
【論文瞬読】大規模言語モデルの信頼性向上への挑戦:内部の確信度とユーザー知覚のギャップを解消する

こんにちは!株式会社AI Nestです。
今日は、大規模言語モデル(LLMs)の信頼性に関する興味深い研究を紹介したいと思います。
タイトル:The Calibration Gap between Model and Human Confidence in Large Language Models
URL:https://arxiv.org/abs/2401.13835
所属:Department of Cognitive Sciences and Department of Computer Science, University of California, Irvine,
著者:Mark Steyvers, Heliodoro Tejeda, Aakriti Kumar, Catarina Belem, Sheer Karny, Xinyue Hu, Lukas Mayer, Padhraic Smyth
LLMsの信頼性の問題
LLMsは、自然言語処理の分野で大きな進歩を遂げ、様々な応用が期待されています。しかし、その信頼性については、まだ多くの課題が残されています。LLMsが生成する回答は、時として不正確であったり、誤解を招くような説明を伴っていたりすることがあるのです。
これは、LLMsが膨大なデータから学習するため、学習データに含まれる偏りやノイズの影響を受けやすいことが一因です。また、LLMsの意思決定プロセスがブラックボックス化されていることも、信頼性の問題に拍車をかけています。
キャリブレーションギャップに着目
そこで、今回紹介する論文では、LLMsのモデルコンフィデンス(内部的な確信度)と、ユーザーがLLMsの説明から知覚するヒューマンコンフィデンス(人間の確信度)の乖離に着目しました。この乖離を「キャリブレーションギャップ」と呼んでいます。

研究チームは、このギャップを定量的に評価するために、図に示すような実験を行いました。まず、LLMsに複数選択式の質問を与え、各選択肢に対するモデルの内部的な確信度を得ます。次に、最も確率の高い回答を選択し、その回答の説明を生成します。最後に、ユーザーに質問とLLMsの説明を提示し、モデルの回答が正しい確率を推定してもらいます。
この実験により、LLMsの内部的な確信度とユーザーの知覚する確信度の差を定量的に評価することができます。
実験で明らかになったこと
研究チームは、複数選択式の質問に対するLLMsの回答と説明を用いた実験を行いました。その結果、以下のような興味深い知見が得られました。

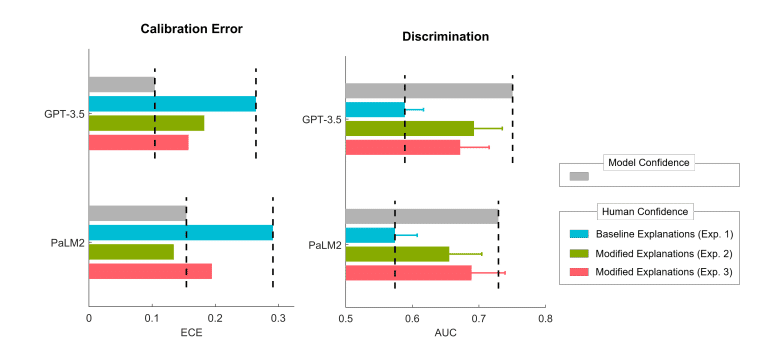
LLMsのデフォルトの説明文では、ユーザーはLLMsの信頼性を過大評価する傾向がある
図1の青色の部分から、デフォルトの説明文を使用した場合、ユーザーの確信度が高くなっていることがわかります。これは、ユーザーがLLMsの信頼性を過大評価していることを示唆しています。
説明文の表現を操作することで、キャリブレーションギャップを縮小できる
図1の緑色とピンク色の部分から、説明文の表現を修正することで、ユーザーの確信度が変化することがわかります。これは、LLMsの説明文を適切に調整することで、ユーザーの知覚をモデルの内部的な確信度に近づけることができることを示しています。
LLMsの説明における不確実性の明示的なコミュニケーションが重要である
図2から、説明文を修正することで、ユーザーの確信度とモデルの確信度のギャップが縮小されていることがわかります。実験結果から、LLMsが自身の確信度を明示的に伝えることが、ユーザーの適切な信頼性評価につながることが示唆されました。
また下記の図は、モデルの確信度とユーザーの確信度の関係を、Expected Calibration Error(ECE)とArea Under the Curve(AUC)という2つの指標で評価しています。これらの指標からも、説明文の修正がキャリブレーションギャップの縮小に効果的であることが確認できます。

LLMsの信頼性向上に向けて
この研究は、LLMsの信頼性向上に向けた重要な一歩を示しています。LLMsの内部的な確信度をユーザーに適切に伝えることで、ユーザーはモデルの信頼性をより正確に判断できるようになります。
ただし、この研究は複数選択式の質問に限定されているため、他のタスクへの一般化可能性については更なる検証が必要です。また、説明文の修正方法についても、より洗練された手法の開発が望まれます。
さらに、LLMsの信頼性の問題は、AIの倫理的・社会的な側面とも密接に関連しています。LLMsが生成する情報が社会に与える影響を考慮し、責任あるAIの開発を進めていく必要があるでしょう。
まとめ
LLMsの信頼性は、AIシステムの社会実装において重要な課題です。今回紹介した研究は、LLMsの内部的な確信度とユーザーの知覚する確信度の乖離に着目し、その解消方法を提案しました。この研究は、LLMsの信頼性向上に向けた新しい視点を提供し、今後のAI研究の発展に寄与すると期待されます。今後もLLMsの信頼性向上に注目していきましょう!