
初めてのAWSデータ連携、何を考えればいいの?(送信元/先のデータ受信/送信についての方針編)

こんにちは。
Airitechのシステム開発グループのピンです。
前回は、AWSでデータ連携を行うときに考えるべき「全体の方針編」を執筆しました。今回は続きとして、送信元と送信先へのデータ連携方式について紹介したいと思います。
■送信元と送信先へデータ連携方式について
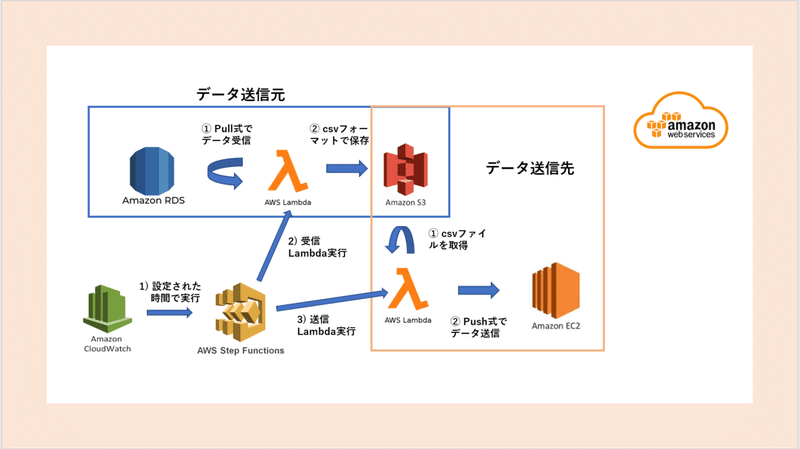
前回と同じく、下記図のDB情報の連携を例に挙げながら、考えた内容や利用したAWSサービスを共有します。

■考えるべきポイント
送信元から送信先へデータを連携するときは、下記の点を考える必要があります。
・受信・送信で必要な対象データ・データフォーマット
・受信・送信するときのプロトコル
・受信データの保管期限
・受信・送信処理の開始・完了時刻
・データ連携開始以前のデータをどうするか
受信と送信の連携IFについて、上記のような考えるべき点の詳細を下記に紹介します。
■対象データを決める
1. 受信対象やデータフォーマットは何か?サイズはどの程度か?
データ取得元の方式(DB or ファイルから取得かなど)および、データフォーマット(JSON or CSVかなど)を決める必要があります。
また大量のデータがある場合、連携時間にも影響が出ますので把握が必要です。
例ではDB連携なので、当たり前ですが、受信対象はDBです。
今回データサイズは約500KB程度だったため、十分小さいといえますが、将来増える可能性があります。定期的にデータの増減を確認したところ、特に大きな増加はありませんでした。そのため対策は不要です。
次にデータ受信時のデータフォーマットですが、DB連携のため、テーブル型のデータとなります。
2. 受信プロトコルは何か?Push型かPull型か?
受信時のプロトコルが何か明らかにする必要があります。
またプロトコルにもよりますが、連携元からPush型でデータを受領するのか、データ連携側からPull型でデータを取得するのかも明確にする必要があります。
DB連携では、SQLをJDBC経由で発行しデータを取得することとなります。
そのため、データ連携側からPull型でデータを受領する必要があることがわかりますね。
前回の記事で記載した「DBから取り込むデータの特色に対する利用サービス」では、データが少ない場合はAWS Lambdaの利用がよいと紹介しました。
ですので、AWSでのデータベースとしてAmazon RDSを利用して、AWS Lambda(連携IF)からデータをpullする方式で構築します。
Amazon RDS(DB)がパブリックではない場合は、AWS Lambdaから接続できるようにSecurity Groupなどの設定が必要になりますので注意してください。
またAWS Lambdaは実行時間15分、メモリは最大でも10,240 MB、/tmp ディレクトリのストレージは最大でも512 MBなどの制限がある点も注意が必要です。
上限を超えるデータの場合、部分的に読みこむ処理を入れるなど工夫が必要なため、AWS Glue、AWS Batch / Amazon ECS サービスの利用も選択肢に上がります。
3. 送信対象のデータフォーマットは何か?
受信時と同じく送信時のデータフォーマットを決める必要があります。
ファイルを送信する場合は出力先のディレクトリ構成やファイル名なども決める必要があります。
DB連携では、利用者側にてcsvファイルでの利用が要望として上がったため、csvファイルとして出力することとしました。
また個人情報を含むため、ファイル単位で暗号化して配置する形式としています。
連携トリガーは日次となるため、以下のようなディレクトリ構成としています。
フォルダ名 : (受信システム名/データ種類名/YYYY/MM/DD)
ファイル名 : (データ種類_日時)
また作成したファイルは直接連携先のシステムへ送信せずにAmazon S3に保存することとしています。なぜならば受信・送信を行うタイミングはそれぞれのシステムの都合があり、別々のタイミングで行いたいためです。S3へ保存すれば任意のタイミングでデータを受領できます。
ちなみに、Amazon S3 はバケット内に、オブジェクト(ファイル)としてデータを保存します。対象バケット内に上記に記載したフォルダ名でパスを作成し、ファイルを保存することになりますね。送信するときはS3から対象オブジェクト(ファイル)を送信もしくは、連携先システムがpull型で受領することになります。
4. 保管期限はどの程度か?保管期限を過ぎたデータをどう扱うのか?
潤沢なリソースがない場合は永遠にデータを格納することが出来ないため、保管期限を決める必要があります。また期限を過ぎた後に即削除するのか、バックアップを取っておくのかなども決める必要があります。
例のDB連携では、利用者側への確認の結果、最大3ヶ月保存したいとの要望があったため、保管期限を3ヶ月とすることにしました。
またバックアップ利用は不要だったため、期限後は、削除としています。
AWSの上だとファイルが保存されたAmazon S3のバケットに3ヶ月後に自動で削除する設定をすることになります。Amazon S3での設定方針はこちらで参照できます。
■連携トリガーを決める
データを利用したい方々には、いつまでにデータが欲しいか要望があります。連携IFとしてはこの要望の時間より前に連携トリガーを開始して連携を完了させる必要があります。
リアルタイムにデータが必要ならばリアルタイムで連携することになるし、バッチでデータが必要ならば日次・毎時などで連携することになります。
例のDB連携では、利用者より、業務前(9:00)にデータ利用したいとの要望でした。そのため、毎朝業務が始まる前の時間帯にバッチを起動し、データを連携することとしました。
先ほど記載したように、一度S3へ保存した後、連携するため、下記のLambdaで構成しています。
1. データを受信し、csvファイルフォーマットでS3に保存する。(受信Lambda)
2. 送信対象のファイルをS3から取得して送信する。(送信Lambda)
当然ですが、受信Lambda処理は送信Lambda処理の開始時間前には完了する必要があります。しかし、受信Lambda処理の実行完了時間は正確にはわかりません。そこで受信Lambda処理の後に送信Lambda処理をシリアルフローで実行するようにAWS Step Functionsを使ってフローを作成しました。

上記画像の用にStep Functionsを利用して連携トリガーを作成しました。
Lambda処理をStep Functionsでつなげることで、受信Lambda処理の後に、送信Lambda処理をシーケンシャルに処理できるようになります。
データ種別2つとも毎朝業務が始まる前に送信する必要があるため、Step Functionsを毎朝業務が始まる前の時間帯に実行させることになります。決められた時間でStep Functionsを実行させるためAmazon CloudWatch で設定しています。
■データ連携を開始する前の準備が必要かどうか?
日次での連動でしたが、初回連動を行う前に、今まで蓄積したデータをどうするかも確認が必要です。
既に稼働しているシステムであれば、データ連携を開始する日以前のデータも利用する可能性が高いです。
このような場合元々のデータを一気に連携するときはサイズが大きいため、今回作成した連携IFを利用するよりも、手動で連携することも考えないといけません。
もし、今までのデータ全部を連携する必要がある場合は、取得時間がかかることや、ファイルサイズが大きすぎてLambdaの制限を超える可能性が高いです。
そのため手動で連携するか、日付などで小さなデータ群に分割して連携IFを使えないか検討する必要があります。
■全体の連携方針まとめ
以上の通り、受信・送信について、一通り検討を進めました。
この記事では全体の連携方針で考えるべきポイントである
・受信対象やデータフォーマットが何か?サイズはどの程度か?
・受信プロトコルは何か?Push型かPull型か?
・送信対象のデータフォーマットは何か?
・保管期限はどの程度か?保管期限を過ぎたデータをどう扱うのか?
を中心に記載しました。今後の検討のヒントになるとうれしいです。
上記の点を決めた後AWSの上で構築してみると下記の画像のような方針になります。
最後まで読んでくれてありがとうございます。
引き続きまた共有したい点が残っているので、次回の記事で紹介します。
次回もぜひご覧ください。どうもありがとうございました。
Airitechの採用情報はこちら
ホームページ