
【論文瞬読】3百万トークンを1 GPUで実現!InfiniteHiPが切り開く長文コンテキストの新時代

こんにちは!株式会社AI Nestです。今回は最新研究「InfiniteHiP: Extending Language Model Context Up to 3 Million Tokens on a Single GPU」をご紹介します。大規模言語モデル(LLM)の利用が進む中、長文コンテキストの扱いは従来から大きな課題でした。入力が長くなると、注意機構の計算量が急激に増加し、GPUメモリの消費も膨大になります。InfiniteHiPは、これらの問題に対して画期的な解決策を提供し、たった1枚のGPUで最大300万トークンの処理を可能にしました。
タイトル:InfiniteHiP: Extending Language Model Context Up to 3 Million Tokens on a Single GPU
URL:https://arxiv.org/abs/2502.08910
所属:Graduate School of AI, DeepAuto.ai
著者:Heejun Lee, Geon Park, Jaduk Suh, Sung Ju Hwang

KVキャッシュオフロード、モジュラー・プルーニング、
Paged block sparse attentionの各要素が整理されている
背景と関連技術
TransformerベースのLLMは、各トークン同士の相互関係を計算するため、入力シーケンスが長くなると計算量が二乗に増加し、メモリ負荷が非常に高くなります。これまでの研究では、以下のようなアプローチが試みられてきました。
FlashAttention2:計算の効率化とメモリ使用量の削減に成功しましたが、KVキャッシュの管理は十分ではありませんでした。
HiP AttentionやInfLLM:注意機構の計算対象を絞り込むためのプルーニング技術が導入され、不要な情報を削減する工夫がなされました。しかし、これらの手法は事前学習済みのRoPE(Rotary Positional Embedding)の限界により、長文コンテキストにおける位置情報の扱いで課題が残っていました。
InfiniteHiPは、これらの既存技術の弱点を克服するため、モジュラー階層型トークンプルーニングと動的RoPE調整、さらにKVキャッシュオフロードという3つの技術を統合しています。これにより、不要な計算を削減し、メモリ消費を大幅に抑えつつ、事前学習済みモデルの限界を超える性能を実現しています。
InfiniteHiPの技術解説
InfiniteHiPの革新は、主に以下の3つの技術要素に集約されます。
1. モジュラー階層型トークンプルーニング
InfiniteHiPは、入力シーケンスを固定サイズのチャンクに分割し、各チャンクごとに代表トークンを選出することで、注意計算の対象となるトークン数を大幅に削減します。このプロセスは階層的に実施され、各段階でより重要なトークンのみを次段階に引き継ぐ仕組みとなっています。
この技術により、従来必要であった全トークン間の計算を避け、効率的かつ高速な推論が可能となりました。
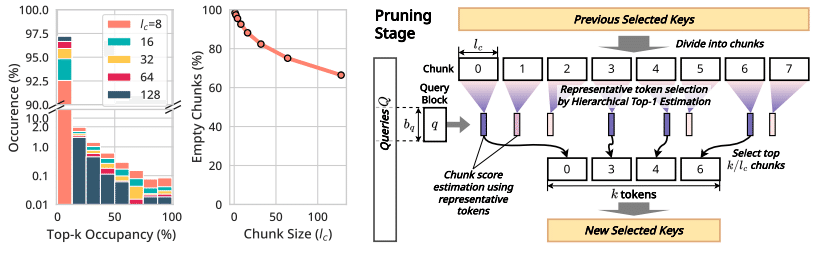
各階層での代表トークン選出とチャンクの絞り込みの流れが視覚的に説明されている
2. 動的RoPE調整
従来のRoPEは固定された範囲内でしか機能しなかったため、事前学習済みのモデルでは長文コンテキストに対して位置情報の正確な取り扱いが難しかったです。InfiniteHiPは、クエリとキーに対して動的にRoPEを調整する戦略を導入。これにより、従来の事前学習済みコンテキスト長を超える入力に対しても、モデルが正確な位置情報を保持できるようになっています。
3. KVキャッシュオフロード
KVキャッシュは、注意計算の効率化のために以前の計算結果を保持する重要な仕組みですが、長文ではそのサイズが膨大になります。InfiniteHiPは、使用頻度の低いKVキャッシュをホストメモリ(CPU側)にオフロードし、必要なときにのみGPUに読み込むことで、GPUメモリの使用量を大幅に削減しています。これにより、単一GPUでの大規模なコンテキスト推論が実現されています。

各技術がどのように連携して全体の性能向上に寄与しているかが示されている
実験結果と評価
InfiniteHiPの効果は、複数のベンチマークにより検証されています。以下はその主なポイントです。
推論速度の向上
Llama 3.1 8Bモデルを用いた実験では、従来手法に比べデコーディング速度が大幅に向上しています。特に、KVキャッシュオフロードと階層型プルーニングの組み合わせにより、計算負荷が大幅に軽減され、実用レベルの高速処理が可能となりました。メモリ効率の改善
従来のFlashAttention2と比較して、InfiniteHiPはVRAM使用量を大幅に削減。これにより、単一GPU上での大規模なコンテキスト処理が現実的になりました。精度の維持
長文コンテキスト処理においても、注意スコアのトップ‐k推定の精度が向上しており、従来の手法に匹敵するか、場合によってはそれ以上の性能を示しています。実験結果のグラフからも、コンテキスト長が拡大しても性能低下がほとんど見られないことが確認されます。

LongBenchや∞Benchにおける各手法の精度・速度比較が視覚的に示されている
さらに、各プルーニング段階の効果やRoPE調整の効果を定量的に示す分析も行われ、InfiniteHiPの優位性が実証されています。特に、トップ‐kトークンのリコール率や、デコーディング中の遅延低減効果は注目に値します。
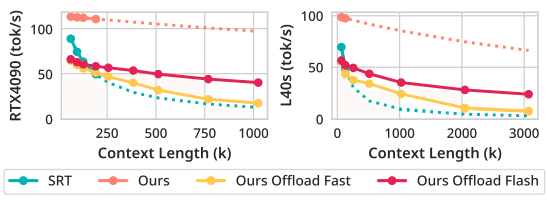
GPUとホストメモリ間でのデータ移動による処理速度改善が明確に表現されている
まとめと今後の展望
InfiniteHiPは、長文コンテキスト処理における従来の限界を打破する革新的な技術です。
以下の点が特に注目されます:
高速かつ効率的な処理:モジュラー階層型トークンプルーニングと動的RoPE調整により、従来の手法に比べ圧倒的なスループットと低レイテンシを実現。
GPUメモリの大幅な節約:KVキャッシュのホストメモリオフロードにより、単一GPUで非常に大規模なコンテキストを扱えるように。
実用性の高さ:実験結果から、長文コンテキストでの自然言語理解や生成タスクにおいて、精度と速度の両面で優れた性能を発揮していることが確認されました。
今後は、プリフィル段階のさらなる高速化やKVキャッシュの量子化・圧縮技術との組み合わせ、そしてタスクに応じた最適なモジュラー構成の自動調整など、さらなる研究が期待されます。InfiniteHiPは、LLMの実運用における新たな可能性を切り拓く技術として、大きな注目を集めることでしょう。
まとめ
今回ご紹介したInfiniteHiPは、これまでの大規模言語モデルが抱える長文コンテキスト処理の計算量とメモリ使用量の問題を、革新的な技術で解決しました。モジュラー階層型プルーニング、動的RoPE調整、そして効率的なKVキャッシュオフロードという三本柱により、1 GPUで最大300万トークンの入力に対しても高速かつ正確な推論が可能となっています。
今後、さらなる技術改良と実用化が進むことで、幅広いアプリケーションにおけるLLMの利用が一層加速することが期待されます。