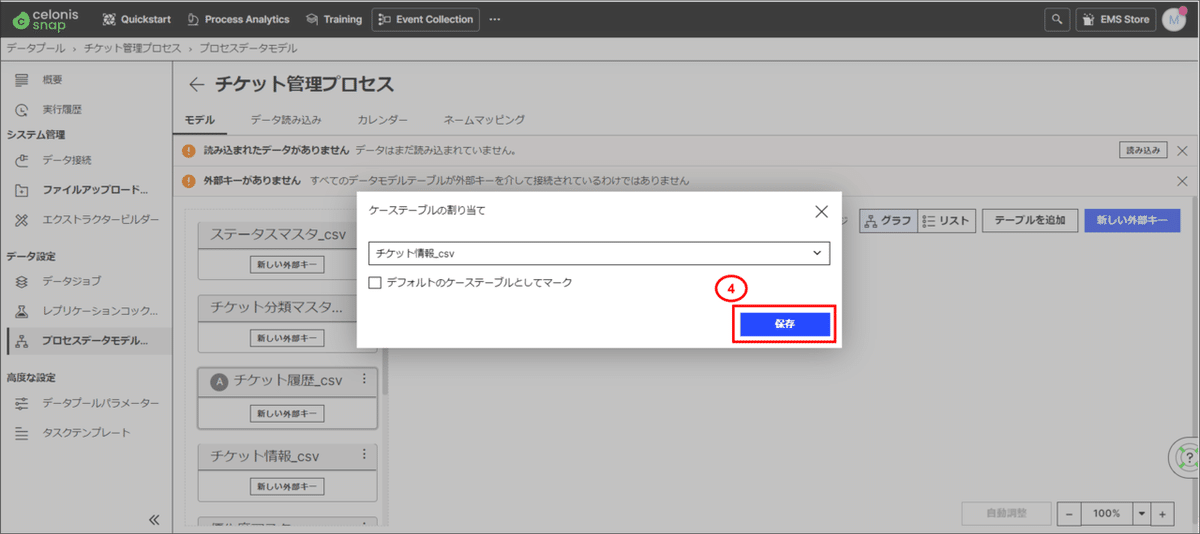
③ケーステーブルに「チケット情報」を選択します。
④「保存」を押下します。
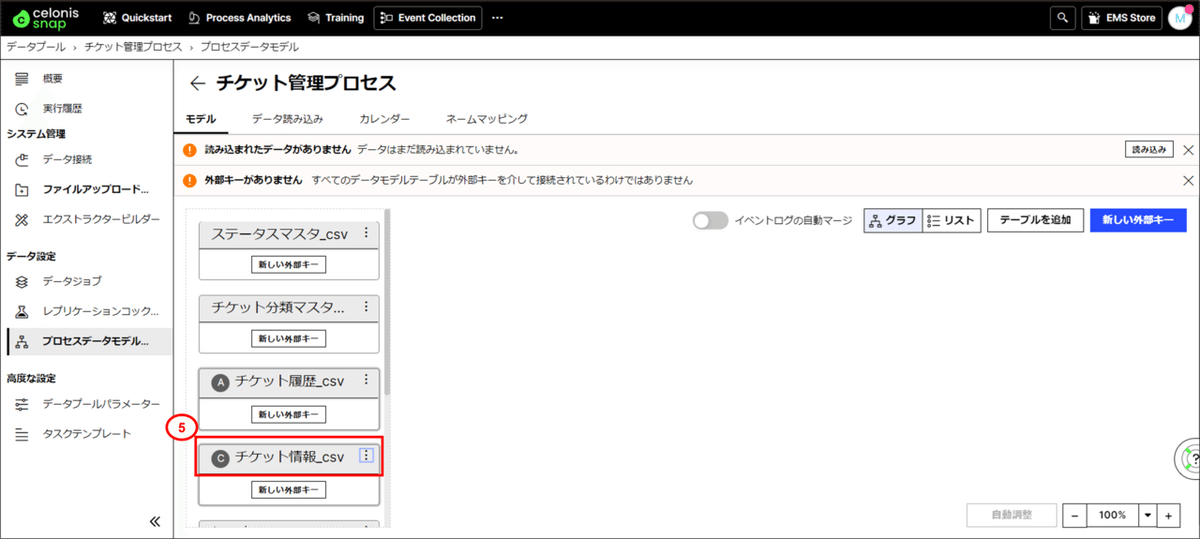
⑤チケット情報のヘッダーに「C」マークがついていることを確認します。
(5) ケーステーブル(チケット情報)を起点として、アクティビティテーブル(チケット履歴データ)を紐づけます。
■作成手順
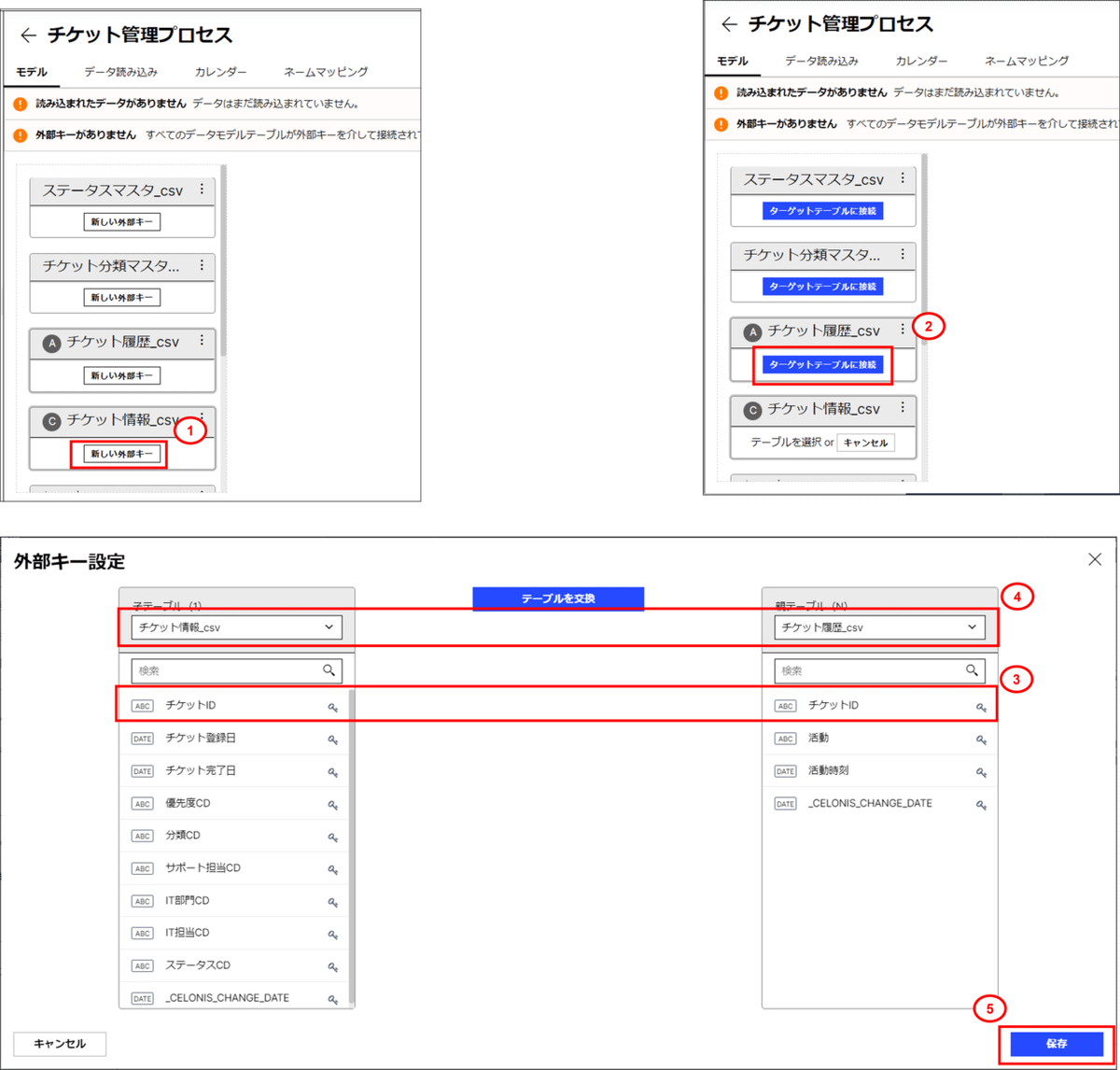
①チケット情報_csvの「新しい外部キー」を選択します。
②アクティビティテーブルにあたる、チケット履歴データ_csvの「ターゲットテーブルに接続」を選択します。
③チケット情報_csvの「チケットID」と、チケット履歴データ_csvの「チケットID」を選択し、キーの紐づけを行います。
④チケット情報_csv=子テーブル、チケット履歴データ_csv=親テーブルと設定されているか確認します。
⑤確認後、右下の「保存」を押下します。
⑥チケット情報_csvとチケット履歴データ_csvのテーブルが関連されていること確認します。
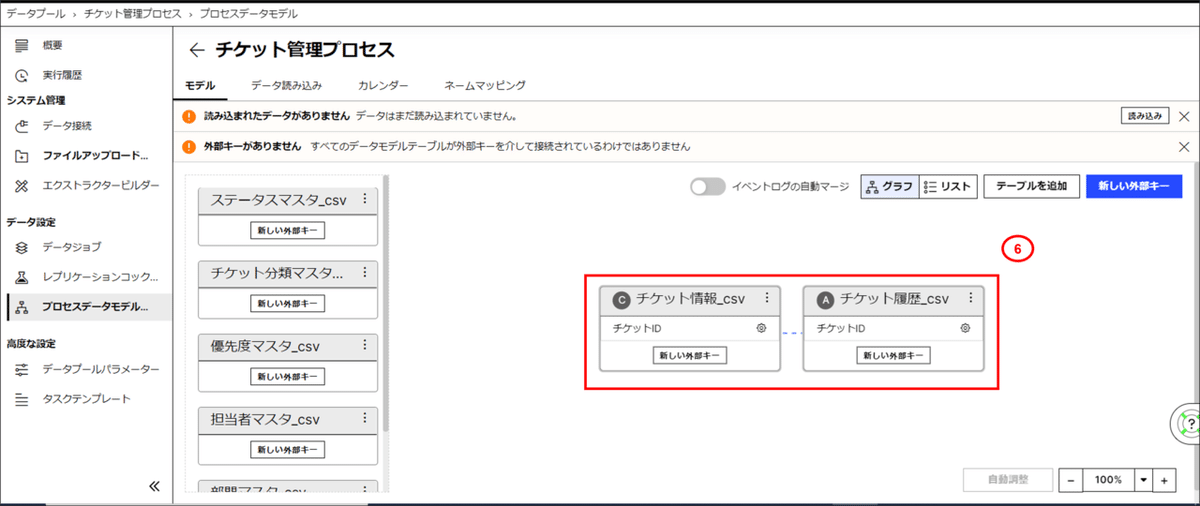
(6) 前項と同様に、チケット情報_csvを起点として、その他マスタテーブルを紐づけます。親子の関係は前項と逆に設定します。
▼部門マスタ_csvとチケット情報_csvの紐づけ
①チケット情報_csvの「新しい外部キー」を選択します。
②部門マスタ_csvの「ターゲットテーブルに接続」を選択します。
③チケット情報_csvの「IT部門CD」と、部門マスタ_csvの「部門CD 」を選択し、キーの紐づけを行います。
④チケット情報_csv=親テーブル、部門マスタ_csv=子テーブルと設定されているか確認します。
▼担当者マスタ_csvとチケット情報_csvの紐づけ
①チケット情報_csvの「新しい外部キー」を選択します。
②担当者マスタ_csvの「ターゲットテーブルに接続」を選択します。
③チケット情報_csvの「IT担当CD」と、担当者マスタ_csvの「担当者CD 」を選択し、キーの紐づけを行います。
④チケット情報_csv=親テーブル、担当者マスタ_csv=子テーブルと設定されているか確認します。
▼チケット分類マスタ_csvとチケット情報_csvの紐づけ
①チケット情報_csvの「新しい外部キー」を選択します。
②チケット分類マスタ_csvの「ターゲットテーブルに接続」を選択します。
③チケット情報_csvの「分類CD」と、チケット分類マスタ_csvの「分類CD 」を選択し、キーの紐づけを行います。
④チケット情報_csv=親テーブル、チケット分類マスタ_csv=子テーブルと設定されているか確認します。
▼ステータスマスタ_csvとチケット情報_csvの紐づけ
①チケット情報_csvの「新しい外部キー」を選択します。
②ステータスマスタ_csvの「ターゲットテーブルに接続」を選択します。
③チケット情報_csvの「ステータCD」と、ステータスマスタ_csvの「ステータCD 」を選択し、キーの紐づけを行います。
④チケット情報_csv=親テーブル、ステータスマスタ_csv=子テーブルと設定されているか確認します。
▼優先度マスタ_csvとチケット情報_csvの紐づけ
①チケット情報_csvの「新しい外部キー」を選択します。
②優先度マスタ_csvの「ターゲットテーブルに接続」を選択します。
③チケット情報_csvの「優先度CD」と、優先度マスタ_csvの「優先度CD 」を選択し、キーの紐づけを行います。
④チケット情報_csv=親テーブル、優先度マスタ_csv=子テーブルと設定されているか確認します。
(7) データモデルが以下の通り作成されているか確認します。
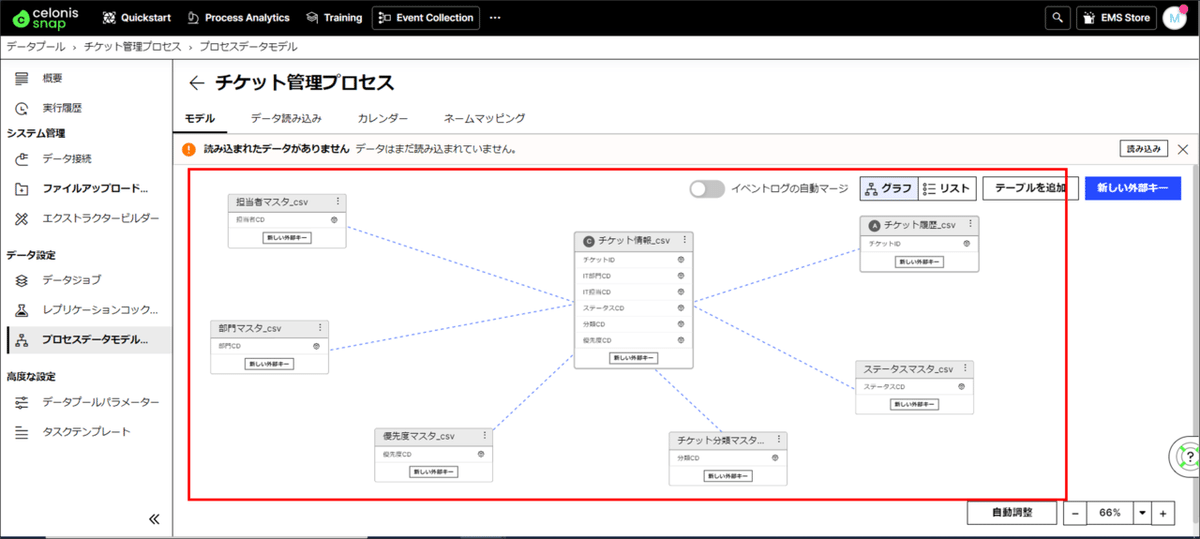
5. データモデルロード
データモデルが完成したら、データを読み込みます。
■作成手順
①「データ読み込み」タブを選択します。
②「完全なリロードを実行」を選択します。
③正常に読み込みが完了しているか、確認します。

これで、プロセスマイニングを始めるためのデータの準備ができました。次回の記事では、取り込んだ情報を用いた「プロセスの可視化」についてご紹介いたします。
Airitechでは、定期的に無料ウェビナーなども行っております。
ご都合の合う方は、ぜひ無料ウェビナーにも参加してみてください。
お申し込みはお気軽にどうぞ!
購買管理業務を効率化しませんか?(プロセスマイニング無料ウェビナー)https://www.airitech.co.jp/service/process-mining/celonis/celonis_purchase/