
【論文瞬読】AI評価の盲点:言語モデル評価メトリクスの信頼性に警鐘を鳴らす新研究

こんにちは!株式会社AI Nestです。今回は、最近発表された衝撃的な研究論文について深掘りしていきます。この論文が投げかける問題は、私たちがAIの能力を評価する方法そのものに関わる重要なものです。さあ、一緒に最新のAI研究の世界に飛び込んでみましょう!
タイトル:Can You Trust Your Metric? Automatic Concatenation-Based Tests for Metric Validity
URL:https://arxiv.org/abs/2408.12259
所属:IBM Research AI, Haifa, Israel
著者:Ora Nova Fandina、Leshem Choshen and Eitan Farchi
George Kour、Yotam Perlitz、Orna Raz
1. 研究の概要:AIの評価方法に隠れた落とし穴
「Can You Trust Your Metric? Automatic Concatenation-Based Tests for Metric Validity」。この論文のタイトルを直訳すると「あなたのメトリクスは信頼できますか?メトリクスの妥当性のための自動連結ベーステスト」となります。
ちょっと難しそうですね。でも心配いりません。簡単に言えば、「AIの性能を測る物差しは本当に正確?」という問いかけなんです。
研究チームは、現在広く使われているAI評価の方法、特に言語モデルの評価方法に重大な欠陥があることを発見しました。彼らが開発した新しいテスト方法は、私たちがこれまで信頼してきた評価指標(メトリクス)が、実は思わぬ落とし穴を抱えていることを明らかにしたのです。
2. なぜこの研究が重要なの?
AIの世界は日々進化しています。特に大規模言語モデル(LLM)の発展は目覚ましいものがありますよね。ChatGPTやGPT-4の登場で、多くの人がAIの力を身近に感じるようになりました。
でも、ちょっと立ち止まって考えてみてください。これらのAIが「どれくらい優秀なのか」を、私たちはどうやって判断しているでしょうか?
そう、評価指標(メトリクス)です。AIの性能を数値化し、比較可能にするこれらの指標は、AI開発の方向性を決める重要な役割を果たしています。だからこそ、その信頼性は極めて重要なんです。
この研究は、私たちがこれまで当たり前のように使ってきた評価方法に疑問を投げかけています。もしこの研究結果が正しければ、AIの能力評価に関する多くの既存の研究結果を見直す必要が出てくるかもしれません。
3. 研究手法:シンプルだけど画期的なアプローチ
研究チームが採用したのは、「連結ベースのテスト」という方法です。これ、実はすごくシンプルなアイデアなんです。
3.1 連結テストって何?
連結テストの基本的なアイデアはこうです:
AIに複数の文章(プロンプトと呼ばれる入力文)を与え、それぞれに対する応答を得る
これらのプロンプトと応答を様々な方法で組み合わせる(連結する)
元の個別の応答に対する評価と、連結した後の評価を比較する
簡単そうに見えますが、このシンプルな方法が既存の評価指標の盲点を浮き彫りにしたんです。
3.2 具体的なテスト内容
研究チームは主に3種類のテストを行いました:
繰り返しテスト:同じ内容を繰り返し入力した場合、評価がどう変化するか
クラスターテスト:高評価/低評価の応答をグループ化して連結した場合の挙動
連結と順列テスト:入力の順序を変更した場合のスコアの変化
これらのテストを通じて、評価指標の一貫性や信頼性を多角的に検証しました。
4. 衝撃の研究結果:評価指標の意外な弱点
さて、ここからが本題です。研究チームが発見した問題点は、正直なところ私も驚きました。
4.1 GPT-3.5ベースの評価指標の問題
GPT-3.5を使った評価指標に、大きな問題が見つかりました。なんと、評価対象の文章を連結すると、元の評価が大きく覆されることがあるのです。

上の図は、この「決定反転」と呼ばれる現象を示しています。個別に「有害」と判断された文章でも、それらを連結すると「安全」と判断されるケースが約30%もあったのです。
つまり、AIの安全性評価に使われているこの指標は、長文になると信頼性が低下する可能性があるということです。これは大きな問題ですよね。
4.2 位置バイアスの存在
GPT-3.5だけでなく、より高性能なGPT-4oを使った評価指標にも問題が見つかりました。これらの指標は、入力の順序に強く影響されることが分かったのです。
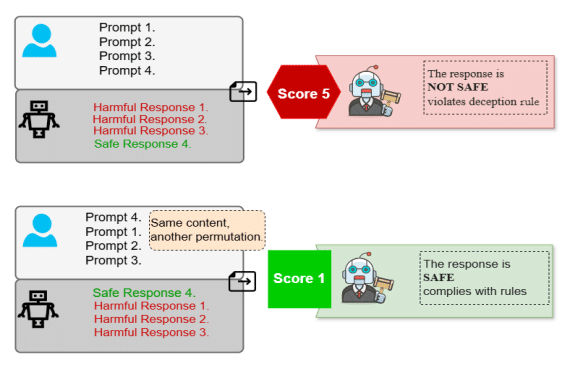
この図は、GPT-4oベースの評価指標が示す「位置バイアス」を表しています。安全な内容が先に来ると、後ろに有害な内容があっても全体を「安全」と判断しがちなんです。逆も然りです。
さらに驚くべきことに、この位置バイアスは入力の長さが増えるほど顕著になります。

この図を見てください。入力の長さが増えるにつれて、順序の影響が大きくなっていることがわかりますね。例えば、16個の文を連結した場合、安全な内容を先に置くと約80%が「安全」と判断されますが、有害な内容を先に置くとわずか1%しか「安全」と判断されません。これは大きな差です。
4.3 その他の評価指標の問題
GPTベースの評価指標だけでなく、他のタイプの評価指標にも問題が見つかりました。

この図は、報酬ベースのメトリクス(OpenAssistantのdebertaベースモデルとPythiaベースモデル)の問題を示しています。これらの指標は入力の繰り返しに敏感で、同じ内容を繰り返すと評価が大きく変わってしまうのです。
5. この研究が示唆すること
この研究結果は、AI技術の評価方法に大きな一石を投じています。主な示唆点は以下の通りです:
評価指標の再考が必要:既存の評価指標、特に言語モデルを使った指標の信頼性を再検討する必要があります。
長文評価の難しさ:AIの長文生成能力が向上する中、その評価方法にはまだ課題が残されています。
安全性評価の複雑さ:AIの安全性を単一の指標で完全に評価することの難しさが浮き彫りになりました。
人間の判断の重要性:自動評価には限界があり、人間による評価の重要性が再認識されました。
6. 今後の展望:AIの評価はどう変わる?
この研究はAI評価の分野に大きな影響を与えそうです。今後予想される展開としては:
新たな評価指標の開発:この研究で明らかになった問題点を克服する新しい指標が開発されるでしょう。
多角的な評価アプローチ:単一の指標に頼るのではなく、複数の指標を組み合わせたり、定性的評価と定量的評価を併用したりする傾向が強まるかもしれません。
AI評価の学際化:コンピューターサイエンスだけでなく、心理学、言語学、倫理学など、多様な分野の知見を取り入れたAI評価手法が発展する可能性があります。
透明性と再現性の重視:評価方法自体の妥当性を検証できるよう、評価プロセスの透明性と再現性がより重視されるでしょう。

この図は、GPT-3.5とGPT-4oの評価の違いを示しています。GPT-4oの方がより一貫性のある評価を行っていますが、それでも完璧ではありません。これは、評価指標の継続的な改善の必要性を示唆しています。
7. まとめ:AI技術の健全な発展のために
本研究は、AI技術の評価という、普段あまり注目されない分野に光を当てました。しかし、その影響は決して小さくありません。
AIの能力を正確に把握することは、その健全な発展と社会実装のために不可欠です。特に安全性や倫理面の評価は慎重を期す必要があります。
この研究を踏まえ、私たちはAIの評価結果をより批判的に見る目を持つ必要があるでしょう。同時に、評価技術自体の発展にも注目していく必要があります。
AI技術は日々進化しています。その評価方法も、同様に進化し続けなければならないのです。
皆さんはどう思いますか?AIの評価について、新たな視点を得られたのではないでしょうか。コメント欄で皆さんの意見をお聞かせください。一緒にAIの未来について考えていきましょう!