
【論文瞬読】インターネットスラングをマスターするAI:SLANGベンチマークとFOCUSアプローチ

こんにちは、みなさん!株式会社AI Nestです。
今回は、自然言語処理の世界で話題になっている研究論文を紹介します。タイトルは「SLANG: New Concept Comprehension of Large Language Models」。インターネット上で急速に進化する言語に対する大規模言語モデル(LLM)の適応力を高めるための、革新的なアプローチが提案されているんです。
タイトル:SLANG: New Concept Comprehension of Large Language Models
URL:https://arxiv.org/abs/2401.12585
所属:CAS Key Laboratory of AI Security, Institute of Computing Technology, Chinese Academy of Sciences, University of California, Los Angeles, University of Chinese Academy of Sciences
著者:Lingrui Mei, Shenghua Liu, Yiwei Wang, Baolong Bi, Xueqi Cheng
🤔 LLMの抱える課題とは?
LLMは、GPTシリーズに代表されるような、大量のテキストデータで学習した強力なモデルです。しかし、そのトレーニングデータは静的なものが多く、インターネット上で日々生み出される新しい言葉やミームに対応するのが難しいという問題があります。「yeet(投げる)」や「sus(suspicious の略)」といった言葉は、ソーシャルメディアやオンラインゲームで頻繁に使われていますが、LLMはこれらを正しく理解できないことが多いんです。
また、LLMは表面的なパターンに基づいて意思決定を行う傾向があります。つまり、文脈や言外の意味を汲み取ることが苦手なんですね。例えば、以下の図に示すように、Chain-of-Thought(CoT)アプローチでは、フレーズの字義通りの解釈にとどまっているのに対し、FOCUSアプローチ(詳細は後述)では、比喩やより深い意味を捉えられていることがわかります。そのため、人間の指示を正確に解釈・実行することが困難だったりします。

💡 SLANGベンチマークとFOCUSアプローチ
この研究では、SLANGベンチマークとFOCUSアプローチという2つの革新的な方法が提案されています。
SLANGベンチマーク
SLANGベンチマークは、UrbanDictionaryから収集したインターネットスラングやミームに関するデータセットです。UrbanDictionaryは、ユーザー投稿型のオンラインスラング辞書で、最新の言語トレンドを反映しているんです。
研究チームは、2022年1月以降に追加された単語を選び、すでにLLMのトレーニングデータに含まれている可能性の高いフレーズを除外しました。また、ユーザー評価(アップ投票とダウン投票)を利用して、データセットの品質と網羅性を確保しています。下記の図は、データセットのエントリーにおけるアップ投票数の分布を示しており、データクリーニング前後の分布の変化を直接比較できます。

FOCUSアプローチ
FOCUSアプローチは、因果推論を用いてLLMの新概念理解力を高めるための手法です。下の図は、LLMが新しいフレーズを解釈する際の構造因果モデル(SCM)を示しています。変数XとWは、ユーザーの複雑な意図や思考を表しており、LLMがこれらの側面を直接把握するのは困難であることを示唆しています。因果関係を分析することで、従来の相関ベースの学習を超えて、モデルの予測能力を向上させるんです。
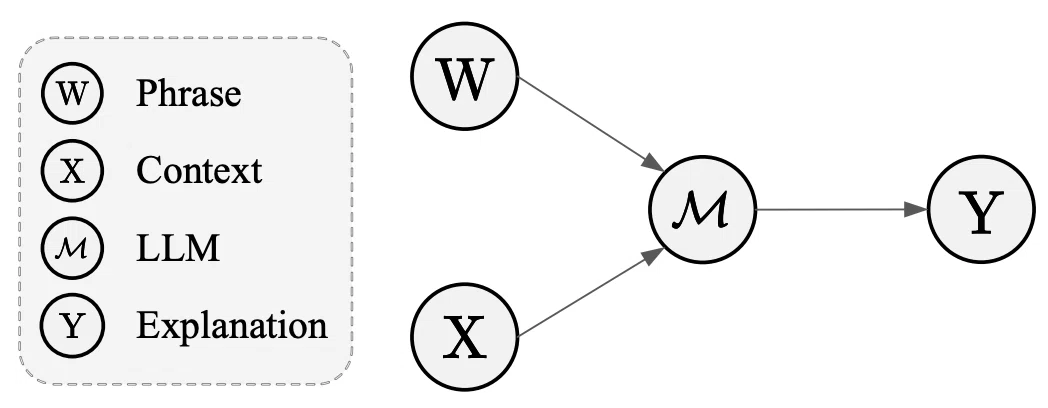
FOCUSアプローチでは、言語要素とその解釈結果の因果関係に着目し、言語パターンを体系的に分析・解釈します。この過程は、以下の図に示すようなSCM分析により表現されています。
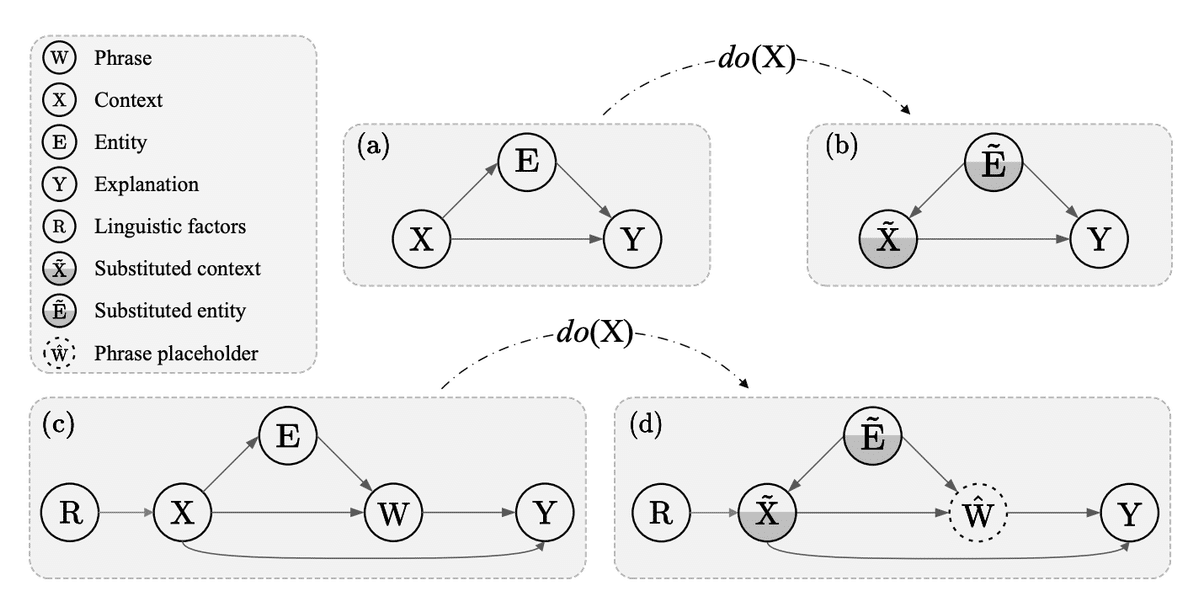
このアプローチは、4つのステージからなるパイプラインで構成されています(下記を参照)

Direct Inquiry(DI):使用例(コンテキスト)とフレーズをモデルに入力し、直接的な影響を評価。
Masked Entity Inquiry(MEI):フレーズをマスクしてコンテキストから意味を抽出。
Entity Replacement Inquiry(ERI):コンテキスト内のエンティティを変更し、解釈の変動を評価。
Synthesis(SY):DI、MEI、ERIの知見を統合し、多次元的な視点を提供。
この方法により、LLMは言語の動的な性質をより細やかに把握できるようになります。
🧪 実験結果と考察
研究チームは、GPT-3.5とGPT-4を用いてFOCUSアプローチの有効性を検証しました。表1と表2は、それぞれ事実データセットと反実データセットにおける各手法の性能結果を示しています。FOCUSアプローチがすべての指標で他の手法を上回っていることがわかります。


また、表3に示すアブレーション実験の結果から、FOCUSアプローチの各コンポーネントが性能向上に重要な役割を果たしていることがわかります。

例えば、GPT-4にFOCUSを適用した場合、F1スコアが0.4532、精度が0.4598、再現率が0.4551になりました。これは、理解力と適応力において、従来の方法を上回る結果です。
ただし、データセットの多様性や言語の一般化可能性については、さらなる検討が必要だと著者らは指摘しています。また、英語以外の言語や形態的に豊かな言語への適用可能性についても、今後の研究課題として挙げられています。
🎉 まとめ
この研究は、自然言語処理分野における重要な課題に取り組んだ意欲的な研究です。提案されたSLANGベンチマークとFOCUSアプローチは、LLMのインターネットスラング理解力を高める上で大きな可能性を秘めていると言えるでしょう。
今後は、データセットの拡充や他言語への適用など、より幅広い文脈での検証が期待されます。この研究が、自然言語処理分野の発展に寄与することを願っています!