
【論文瞬読】OCRの新時代:OCRBench v2で見えてきた言語モデルの実力と課題

はじめに
こんにちは!株式会社AI Nestです。
近年、GPT-4VやClaude 3といった大規模マルチモーダルモデル(LMM)の登場により、画像中のテキストを認識し理解する能力は飛躍的に向上しました。しかし、これらのモデルは本当にOCR(光学文字認識)をマスターしたのでしょうか?
タイトル:OCRBench v2: An Improved Benchmark for Evaluating Large Multimodal Models on Visual Text Localization and Reasoning
URL:https://arxiv.org/abs/2501.00321
所属:Huazhong University of Science and Technology, University of Adelaide, South China University of Technology, ByteDance
著者:Ling Fu, Biao Yang, Zhebin Kuang, 他

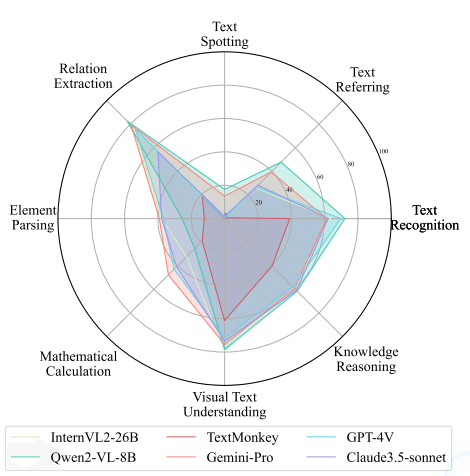
図1が示すように、最新のLMMsでも、テキストの位置特定や手書き文字の認識、数学的推論といった高度なタスクでは依然として課題が残されています。本論文では、これらの課題を系統的に評価するための新しいベンチマーク「OCRBench v2」を提案しています。
OCRBench v2:包括的な評価フレームワーク

OCRBench v2は、以下の8つのコア能力を評価します:
テキスト認識:基本的な文字認識能力
テキスト参照:テキストの位置特定
テキストスポッティング:テキストの検出と認識
関係抽出:テキスト間の関係性理解
要素解析:表やグラフなどの構造的理解
数学的計算:数式や計算問題の処理
視覚的テキスト理解:文脈を考慮したテキスト理解
知識推論:背景知識を活用した推論
特筆すべき特徴として:
31種類の多様なシナリオ
23の具体的なタスク
10,000以上の人間が検証したQ&Aペア
複数の評価メトリクス
実験結果:見えてきた現状と課題

38種類のLMMsを評価した結果、以下の重要な発見が得られました:
基本的な文字認識は高精度
多くのモデルが80%以上の精度を達成
空間的認識に課題
テキストの位置特定で著しい精度低下
特に複雑なレイアウトでの性能が不安定
構造的理解の限界
表やグラフの解析で苦戦
数学的推論タスクでの低パフォーマンス
まとめと今後の展望
OCRBench v2の評価結果から、現状のLMMsには以下の改善が必要であることが明らかになりました:
特殊文字への対応強化
ドットマトリクス文字
数式や特殊記号
空間認識の精度向上
テキストの正確な位置特定
複雑なレイアウトへの対応
構造的理解の改善
表やグラフの正確な解析
数学的推論能力の強化
この研究は、LMMsの実用化に向けた重要な課題を明らかにするとともに、今後の研究開発の方向性を示す重要な指標となっています。特に、実世界のアプリケーションでは、単純なテキスト認識だけでなく、空間的理解や論理的推論が重要となることを示唆しています。
OCRの分野は依然として発展途上であり、今後もLMMsの能力向上と評価手法の整備が継続的に必要とされるでしょう。