
【論文瞬読】LLMの推論コストを68%削減!トークン予算を考慮した新フレームワークTALEの紹介

こんにちは!株式会社AI Nestです。大規模言語モデル(LLM)の推論能力は日々進化していますが、その一方で推論処理に必要なトークン数が増加し、コストが上昇するという課題があります。特に、Chain-of-Thought(CoT)のような高度な推論手法を使用する場合、その問題は顕著になります。今回は、この課題に対する新しいアプローチとして、トークン予算を考慮したLLM推論フレームワーク「TALE」を提案する研究を紹介します。
タイトル:Token-Budget-Aware LLM Reasoning
URL:https://arxiv.org/abs/2412.18547
所属:Nanjing University, Rutgers University, UMass Amherst
著者:Tingxu Han, Chunrong Fang, Shiyu Zhao, Shiqing Ma, Zhenyu Chen, Zhenting Wang

トークン予算管理の重要性
Chain-of-Thought推論の課題
Chain-of-Thought(CoT)推論は、LLMの性能を大きく向上させる手法として知られています。この手法は、問題を中間ステップに分解し、段階的に解決することで、より正確な答えを導き出すことができます。
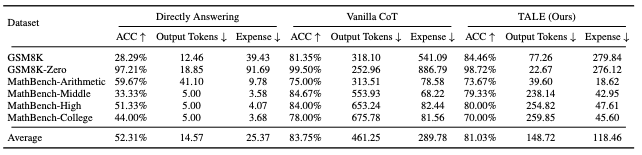
しかし、図1に示すように、詳細な中間ステップを生成するため、トークン使用量が大幅に増加してしまいます。これは単なるトークン数の問題だけではありません。計算リソースの使用量増加、推論時間の長期化、そして最終的には金銭的・環境的コストの上昇につながっています。
具体例を見てみましょう。単純な算術問題において、直接回答では15トークンしか使用しないのに対し、従来のCoTでは258トークンも使用します。これは実に17倍以上のトークン消費です。一方、本研究で提案するトークン予算を考慮したCoTでは86トークンまで削減できており、効率的な推論を実現しています。
トークン弾性現象の発見

研究チームは「トークン弾性」と呼ばれる興味深い現象を発見しました。これは、設定したトークン予算が小さすぎる場合、かえって実際のトークン使用量が増加してしまう現象です。
例えば、あるタスクで50トークンという予算を設定した場合、LLMは効率的に推論を行い、実際のトークン使用量も適度に抑えられます。しかし、同じタスクで10トークンという極端に小さな予算を設定すると、LLMは予算制約に対応しようとして却って冗長な出力を生成し、結果として157トークンも消費してしまうことがあります。
この発見は、単純にトークン予算を削減すれば良いわけではなく、タスクの複雑さに応じた適切な予算設定が重要であることを示唆しています。
TALEフレームワークの提案
フレームワークの設計思想
TALEは、以下の考えに基づいて設計されたフレームワークです:
第一に、すべての推論タスクに同じトークン予算を適用するのではなく、タスクの複雑さに応じて動的に予算を割り当てます。これにより、簡単なタスクには少ないトークンを、複雑なタスクにはより多くのトークンを効率的に配分することができます。
第二に、トークン予算の設定において、先述のトークン弾性現象を考慮し、最適な予算範囲を見つけ出します。これは単なる予算の最小化ではなく、実際のトークン使用量と推論精度のバランスを取ることを意味します。
実装と評価手法
TALEの実装では、予算見積もりのための複数のアプローチが検討されています。その中でもゼロショット方式は、追加の学習なしで既存のLLMの能力を活用できる点で注目に値します。
人間が数学の問題を見たとき、その解答にどれくらいの時間や労力が必要かを直感的に判断できるように、LLMも問題の複雑さを判断し、適切なトークン予算を見積もることができます。この能力を活用することで、効率的な推論が可能となります。
実験結果と考察
実験結果は非常に印象的です。平均して68.64%ものトークン使用量削減を達成し、しかも精度の低下は5%未満に抑えられています。これは、推論の質を大きく損なうことなく、大幅なコスト削減が可能であることを示しています。

さらに興味深いことに、TALEの効果は特定のLLMに限定されません。GPT-4、Claude、Yiなど、異なるアーキテクチャを持つ複数のLLMで効果が確認されています。これは、TALEの手法が普遍的に適用可能であることを示唆しています。
まとめと今後の展望
本研究は、LLMの推論プロセスにおけるトークン使用量の最適化という重要な課題に対し、具体的な解決策を提示しました。TALEフレームワークの登場により、コスト効率の高いLLM推論の実現が現実のものとなっています。
今後の展望として、以下のような発展が期待されます:
より複雑なタスクへの適用については、長文生成や創造的な作業など、推論の道筋が明確でないタスクでの効果検証が必要でしょう。また、異なるLLMアーキテクチャでの検証をさらに進めることで、フレームワークの一般化可能性をより詳細に理解することができます。
実用面では、ビジネスアプリケーションにおけるコスト削減効果の定量化や、リアルタイム性が要求される場面での性能評価など、実践的な検証も重要となってくるでしょう。
TALEの登場は、LLMの実用化における大きな課題の一つであるコスト効率の問題に対する重要な一歩といえます。今後の発展と実用化が大いに期待される研究といえるでしょう。