
【論文瞬読】Qwen2.5:18兆トークンで進化したAIモデルファミリーの全貌

こんにちは!株式会社AI Nestです。2024年12月、Alibaba CloudのQwenチームから新たな大規模言語モデル「Qwen2.5」が発表されました。本記事では、この技術報告書を詳しく解説していきます。
Qwen2.5は、多様なニーズに対応する包括的な言語モデルシリーズとして注目を集めています。特に注目すべきは、事前学習データを18兆トークンにまで拡大し、様々な専門分野での性能を大きく向上させた点です。
タイトル:Qwen2.5 Technical Report
URL:https://arxiv.org/abs/2412.15115
所属:Qwen Team
著者:An Yang, Baosong Yang, Beichen Zhang, …etc

図1は、Qwenシリーズの進化における事前学習データのスケーリング効果を示しています。3兆トークンから7兆トークン、そして18兆トークンへと拡大することで、特に数学や専門知識を要する領域での性能が飛躍的に向上していることがわかります。
モデルファミリーの全体像
Qwen2.5は、エッジデバイスからクラウドまで、様々な用途に対応できるよう設計されています。
オープンウェイトモデル群
まず、パラメータ数の異なる7つのモデルが用意されています:
小規模モデル(エッジデバイス向け)
Qwen2.5-0.5B:最小構成ながら、基本的なタスクをこなせる性能を持つ
Qwen2.5-1.5B:モバイルデバイスでの実用に適したバランスの取れたモデル
Qwen2.5-3B:中規模タスクに対応可能な新しいサイズ
中規模モデル(一般用途向け)
Qwen2.5-7B:コスト効率の高い汎用モデル
Qwen2.5-14B:性能とリソースのバランスが取れた中核モデル
大規模モデル(高性能用途向け)
Qwen2.5-32B:高度なタスクに対応可能な大規模モデル
Qwen2.5-72B:最高性能を誇るフラッグシップモデル
これらすべてのモデルには、命令調整版(Instruct)と量子化バージョンが提供されており、用途に応じて選択できます。
APIサービス向けモデル
クラウドサービスとして、2つの特別なモデルが提供されています:
1.Qwen2.5-Turbo
応答速度を重視したモデルで、以下の特徴があります:
最大100万トークンの長文処理が可能
効率的な推論処理による高速レスポンス
コストパフォーマンスに優れた設計
2.Qwen2.5-Plus
最高性能を追求したモデルで、以下の特徴を持ちます:
GPT-4レベルの性能を目指した設計
高度な推論能力と専門知識
複雑なタスクへの優れた対応能力
技術的イノベーション
データ品質の徹底的な向上
Qwen2.5の最大の特徴は、データ品質へのこだわりです。以下の方法で、より良い学習データを実現しています:
1.データフィルタリングの改善
従来のQwen2モデルを評価器として使用し、多次元的な品質評価を実施。これにより、高品質なデータのみを選別しています。特に多言語データの評価能力が向上し、より正確なフィルタリングが可能になりました。
2.専門分野データの統合
Qwen2.5-MathとQwen2.5-Coderの学習データを事前学習段階から統合することで、数学的推論とコーディング能力を大幅に向上させています。これらの専門データセットは、それぞれの分野で最先端の性能を達成するために不可欠でした。
3.合成データの品質向上
Qwen2-72B-InstructとQwen2-Math-72B-Instructを活用して高品質な合成データを生成。さらに、専用の報酬モデルで厳密にフィルタリングすることで、より高品質なデータセットを実現しています。
アーキテクチャの最適化
モデルアーキテクチャでは、以下の重要な技術を採用しています:
Grouped Query Attention(GQA)
キャッシュの効率的な利用を実現
推論速度の向上に貢献
メモリ使用量の最適化
Rotary Positional Embeddings(RoPE)
位置情報の効果的な符号化
長文処理能力の向上
より自然な文脈理解の実現
これらの技術により、モデルの基本性能を損なうことなく、効率的な処理を実現しています。
長文処理能力の飛躍的向上
Qwen2.5シリーズでは、長文処理能力を大幅に強化しています:
段階的な学習プロセス
基本学習:4,096トークンでの初期学習
拡張学習:32,768トークンまでのコンテキスト長での学習
特殊モデル:Qwen2.5-Turboは最大262,144トークンまで対応
実装技術
YARNによる位置埋め込みの拡張
Dual Chunk Attention(DCA)による効率的な注意機構
スパース注意機構による推論速度の最適化

図3は、様々なハードウェア構成でのTime To First Token(TTFT)を示しています。スパース注意機構の導入により、3.2から4.3倍の高速化を達成しています。
性能評価の詳細
ベンチマーク評価
Qwen2.5は、多岐にわたるベンチマークで評価されています:
一般的なタスク
MMLU:一般知識と理解力の評価
BBH:推論能力の評価
TruthfulQA:事実性の評価
専門的なタスク
数学:MATH、GSM8K
コーディング:HumanEval、MBPP
長文理解:RULER、LV-Eval
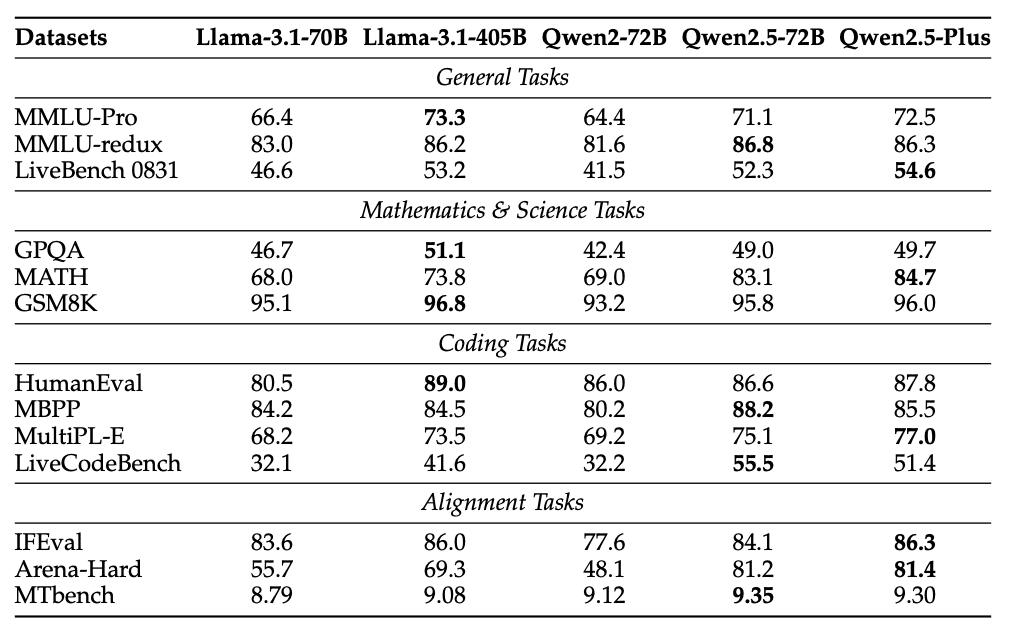
表6が示すように、Qwen2.5-72B-InstructとQwen2.5-Plusは、多くのベンチマークで既存モデルを上回る性能を示しています。特筆すべきは、パラメータ数で5倍の差があるLlama-3-405B-Instructと競争可能な性能を達成している点です。
実用的な性能評価
実際の使用シーンを想定した評価も行われています:
長文処理性能
100万トークンのパスキー検索タスクで100%の精度を達成
スパース注意機構により、計算負荷を12.5倍削減
実用的な応答速度を維持
多言語処理能力
70以上の言語での基本的なタスク処理
文化的なニュアンスの理解
クロスリンガル転移学習の効果
まとめと今後の展望
Qwen2.5は、以下の点で大きな進展を示しています:
1.データの質と量
18兆トークンの高品質データによる事前学習
専門分野データの効果的な統合
厳密なフィルタリングによる品質管理
2.アーキテクチャ改善
効率的な注意機構の実装
長文処理能力の大幅な強化
スパース計算による高速化
3.実用性の向上
多様なモデルサイズの提供
オープンソースと商用APIの両立
柔軟なデプロイメントオプション
今後の展開として、以下の方向性が示されています:
4.マルチモーダル機能の拡張
画像や音声との統合
クロスモーダル理解の向上
5.推論能力の更なる向上
計算リソースの効率的なスケーリング
より深い思考プロセスの実現
6.基盤モデルの堅牢性向上
より広範なデータソースの活用
評価方法の改善と拡充
Qwen2.5は、学術研究と産業応用の両面で重要な進展を示す成果といえます。特に、モデルの規模や用途に応じた柔軟な選択肢を提供している点は、実用的な観点から高く評価できます。今後のバージョンアップや派生モデルの開発にも、大いに期待が持てます。