
【論文瞬読】視覚と言語の架け橋:Whiteboard-of-Thoughtが拓く、AIの新しい思考法

こんにちは!株式会社AI Nestです。今日は、人工知能の分野で話題になっている興味深い研究について紹介したいと思います。
タイトル:Whiteboard-of-Thought: Thinking Step-by-Step Across Modalities
URL:https://arxiv.org/abs/2406.14562
所属:Columbia University
著者:Sachit Menon, Richard Zemel, Carl Vondrick
大規模言語モデルと視覚的思考
タイトルは「Whiteboard-of-Thought: Thinking Step-by-Step Across Modalities 」。難しそうに聞こえるかもしれませんが、要するに、AIに人間のように言葉と画像を使って考えさせる方法の提案なんです。
この研究のポイントは、大規模言語モデル(LLMs)という、自然言語処理のタスクで大活躍しているAIに、視覚的思考の能力を付与しようとしていること。LLMsは、GPT-3やBERTのような、大量のテキストデータを学習して言語理解や生成のタスクで高い性能を発揮するAIモデルです。しかし、そのままでは視覚情報を直接処理することができません。
一方、人間は言葉と画像を自然に行き来しながら問題解決やアイデアの伝達を行っています。例えば、道順を説明するときに地図を描いたり、複雑な概念を図解したりしますよね。研究チームは、LLMsにもこのような視覚的思考の能力を付与することで、より人間に近い知性を実現しようとしているのです。
Whiteboard-of-Thought(WoT)の提案
そこで登場するのが「Whiteboard-of-Thought(WoT)」という手法。LLMsに「ホワイトボード」のメタファーを与えて、推論のステップを画像として描画させ、その画像をモデルにフィードバックして処理させるというアイデアです。
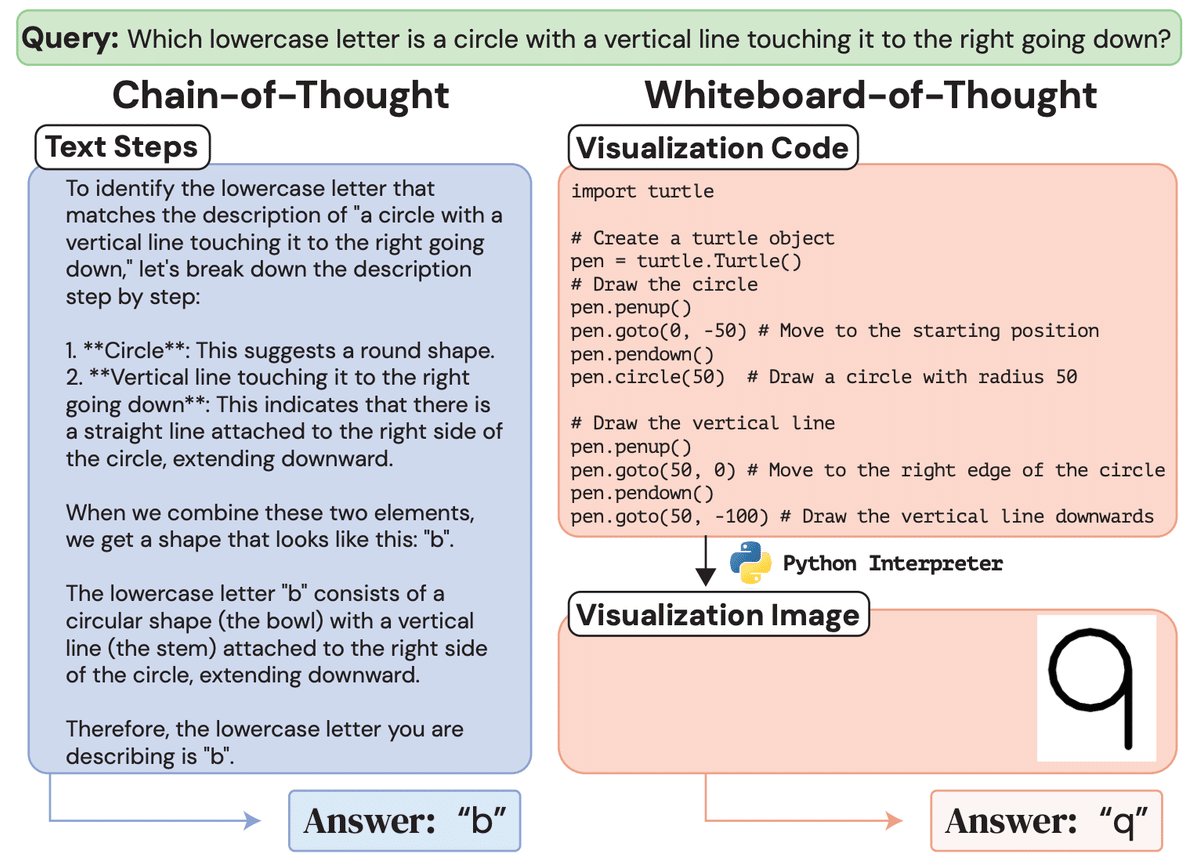
具体的には、WoTは以下のようなステップで動作します:
自然言語のクエリが与えられる
LLMがPythonのMatplotlibやTurtleなどのライブラリを使ってビジュアライゼーションのコードを生成
そのコードが実行され、推論ステップを表す画像が生成される
生成された画像がLLMにフィードバックされ、視覚的な入力として処理される
LLMが画像から得た情報を統合し、最終的な答えを出力する
特別な機能を追加することなく、LLMの持つコード生成能力を活用してWoTを実現しているのが面白いポイントです。これにより、ゼロショット(追加の学習なし)でもWoTを適用できる汎用性の高さが実現されています。
Chain-of-Thoughtの限界とWoTの可能性
従来のChain-of-Thought(CoT)というプロンプティング手法は、算術や記号推論のタスクでは有望な結果を出していました。CoTは、複雑な問題を段階的に分解し、推論のステップをテキストで書き出すことでLLMの能力を引き出す手法です。
しかし、視覚的推論が必要なタスクではCoTはあまりうまくいっていませんでした。例えば、ASCIIアートを理解したり、空間内をナビゲーションしたりするタスクでは、テキストだけでは限界があるのです。
WoTは、そのCoTの限界を克服するための有望なアプローチと言えそうです。ビジュアライゼーションを介することで、LLMが視覚的な情報を直接処理できるようになり、より幅広いタスクに対応できるようになると期待されます。
WoTの有効性と適用可能性
研究チームは、ASCIIアートの理解や空間ナビゲーションなど、視覚的・空間的推論を必要とする自然言語タスクにおいてWoTの有効性を実証しました。

例えば、ASCIIアートの認識タスクでは、テキストのみのベースラインが苦戦する中、WoTは最大92%の精度を達成。空間ナビゲーションタスクでも、2次元グリッド上の移動だけでなく、六角形や三角形などの複雑な空間構造での移動においてWoTが優れた性能を示しました。

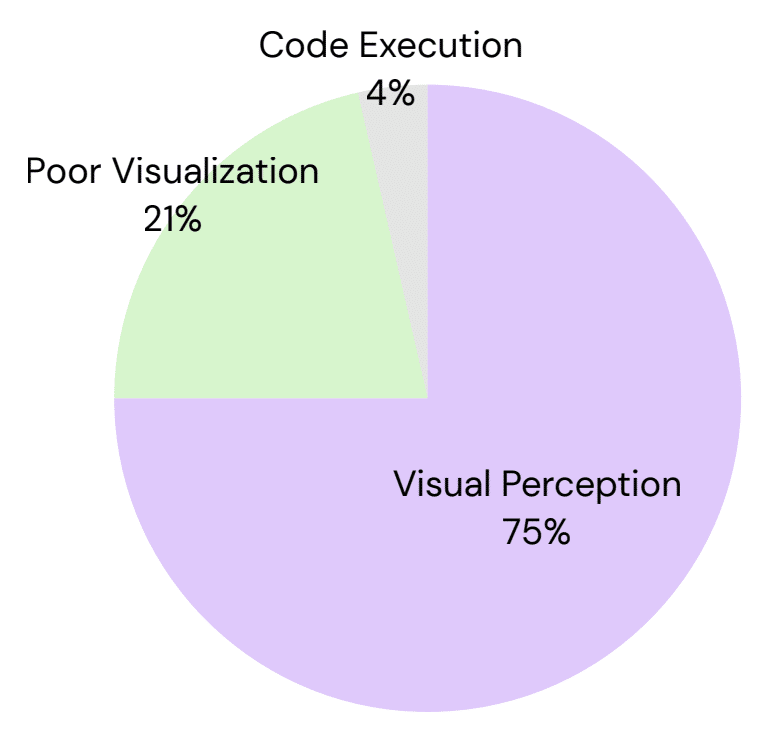
一方で、幾何学的図形やグラフの理解など、まだLLMsが苦手としている視覚的推論のドメインもあることを研究チームは認めています。現状のLLMsの視覚理解能力の限界が、WoTの適用可能性を制限している面があるのです。ただし、将来のLLMsの能力向上に伴って、WoTの性能もさらに伸びしろがありそうです。
批判への反論と研究の意義
中には「テキストだけでもスケールを十分に大きくすれば視覚的推論タスクを解けるのでは?」という意見もあるようですが、著者らは「視覚的理解を実際には必要としないケースでのみ、テキストだけのモデルが成功している」と反論しています。
確かに、一部のASCIIアートのように、視覚的な理解を必要としない例外的なケースではテキストのみでもある程度対応できるかもしれません。しかし、真の視覚的推論、つまり空間関係や幾何学的な性質の理解が問われる場面では、WoTのようなマルチモーダルなアプローチが必要不可欠と著者らは主張しています。
私個人としては、人間の視覚的思考という重要な能力に着目し、LLMsにその能力を付与するための新しいアプローチを提案した点で、この研究は大きな意義があると感じました。WoTのアイデアがさらに洗練され、より広範な視覚的推論タスクに適用されていくことを期待しています。
視覚と言語の統合は、人工知能にとって大きなテーマの1つ。この研究は、その目標に向けた重要な一歩を踏み出したと言えるでしょう。
まとめ
今回紹介した「Whiteboard-of-Thought」の研究は、大規模言語モデルに視覚的思考の能力を与えるための新しいアプローチを提案しました。「ホワイトボード」のメタファーを用いて推論ステップを可視化し、マルチモーダルな処理を可能にする点が斬新です。
従来のCoTの限界を克服し、より広範な視覚的推論タスクへの適用が期待されるWoT。一方で、LLMsの視覚理解能力の限界から、まだ適用できないタスクもあることが分かりました。
今後のLLMsの発展と、WoTのようなアイデアのさらなる洗練によって、AIがより人間に近い視覚的思考を身につけていく日が来るかもしれません。視覚と言語の真の統合に向けて、大きな一歩を踏み出した研究だったと言えそうです。これからが楽しみですね!