
【論文瞬読】LLMの専門家を育てる:少数データで大規模言語モデルをタスクのプロに

こんにちは!株式会社AI Nestです。今日は、大規模言語モデル(LLM)の世界に革命を起こす可能性のある最新の研究について紹介します。「Leveraging Open Knowledge for Advancing Task Expertise in Large Language Models」という論文を読んで、目から鱗が落ちる思いでした。この研究は、LLMを特定のタスクのエキスパートに育てる新しい方法を提案しているんです。さあ、一緒に掘り下げていきましょう!
タイトル:Leveraging Open Knowledge for Advancing Task Expertise in Large Language Models
URL:https://arxiv.org/abs/2408.15915
所属:Institute of Image Processing and Pattern Recognition, Shanghai Jiao Tong University, Shanghai, China、Tencent YouTu Lab, Shanghai, China
著者:Yuncheng Yang, Yulei Qin, Tong Wu, Zihan Xu, Gang Li, Pengcheng Guo, Hang Shao, Yucheng Shi, Ke Li, Xing Sun, Jie Yang, Yun Gu
1. 研究の背景:なぜLLMの専門家が必要なの?
最近、ChatGPTやGPT-4のようなLLMがすごい勢いで進化していますよね。でも、これらのモデルは「何でも屋さん」的な存在で、特定の分野やタスクになると専門家レベルの性能を発揮できないことがあります。例えば、医療や法律、特殊な技術分野などでは、より深い専門知識が求められますよね。
そこで登場したのが、この研究です。LLMを特定のタスクの専門家に育てる効率的な方法を提案しているんです。しかも、少ないデータと計算資源で!これってすごくないですか?
2. 研究のアプローチ:オープンソースの知恵を活用
研究者たちが注目したのは、インターネット上に公開されている豊富な知識です。具体的には:
LoRA(Low-Rank Adaptation)モデル:これは、LLMを効率的に微調整する手法です。
指示データセット:LLMに特定のタスクを教えるためのデータです。
これらのオープンソースリソースを賢く活用することで、ゼロから学習させるよりも効率的にLLMを専門家に育てられるんです。

上の図は、この研究で提案されている全体的なパイプラインを示しています。K-shotデータを中心に、モデル選択、データ選択、そしてMoEシステムの構築と最適化が行われていることがわかりますね。
3. K-shot学習:少数のデータで大きな効果
この研究の鍵となるのが「K-shot学習」です。Kは数字で、例えばK=5なら5個のサンプルデータを使うということ。驚くべきことに、たった5個のサンプルでも、LLMの性能を大幅に向上させることができるんです!
研究者たちは、このK-shotデータを使って:
最適なモデルを選択
追加の学習データを選択
という2つの重要なステップを踏んでいます。これにより、少ないデータで効率的に学習できるんですね。

この図は、モデル選択のプロセスを詳細に示しています。K-shotデータを使って、パフォーマンス、パープレキシティ(予測の不確実性)、そしてモデル間の多様性を考慮してモデルを選択しているんです。
4. Mixture-of-Experts(MoE):専門家の知恵を結集
この研究のもう一つの目玉が、MoEというアプローチです。これは、複数の「専門家」モデルを組み合わせて、より強力なシステムを作る方法です。
具体的には:
複数のLoRAモデルから最適な「専門家」を選択
これらの専門家を組み合わせてMoEシステムを構築
タスクに応じて適切な専門家を動的に選択
これにより、様々な知識や能力を持つ専門家チームのような振る舞いをするLLMが実現できるんです。

この図は、MoEシステムのアーキテクチャを示しています。複数のエキスパートモデルが組み合わされ、ルーターによって動的に選択されている様子がわかりますね。
5. データ選択の妙技:類似性と多様性のバランス
効率的な学習には、質の高いデータが欠かせません。研究者たちは、データ選択にも工夫を凝らしています:
類似性優先:K-shotデータに似たデータを優先的に選択
多様性考慮:意味的に重複するデータを除去
このバランスが絶妙なんです。タスクに関連する知識を効率的に学びつつ、過学習を防ぐことができます。

この図は、データ選択のプロセスを視覚化しています。K-shotデータを基準に、類似性の高いデータを選択しつつ、多様性も確保していることがわかります。
6. 実験結果:驚異の性能向上
研究チームは、様々なタスクでこの手法を検証しました。結果は驚くべきものでした:
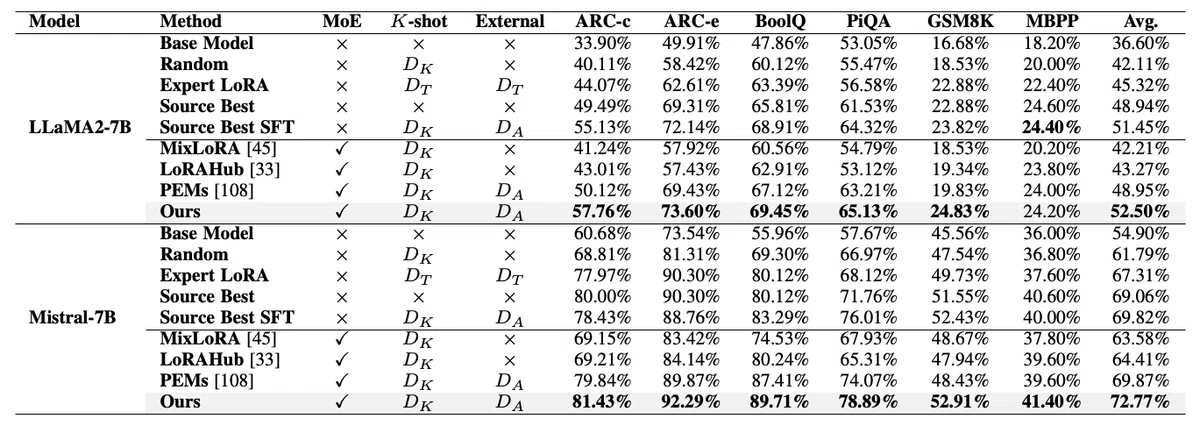
この表は、提案手法と他の手法を比較した結果を示しています。ARC、BoolQ、PiQA、GSM8K、MBPPなど、様々なタスクで大幅な性能向上が見られていますね。特に:
ARC-Challenge:約20%の性能向上
GSM8K(数学的推論):約8%の性能向上
MBPP(コーディング):約5%の性能向上
しかも、これらの改善は比較的少ない計算資源で達成されているんです。コスパ最高ですね!
7. 今後の展望:LLMの新時代へ
この研究は、LLMの未来に大きな可能性を示唆しています:
専門分野ごとのエキスパートLLMの実現
少ないデータと計算資源での効率的な学習
オープンソース知識の効果的な活用
今後は、より多様なタスクや大規模なモデルでの検証、さらなる効率化が期待されます。
まとめ:LLMの専門家時代の幕開け
この研究は、LLMの新しい可能性を切り開いたと言えるでしょう。少ないデータで効率的に専門家を育てる――この考え方は、AI技術の民主化にもつながる可能性があります。
皆さんも、この技術を使って自分専用のAIアシスタントを作る日が来るかもしれませんね。例えば、あなたの仕事や趣味に特化したLLMエキスパート。ワクワクしませんか?
AIの世界は日々進化しています。これからも最新の研究動向をキャッチアップして、皆さんにお届けしていきますね。では、また次回!