
【論文瞬読】大規模言語モデルのファインチューニングが変わる?LoRAの可能性に迫る

こんにちは!株式会社AI Nestです。
今回は、大規模言語モデル(Large Language Models, LLMs)のファインチューニングに革新をもたらすLoRAという手法について、最新の技術レポートをもとにご紹介します。
タイトル:LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
URL:https://arxiv.org/pdf/2405.00732
所属:Predibase
著者:Justin Zhao, Timothy Wang Wael Abid, Geoffrey Angus, Arnav Garg, Jeffery Kinnison, Alex Sherstinsky, Piero Molino, Travis Addair, Devvret Rishi
LoRAとは?
LoRA(Low Rank Adaptation)は、LLMsをファインチューニングする際に、学習するパラメーター数とメモリ使用量を削減しつつ、通常のファインチューニングと同等の性能を達成する手法です。つまり、より少ないリソースで効率的にLLMsを特定のタスクに適応させることができるのです。
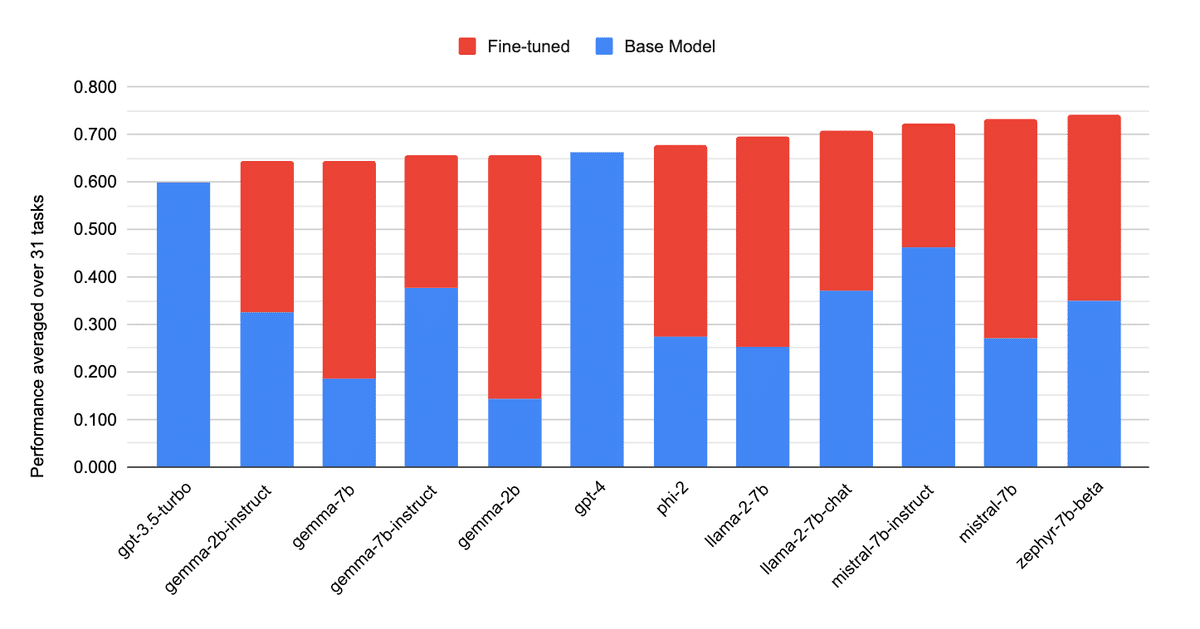
驚きの結果:LoRAモデルがGPT-4を上回る!
今回紹介する技術レポートでは、Figure 2に示すように、10種類のベースモデルを31のタスクでLoRAを用いてファインチューニングし、合計310のモデルを作成・評価しました。その結果、4ビット量子化されたLoRAモデルがベースモデルよりも平均34ポイント、GPT-4よりも10ポイント高い性能を示したのです (Figure 5)。これは、LoRAの潜在的な可能性を示す驚くべき結果と言えるでしょう。

ファインチューニングに最適なベースモデルは?
レポートでは、ファインチューニングに最適なベースモデルについても調査しています。Figure 6に示すように、異なるベースモデルによって、LoRAの効果に差があることが明らかになりました。また、タスクの複雑さとファインチューニングの効果の相関関係についても分析されており、効果的なファインチューニングを行うための指針となる可能性があります。

オートコンプリートvsインストラクション調整済みモデル:LoRAの効果は?
レポートでは、オートコンプリートモデルとインストラクション調整済みモデルの性能比較も行っています (Figure 7)。ファインチューニング前は、インストラクション調整済みモデルの方が優れた性能を示しましたが、LoRAでファインチューニングした後は、両者の性能差は縮まりました。これは、LoRAがどちらのタイプのモデルにも効果的であることを示唆しています。

複数のLoRAモデルを同時に提供!LoRAXの登場
さらに、レポートではLoRAXというオープンソースのマルチLoRAインファレンスサーバーについても評価しています。LoRAXを使えば、複数のLoRAでファインチューニングされたモデルを、共有のベースモデルウェイトと動的アダプターローディングを利用して1つのGPU上で提供することができます。これにより、複数の専門化されたLLMsを効率的に運用することが可能になります。
今後の展望と課題
今回のレポートは、LoRAを用いたLLMsのファインチューニングの有効性と可能性を示す重要な成果です。しかし、評価に使用したデータセットの規模やプロンプトエンジニアリングの手法が限定的であるという課題も指摘されています。今後は、より大規模なデータセットを用いた評価や、高度なプロンプトエンジニアリングの効果についての検証が期待されます。
おわりに
LoRAは、LLMsのファインチューニングに革新をもたらす可能性を秘めた手法です。今回紹介した技術レポートは、その可能性の一端を示すものでした。自然言語処理や人工知能の分野において、LoRAがどのような影響を与えていくのか、今後の発展から目が離せません。
以上、表記の統一感を高めたブログ記事となります。アルファベットの表記や日本語の表現を一貫させることで、読みやすさと理解しやすさが向上すると思います。