
社内勉強会レポート|Standford CS230のご紹介

こんにちは!Airitech DX-2ビッグデータとAIグループのKです。
Airitechでは、定期的に社内勉強会を行っています。機械学習の習熟度を上げるため、社内勉強会にてStandford CS230のDeep Learningクラスを採用しております。先日、そのクラスについて、社内で共有しましたのでレポートします。
この記事では、Standford CS230 Deep Learningクラスの紹介を致します。
参考のYouTubeビデオは、こちらです。
先生のご紹介
Andrew Ngは、Courseraの創設者であり、スタンフォード大学で働いています。Google Brain Teamを立ち上げ、多くのプロジェクトを行いました。また、Googleが今日世界で最高のAI企業になるのを支援しました。
Standford CS230 Deep Learningとは
Deep Learning(ディープラーニング)は、AIとComputer Scienceの最新技術です。CS230 クラスは、ディープラーニングを使用して構築されたシステムなど、ディープラーニングを使用するシステムのコンポーネントを学習することを目的としています。
CS230が他のStanfordのCS230以外のクラスと異なる特徴はインタラクティブであるという点です。オンラインのビデオで授業を行い、参加者同士で宿題を解いてディスカッションできます。

クラスには多くのTeaching Assistant (TA)さんたちが参加しており、ロボット工学・計算生物学・ヘルスケアなどさまざまな形式の学習における機械学習とディープラーニングを専門として研究しています。彼らからもいろいろな意見を聞くことができますのでCS230クラスを受講することは大変勉強になると思います。
まず先生から、ディープラーニングの分野で何が起こっているのか、そしてなぜディープラーニングの研究が仕事の機会に影響を与える可能性があるのかという説明があり、その後Andrew先生のTA Kianがクラス内で試しているプロジェクトと本クラスで生徒が行った他のプロジェクトを紹介してくれます。
最初にディープラーニングが他の学習手法よりも優れているのかどうかという問題についての見解を説明しました。テクノロジーは過去数十年で変化しました。そのため、人々はテクノロジー環境でますます多くのデータを収集していきました。
たとえば、ほとんどの時間をコンピューターや電話で行うと、集まるデータが大きくなります。紙に記録されていたものは、現在デジタルデータに変換されています。米国や他の先進国でも、X-rayなどのデータはフィルムではなくデジタル画像に置き換えられています。
たとえば、現代はマーカーをECサイトから購入すると注文履歴はデータベースに保存されます。約10年前だと注文履歴は紙に書き留められるだけでした。現在、すべてのデジタルデータが残っており、その結果、さまざまなアアプリケーションからのデータ量が爆発的に増え、データは20年前よりもはるかに多くなっています。
通常の計算アルゴリズムと通常の機械学習アルゴリズムがある場合、データが多いほど、パフォーマンスコンピューティング機能への影響が大きくなります。
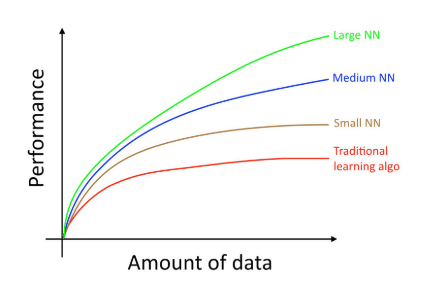
logistic regressionsやsupport vector machinesなどの日常的な学習アルゴリズムのようなデータは、大量のデータを提供する場合、計算が難しい場合があります。
しかし、近年、ニューラルネットワークが使われ始めています。Small NNではパフォーマンスが少し向上し、Medium NNではパフォーマンスがわずかに向上しています。指定されたエラー率内でもLarge NNならパフォーマンスがさらに向上しています。
ただし、大ニューラルネットワークの計算により、コンピューティングコストも上昇しています。以前は、スーパーコンピューターに多額の費用がかかる可能性がありましたが、今ではクラウドGPUコンピューティングでLarge NNを計算可能です。
大規模なコンピューティングも計算できるようになり、学生はほぼ全員でデータにアクセスしてトレーニングできるようになりました。
AIの学習について
AIは、教育やキャリアでも使用されています。AIと言えば、機械学習/深層学習を超えたアプリケーションを意味しています。
AIツールは、CS221クラスで勉強できます。機械学習/深層学習(深層学習はニューラルネットワークに非常に似ている)は過去数年で成功したブランドであり、ディープラーニングのより魅力的なテクノロジーとして、CS230で勉強する方針です。
AIクラスを受講すると、AIのツールについて詳しく知ることができます。例えば下記の項目などです。
1. 深層学習と機械学習
2. CS-228で教えるPGMと呼ばれる確率的グラフィカルモデル
3. 計画アルゴリズム
※たとえば、自動運転車のような場所では動作計画アルゴリズムが必要。
4. 検索アルゴリズム
5. 知識表現
6. ゲーム理論

Fig:確率的グラフィカルモデル会議,計画アルゴリズムの会議、検索アルゴリズム会議などではパフォーマンスはグラフのように徐々に増加しておりますが、ディープラーニング/機械学習の会議でパフォーマンスは急速に増加しています。
多くの肯定的なフィードバックを得て、多くの人々が深層学習アルゴリズムの研究を行ったため、ここ数年で多くの研究革新が生まれました。スケールデータの計算を通じて得られたパワー、巨額の投資、およびアルゴリズムの革新は、ディープラーニングの未来をより良いものにしています。
したがって、CS230クラスでは下記2つのことに焦点を当てます。
1つ目は、深層学習の高度な手法を理解して、深層学習アルゴリズムを理解することです。もう1つは、これらのアルゴリズムの動作方法を学び、問題に適用することです。
CS230でどのように勉強をするのか
現在インターネットは、最も純粋な学術情報源になっております。技術情報などを読むことで、機械学習と深層学習の技術的概念、それらのアルゴリズムで使用される実用的なデータについても学ぶことができます。先生は、John Osahaltsのsoftware architectureの本について共有しました。この本では、ジュニア ソフトウェアエンジニアとシニア ソフトウェアエンジニアの間に大きな違いがあることを説明しています。
C++、Python、Javaいずれかの構文を知っている人がいるとします。PythonNumPyなどライブラリの動作を理解しているとしても、高レベルの判断を行う際にはそれだけでは不十分です。実験で得られた知見に対してどう対処するかはエンジニアリングを深く理解し、機械学習とディープラーニングについても知っておくべきことがたくさんあります。本クラスではこれらの知識の補完も提供しています。
1. ネットワークネットワークをトレーニングする方法
2. アルゴリズムを最適化する方法
3. CNNとは何か?
4. RNNとは何か?
5. LSTMとは何か?
そこから、コンピュータビジョン、自然言語処理、音声認識への応用を学習できます。また、Courseraのdeeplearning.aiクラスから、機械学習システムを構築する方法を学ぶことができます。
あるプロジェクトでデータを収集し続けるかどうかを決定しようとしたら、答えは必ずしも「はい」ではありません。データが多ければ多いほど良いと言われていますが、データが多ければ多いほど正確ではありません。
機械学習プロジェクトを行う場合は、自分で行い、チームを率いて、さらに1週間データを収集し続けるか、データの検索を停止してハイパーパラメーターの検索を続けるか、ニューラルネットワークを調整するかを正確に判断しないといけません。決定によってチームに2、3、または10倍の影響を与える可能性があります。本クラスは、決定が成功するのに必要なことを教えるクラスになります。
先生は、例を挙げて説明しました。
先生は機械学習チームを研究するために出張し、30人で学習アルゴリズムを構築している会社に行き、3カ月間研究を行いました。しかし、3カ月後、結果が何も出てきませんでした。
ところが、先生のチームの1人があるデータを取得し、そこで1週間で3日間続けフルタイムで働きました。彼は3カ月で30人で作成したシステムよりも優れた機械学習システムを構築できました。その結果、10倍速くなりました。
先生が言いたいのは、優れた機械学習チームと経験の浅いチームには大きな違いがあることです。もちろん、これはLSTMがTensorflowフローまたはKerasに基づいて構築されていることを意味するものではありませんが、何か他のことを学ぶ必要があります。CS230クラスの教育チームにより、機械学習エンジニアチームを率いるときに、チームの取り組みをより効果的にするための支援を行うこともできます。
このクラスの進め方は、コースに投稿されたビデオを見て、演習をしてから、クラスでディスカッションをします。
先生は、いくつかのポイントを述べました。機械学習、ディープラーニング、AIなどは、多くの業界を変えています。ご存じのように、約100年前、米国の電気は多くの産業を変革しました。電気、農業、食品冷蔵庫を通して、農業は過去のものになりました。それだけでなく、ヘルスケアも変化しました。
現代の病院は電気なしには成り立ちません。コンピューターや機械を使わずに医療システムを作るにはどうすればよいでしょうか。さらに、電気通信技術が向上し、すべての電気通信には電気が必要です。同様に、機械学習とディープラーニングが実を結び、さまざまな業界で驚くべき変化をもたらすと思います。先生がこのクラスである一人の学生と話したとき、彼は機械学習を宇宙論に応用できないかを議論していました。宇宙論へも深層学習のアイディアが応用される日も近いかもしれません。
CS230で先生が期待しているのは、AI変革を行っている大企業のAIチーム(Google BrainとBaidu AIグループ)のようなものです。AIが、さまざまな分野で応用されることを期待しています。AIがヘルスケアに利用され、AIが計算生物学に利用され、AIが土木工学に利用され、AIが機械工学に利用されるなどです。
最後に、先生は、CS229、CS230、およびCS229Aクラスの違いを説明し、CS230は深層学習に重点を置く予定であると述べています。その後学生さん達とQ/Aを行いました。
Q/A
質問:先生は電気の力をAIと比較して使用していましたが、現在の機械学習を利用して成功した事例を説明していただけますでしょうか?
回答: 今日の人々は毎日たくさんの学習アルゴリズムを学んでいます。Web検索エンジンを使用するたびに、学習アルゴリズムによって検索結果が向上しています。そして、これらの学習アルゴリズムを使用して、企業に適切な広告を作成させてお金を稼ぎます。
実際、GoogleとBaiduは、検索の10%が携帯電話での音声検索によるものであると公に述べています。AmazonやNetflixなどのWebサイトも、自分に適している製品を推奨する学習アルゴリズムを提供しています。
クレジットカードを使用して疑わしい取引を防ぐ学習アルゴリズムを持っています。電子メールを使用する場合のスパムフィルターもあります。これはすべて、学習アルゴリズムを通じて行われます。
もう1つの興味深い点は、バックグラウンドで表示されないようにすることです。
例:マップを使用している間、ショートカットを探し、学習アルゴリズムをオフにする方法を示します。つまり、人はその道路が閉鎖されていることを知っているので、その道路には来ません。とはいえ、障害のリスクを減らすこともできます。現在学校に通っている生徒の中には、ヘルスケアに関連する機械学習に取り組んでいる人もいます。農業に従事している人もいます。それが彼に多くの分野で機械学習を学ばせた理由です。他にもたくさんありますが、本日はここまでにします。
質問:ここで勉強することとCourseraで勉強することの違いは何ですか?学習は違うのですか、それとも同じですか?
回答:このクラスの形式は、deeplearning.aiで勉強できるビデオがあります。
このクラスでは、教育チームが毎週、新しいコースを追加し、オンラインで投稿されていないことも共有しています。
その後TAは、CS230クラス勉強の流れについて説明しました。詳しくは、以下のリンクをご覧ください。コースは5つの章で構成されています。
C1: Neural Networks and Deep Learning
C2: Improving Deep Neural Networks
C3: Strategy for Machine Learning Projects
C4: Convolutional Neural Networks
C5: Sequence Models
CS230を勉強したい方は、下記のリンクをご覧ください。
Course link:http://cs230.stanford.edu/syllabus/
lecutre link:https://youtu.be/PySo_6S4ZAg
subclass link : https://youtu.be/CS4cs9xVecg
Airitechでは定期的に社内勉強会を行っています
採用情報はこちら
/assets/images/7140406/original/66b0d4f5-28a5-43df-898a-22aff4125059?1625481943)
/assets/images/6991340/original/3ac8c41b-88a7-4bf0-8a16-e52f1ea2a648?1625458984)
/assets/images/7160283/original/36e1b004-ee88-462e-a6e1-8e0c5a44134d?1625732695)