
【論文瞬読】LLMバグ修正エージェントの実力を徹底解析!7つのトップシステムの比較研究

こんにちは!株式会社AI Nestです。近年、LLM(大規模言語モデル)を活用したバグ修正システムが注目を集めています。従来の自動バグ修正は精度や適用範囲に限界がありましたが、LLMの登場により、より柔軟で高度な修正が可能になってきました。今回は、最新の研究論文から、7つのトップシステムの実力を徹底解析した結果をご紹介します。
タイトル:An Empirical Study on LLM-based Agents for Automated Bug Fixing
URL:https://arxiv.org/abs/2411.10213
所属:Bytedance, Bytedance & Peking University
著者:Xiangxin Meng, Zexiong Ma, Pengfei Gao, Chao Peng
この研究の特徴は、商用システムとオープンソースシステムの両方を同じ基準で評価し、それぞれの長所短所を明らかにした点にあります。

評価環境:SWE-bench Lite
SWE-bench Liteは、実際のGitHubリポジトリから収集された300のバグ修正タスクを含むベンチマークです。このベンチマークの特徴は、実世界のバグ修正シナリオを忠実に再現している点にあります。具体的には、11の主要なPythonリポジトリから収集された実際のGitHubイシューとプルリクエストに基づいています。
評価の範囲を現実的なものにするため、単一ファイルの修正に限定し、最大3つまでの編集箇所という制限が設けられています。また、イシューの説明には最低40単語以上が必要とされ、問題の十分な説明が含まれていることを保証しています。修正の正確性はユニットテストによって検証され、さらに人手による確認も行われています。
システム概要
本研究で分析された7つのシステムは、それぞれ特徴的なアプローチを採用しています。
商用システムの代表格であるMarsCode Agent(Bytedance)は、コード知識グラフとソフトウェア解析技術を組み合わせた先進的なアプローチを採用しています。このシステムの特徴は、バグの再現から検証までを自動化している点にあります。
一方、Honeycombはより直接的なアプローチを取り、LLMにファイル表示・編集ツールを提供し、すべてのイシューでバグの再現を試みます。この徹底的な再現戦略が、高い修正成功率につながっています。
Gruはワークフローベースのアプローチを採用し、LLMによる段階的な意思決定を特徴としています。Alibaba Lingma Agentは、モンテカルロツリー探索とコード知識グラフを組み合わせることで、より広範なコンテキストの理解を可能にしています。
オープンソースシステムでは、AutoCodeRoverがスペクトラムベースの欠陥特定とソフトウェア解析技術を組み合わせた独自のアプローチを取っています。Agentless + RepoGraphは、コード知識グラフを活用した関連コード検索機能を提供し、Agentlessは2段階のワークフローと多数決による最終パッチ選択という特徴的な手法を採用しています。
パフォーマンス分析

パフォーマンス分析の結果、システム間で興味深い差異が明らかになりました。最も高い性能を示したのはMarsCode Agentで、39.33%(118件)の問題を解決することができました。続いてHoneycombが38.33%(115件)、Gruが35.67%(107件)と続き、他のシステムは27-33%の解決率を示しました。
特筆すべきは、300件の問題のうち、36件はすべてのシステムが解決できた一方で、132件はどのシステムも解決できなかった点です。この結果は、イシュー記述の質や、スタックトレース、エラーメッセージの具体性が解決成功率に大きく影響することを示唆しています。
興味深い例として、django-13660のケースでは、イシュー説明の提案が誤った方向に修正を導いてしまい、典型的な失敗例となりました。このケースは、イシューの記述品質が修正の成否に大きく影響することを示しています。
Fault Localization性能
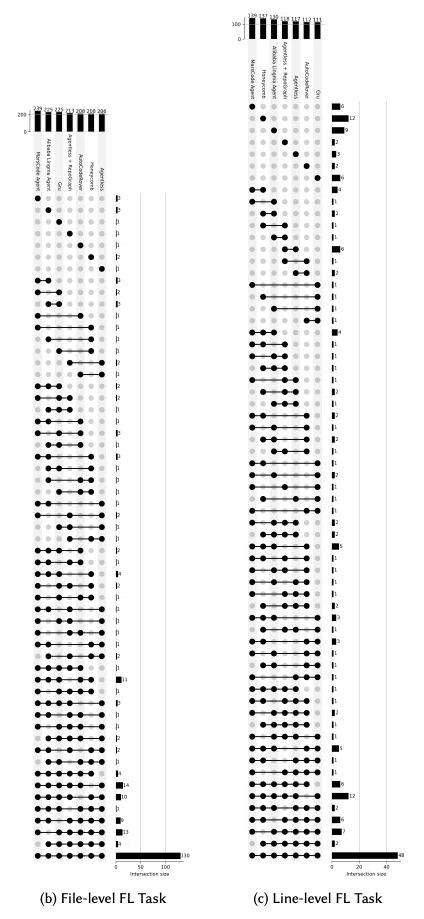
Fault Localization(バグの位置特定)の分析では、システム間で異なる特性が見られました。ファイルレベルの特定では、MarsCode Agentが239件の成功を達成し、最も低い性能のシステムでも206件を特定できました。これは、ファイルレベルでの特定が比較的容易であることを示しています。
一方、より細かいライン級の特定では、システム間で大きな性能差が見られました。特にHoneycombは65.9%という高いヒット率を示し、ライン級の特定精度と修正成功率に強い相関があることが明らかになりました。
バグ再現能力の分析

バグ再現機能の分析では、システムによって大きく異なるアプローチが観察されました。Honeycombはすべてのケースで再現を試みる徹底的なアプローチを取り、MarsCode Agentは70.3%のケースで再現を実施しています。一方、AutoCodeRoverは42.4%、Alibaba Lingma Agentは12.1%と、より選択的なアプローチを採用しています。
興味深いことに、24件のケースでは再現が解決の鍵となりました。適切なデバッグ情報の追加が、バグの特定に決定的な役割を果たすケースが多く見られ、再現機能の重要性が確認されました。
実装上の教訓
この研究から、LLMベースのバグ修正システム実装において重要な教訓が得られています。プロンプトの適切な設計や段階的な推論の導入、効果的なコンテキスト管理が重要であることが明らかになりました。
システム設計においては、モジュールの適切な分割、フィードバックループの設計、エラー処理の堅牢性が成功の鍵となります。また、複数の検証方法を組み合わせた段階的な確認プロセスの重要性も示されました。
まとめと今後の展望
本研究は、LLMベースのバグ修正システムの現状を包括的に分析し、今後の発展に向けた重要な知見を提供しています。特に、LLMの推論能力向上、バグ関連情報の正確な特定能力の強化、コンテキスト理解の深化が重要な改善点として挙げられます。
システム設計の観点からは、エージェントフローの改善、より精密なライン級のFault Localization、再現機能の選択的活用が今後の課題となります。また、スケーラビリティの確保や実行時間の最適化、信頼性の向上も重要な課題です。
将来的な研究の方向性として、コード変更の視覚化や実行トレースの解析、メトリクスの統合といったマルチモーダル情報の活用が期待されます。また、複数エージェントの連携や人間との効果的な協働、知識の累積的な活用も重要な研究テーマとなるでしょう。
評価方法についても、より多様なケースの収集や実世界での有効性検証、長期的な性能追跡の必要性が指摘されています。
この分野は急速に発展を続けており、商用システムとオープンソースシステムの両者の長所を活かした新しいアプローチの登場が期待されます。実務での活用を検討する際は、各システムの特徴を理解し、用途に応じて適切なものを選択することが重要となるでしょう。